
生まれて初めて買った日傘体験と、ちょっとだけエンジニア視点の話

こんにちは。すうちです。
今年の夏の暑さは異常ですね。
毎年言っているかもですが、年々酷くなってる気もします。そんな暑さに耐えかねて、今年ついに日傘を買いました。
今回は、そんな日傘に関する話です。
---
タイトル画像:春田みつきさん
生まれて初めて日傘を買ってみた
そもそも日傘とは
今まで晴れの日に使う日除け用の傘程度の知識しかなく、日傘についてよく知りませんでした。
普通の雨傘は撥水性の生地が張ってあるだけですが、日傘の場合、紫外線(UV)カットのコーティングや遮光性の生地(ポリウレタンなどの素材)が裏側にあったりして、その効果を実現しているそうです。
こちらに、私のような素人にも分かりやすい説明が書いてありました。
今回買った日傘
最近は噂で聞いてた日傘男子!?も増えているのか、立ち寄った幾つかのお店でも男性が使いやすい色柄やデザインの商品が大体3〜4種類は置いてありました。
今回、私はGゼロポケット晴雨兼用を買いました。価格は3,850円。
個人的な決め手は、
・通常の傘(雨用)でも使える
・スマホより軽い(約99g )
・UVカット率99%以上
などです。
たまたまお店で見かけて(一般的な日傘仕様や相場など事前調査せず)衝動的に買ってしまいましたが、他にネットショップでも買えるようです。
実際に使ってみてどうか
直射日光のダメージを避けれる
日傘のメイン機能ですが、やはりこの効果は大きいです。
先週試しに通勤途中に比較のため直射日光も浴びて試しましたが、数十秒ほどで「うわーきつい…」と日傘なしでは耐えられない身体になってしまいました。今年の夏は、太陽を克服できなかった鬼滅の刃の『無惨』の気持ちがよく分かる。。。
体感2〜3度は涼しい
直射日光を避けられるのと遮光効果で気持ち涼しさも感じられます。特に少し風がある時は、山の湖畔や森の日陰を歩くような感覚もありました(あくまで個人の感想です、多少オーバーに例えてます…)。
炎天下やアスファルトの道路は効果減
日傘購入に至ったのは、今年の暑さ対策で前から考えてたからですが、購入当日炎天下を歩いて、帰りはこの暑さを体験したくないと即決しました。
今までは冷感タオルと帽子で暑さ対策してましたが、いつもの通勤は最寄り駅まで30分歩くと帽子は汗で蒸れたり、タオルは濡れた後の扱いに困るのもあって日傘に移行しました。
ただ、日傘を購入した日は、真昼の14時頃の一番暑い時間帯でアスファルトの照り返しや空気も熱を帯びていて、その時は日傘の効果をあまり感じられませんでした。
1週間使ってみた今は効果も感じられて、個人的に買って良かったと思います。
ちょっとだけ、エンジニア視点の話
これだけだと「この夏、日傘を買いました…もう日傘なしでは生きられない身体になってしまいました」という話で終わってしまうので、市販の日傘の差異や相場を後追いで調べました。
購入した日傘がこの界隈でどういう立ち位置にいるか?お得だったのか否か見てみたいと思います。
日傘データを集める
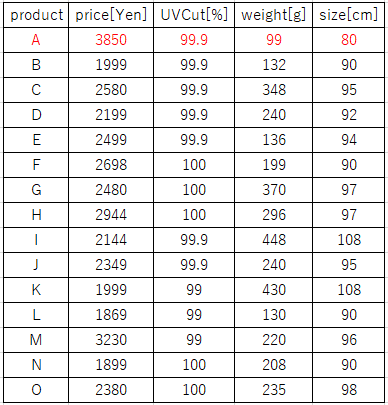
ネットから拾ってきた日傘の情報です。
比較のため、同じような折り畳み日傘で商品の数値が明確に書いてあるものを幾つか集めました。今回購入した商品は一番上の赤字です。
Pythonで相関を見てみる
このくらいのデータなら、わざわざプログラムで読まなくてもエクセルで計算した方が早いですが、無理やりPythonでもやってみます。
上記のcsvをPandasで読んで、DataFrameの相関を使いました。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import os
path = r'D:\note'
file = '230730_Parasol.csv'
# ファイルパスの設定
file_path = os.path.join(path, file)
# csvy読み込み、DtataFrame変換
df = pd.read_csv(file_path, sep=',')
# 相関計算
df_corr = df.loc[:,'price[Yen]':'size[cm]'].corr()
print('df_corr:', df_corr)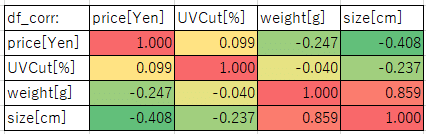
パラメータとデータ数が少ないのでなんとも言い難いですが、傘の大きさ(直径)と重さに何かしら相関があるのは出ています。
平均値や中央値など見てみる
これも目視やエクセルで確認できますが、pythonで統計情報(最大、最小、平均)も見れます。
# 統計値出力(数値)
for key, df_col in df.items():
# 文字列情報はスキップ
if key == 'name' or key == 'product': continue
# 統計値計算
vmax = df_col.max()
vmin = df_col.min()
vave = df_col.mean()
vmid = df_col.median()
print(f'{key} \t max:{vmax:.1f}, min:{vmin:.1f}, average:{vave:.1f}, median:{vmid:.1f} ')DataFrameの統計計算の結果です。

ちなみに、UVカット99%以上は凄いと思ってましたが、全部そうだし何なら100%もありこれは日傘界では当たり前なんだと知りました。
一応、見える化してみる
# 統計値出力(散布図)
for keys in [('product','price[Yen]','weight[g]'), ('product','price[Yen]','size[cm]')]:
# キーとDataFrame値取得
p_key, y_key, x_key = keys[0], keys[1], keys[2]
p_list = df[p_key].values
y_list = df[y_key].values
x_list = df[x_key].values
fig = plt.figure(figsize=(4,6), dpi=100)
# タイトル設定
plot_title = f'{y_key} vs {x_key} @ Parasols'
plt.title(plot_title)
# Y,X軸の値取得
for product, x, y in zip(p_list, x_list, y_list):
# マーカー情報指定(Aのみ)
mark = '*' if product == 'A' else 'o'
# 散布図設定
plt.scatter(x, y, label=product, marker=mark)
# Y/X ラベル設定
plt.ylabel(y_key)
plt.xlabel(x_key)
# 凡例設定
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1.1), ncol=1)
# 描画
plt.show()matplotlibでグラフにしました。

購入した日傘は、価格や重さ、サイズ分布を見る限り、かなり特異な位置にあると分かります。軽さと価格はこの中で一位。(軽い分?)傘の直径サイズは断トツで小さい。
もう少し調べて買っても良かったかもしれません。。。
最後に
先日「地球温暖化から沸騰化の時代到来」とのニュースがありました。
今までは人目を気にして日傘は選択してませんでしたが、そうも言ってられず身体の暑さ対策を優先したいと思っています。
皆さんも体調管理にお気をつけください。
最後まで読んで頂き、ありがとうございました。