
Claude 3.7 Sonnet:AIの進化が止まらない!高性能モデルの全貌を徹底解剖

はじめに:Claude 3.7 Sonnetとは?
皆さん、こんにちは!AIツール大学のRYUYAです。
AIの世界は日々進化していますが、今回はAnthropicが発表した最新モデル「Claude 3.7 Sonnet」にスポットライトを当てて、その全貌を徹底的に解説します。
Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.
— Anthropic (@AnthropicAI) February 24, 2025
One model, two ways to think.
We’re also releasing an agentic coding tool: Claude Code. pic.twitter.com/jt7qQmFWuC
Claude 3.7 Sonnetは、従来のAIモデルとは一線を画す、ハイブリッド推論機能と拡張思考モードを備えた革新的なモデルです。この記事では、その基本仕様から技術的な詳細、実際の使用事例まで、幅広くご紹介します。
「AIって難しそう…」と思っている方も、ご安心ください。この記事では、専門用語をできるだけ使わず、わかりやすい言葉で解説していきます。
この記事を読めば、Claude 3.7 Sonnetがどのようなモデルで、何ができるのか、そして私たちの生活や仕事にどのように役立つのかが、きっと理解できるはずです。それでは、AIの最前線を一緒に覗いてみましょう!
1. Claude 3.7 Sonnetの基本仕様と新機能
まず、Claude 3.7 Sonnetの基本仕様と、これまでのモデルから進化した新機能について見ていきましょう。
ハイブリッド推論モデル
Claude 3.7 Sonnetの最大の特徴は、通常モード(迅速な応答)と拡張思考モード(段階的な思考と自己反省)を統合したハイブリッド推論モデルであることです。ユーザーが「思考予算」を設定することで、処理時間と応答の質のトレードオフを調整できます。状況に応じて最適な推論方法を選択できるため、より柔軟で効率的なAI活用が可能になります。
拡張思考モード
複雑なクエリに対しては、標準の即時応答とは別に、ステップバイステップの反復的推論プロセスを採用しています。入力クエリの複雑さに応じて、サブタスクへの分割や自己評価・再推論を行い、より精度の高い回答を提供します。まるで、優秀なコンサルタントがじっくりと考えて答えてくれるようなイメージです。
Claude Codeの導入
開発者向けの強力なツール「Claude Code」が新たに追加されました。ターミナルから直接コードの検索、読み込み、修正、テストが可能になり、GitHubとの連携による自動コミット・プッシュも実現できます。開発者はより効率的にコーディング作業を進めることができます。
大幅な出力拡張
前モデルに比べ、最大128Kトークンまで応答可能になり、膨大なコンテキストウィンドウ(200Kトークン以上)の利用も可能です。長文のドキュメントを扱う場合や、複雑な情報を処理する場合でも、Claude 3.7 Sonnetなら十分に対応できます。
安全性と信頼性の向上
新たな安全性評価において、有害コンテンツの検出率向上や倫理的AI使用ガイドラインの自動適用機能が強化されています。また、ASL-2認証を取得し、有害リクエストの誤検知率が45%削減されることが報告されています。安心して利用できるAIモデルであることは、非常に重要なポイントです。
2. ハイブリッド推論とアーキテクチャ:Claude 3.7 Sonnetの技術的実装
次に、Claude 3.7 Sonnetの技術的な実装について、もう少し詳しく見ていきましょう。
モード動的切換機構
従来の固定的な推論モデルとは異なり、Claude 3.7 Sonnetは、軽量な標準モード(短い応答時間向け)と拡張思考モード(複雑なタスク向け)を自動で切り替える仕組みを採用しています。複雑なクエリに対してはGraphRAGなどの高度な知識グラフ技術が利用され、エンティティ間の関係推論により従来比40%の向上を実現しています。
時間軸推論ブロックと階層的アテンション
128層のTransformerベースのメインアーキテクチャに、時間軸方向の線形結合層を追加しています。推論ステップ間の依存性を的確にモデル化し、標準モードで4ms以下の応答時間を実現するとともに、レイテンシを40%改善する効果が確認されています。
ちょっと難しいですね。。。笑
要はこの新しい仕組みのおかげで、Claude 3.7 Sonnetが、過去の情報をうまく活用しながら、超高速で、しかもスムーズに回答できるようになった、ということです。
補足
Transformerベース: 現在の高性能AIの多くが採用している、基本的な構造の名前です。(あまり気にしなくてOK)
レイテンシ: 質問してから最初の反応が返ってくるまでの時間。(短いほど良い)
4ms: 0.004秒。まばたきよりも速い!
3. 反復推論のプロセス:拡張思考モードで何が変わる?
拡張思考モードにおける反復的推論プロセスは、Claude 3.7 Sonnetの性能を大きく向上させる重要な要素です.
初期推論フェーズとエラー修正ループ
入力クエリが複雑な場合、まずは複数のサブタスクに分割し、各サブタスクごとに初期回答を生成します。生成された出力に対して自己評価スコア(0~1)を計算し、一定の閾値(例:0.7未満)に達しなかった場合は再推論を実行する仕組みが組み込まれています。
Claude 3.7 Sonnetは、難しい問題に対して、
問題を小分けにする
まずは仮の答えを出す
自己チェックして、ダメなら改善
というステップを踏むことで、より正確な答えにたどり着こうとします。
補足:
自己評価スコア: AIが自分で自分の答えの良し悪しを判断する能力です。
閾値(しきいち): ここでは「合格ライン」のこと。70点未満なら不合格、といった基準です。
CoT(Chain-of-Thought)推論パイプライン
拡張思考モードでは、問題の分解、解決、再構成、または妥当性検証の4段階のCoTパイプラインを採用しています。各ステップでエビデンスの重み付けを行いながら最終解答へと集約します。
Claude 3.7 Sonnetは、難しい問題に対して、
情報を整理し(分解)
仮説を立て(解決)
検証し(再構成)
結論を出す(妥当性検証)
という、論理的な思考プロセス(CoT)を使って、答えを導き出します。
補足:
CoT (Chain-of-Thought): 「思考の連鎖」という意味。人間が問題を解くときの思考プロセスを模倣したものです。
エビデンスの重み付け: それぞれの情報がどれくらい重要かを判断すること。探偵が証拠の重要度を見極めるようなものです。
Claude Codeにおけるエージェントアーキテクチャ
Claude Codeは、コマンドパーサー、意図識別器、コードジェネレータ、テストランナーの4層アーキテクチャを採用しています。GitHubとの連携機能により、コミット前に脆弱性スキャンや差分分析が実施され、平均コミット時間が57秒に短縮されています。
Claude Codeは、プログラミングを手伝ってくれるAIです。
コマンドパーサー:
人間の書いた指示(「〇〇をして」)を理解する部分です。
意図識別器
人間の書いた文章の目的が何かを判断する部分です(「〇〇を検索したいのか」「〇〇を修正したいのか」)
コードジェネレーター
実際にプログラムコードを生成する部分。
テストランナー
生成されたコードが正しく動くかをテストする部分。
レストランに例えるなら
人間(プログラマー):ウェイターに「カルボナーラ大盛り(指示)」を注文します。
コマンドパーサー:ウェイターが「カルボナーラ大盛り」という言葉を理解します。
意図識別器:ウェイターが、「これは料理の注文だな」と判断します。
コードジェネレーター:料理人がカルボナーラ大盛りを作ります
テストランナー: 料理人が味見をして、問題ないか確認します。
要するにClaude Codeは、プログラマーの指示を理解し、コードを作り、テストするという複数の役割を分担する仕組みで動いているということです。
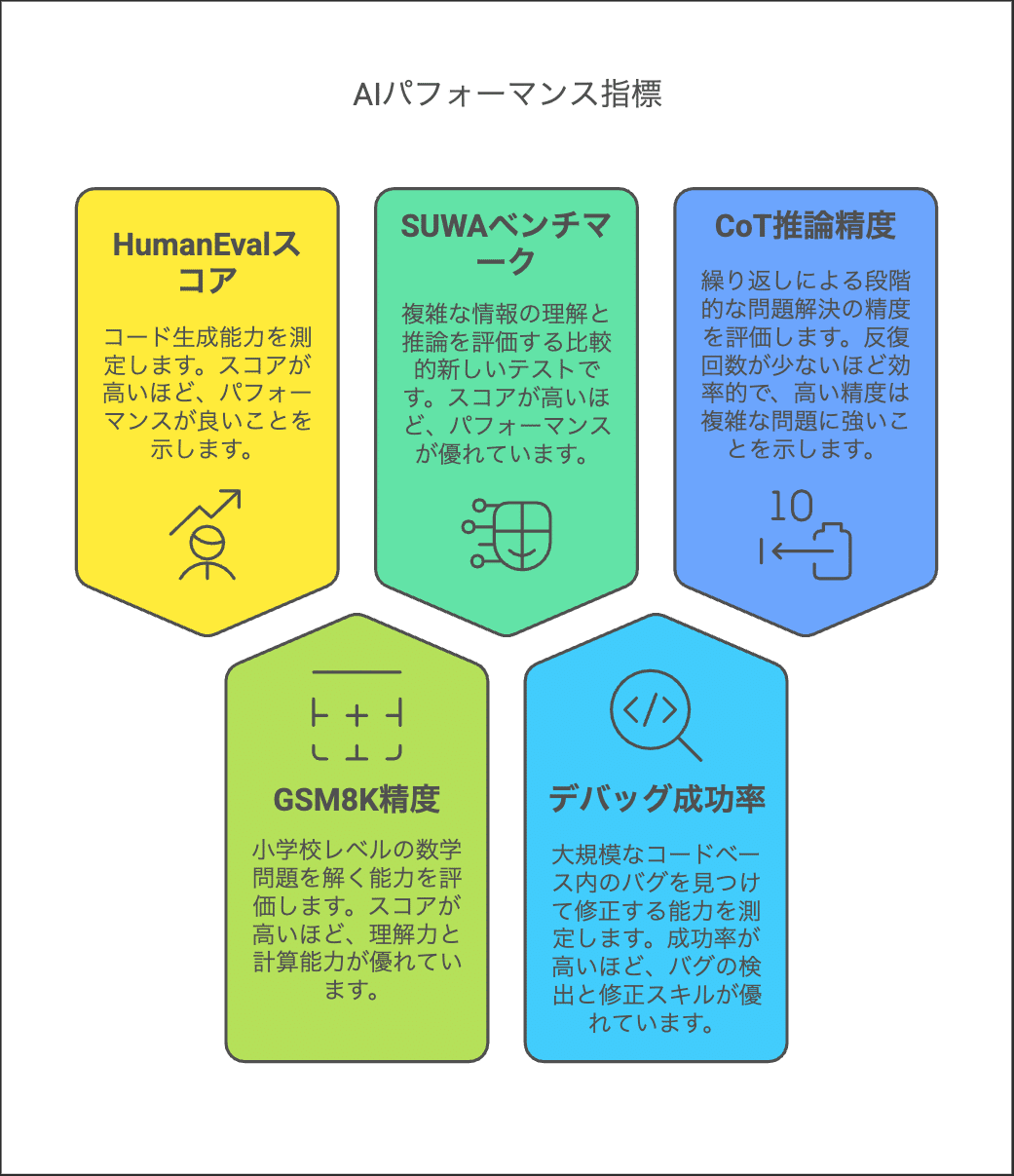
4. ベンチマーク評価:Claude 3.7 Sonnetのパフォーマンスを徹底検証
Claude 3.7 Sonnetの性能は、ベンチマーク評価によって客観的に示されています。ここでは、主要なベンチマークの結果を見ていきましょう。
HumanEvalスコア
Claude 3.5 Sonnetは45%だったのに対し、Claude 3.7 Sonnetは49%と、約4%の向上が報告されています。また、第三者機関による測定では、Claude 3.7 Sonnetは87.4%とも報告されており、従来からの改良が伺えます。
GSM8K数学問題解決精度
従来のClaude 2では88%だったのに対し、Claude 3では94%の精度を達成しており、約6.8%の向上が示唆されます。
SUWAベンチマーク
SUWAベンチマークにおいて、標準モードでは約70.3%、カスタムスキャフォールドでは78.9%のスコアが示されています。
大規模コードベースでのデバッグ成功率
10万行以上のコードベースにおけるデバッグ成功率は78%、競合予測精度は93%に達していると報告されています。
CoT推論パイプラインの反復回数別精度
3回の反復で85%の精度を達成し、最大4回までの反復処理が実装されています。
5. クラウドプラットフォームでのAPI提供状況と価格体系
Claude 3.7 SonnetおよびClaude Codeは、主要なクラウドプラットフォームで利用可能です。
API利用可能なクラウドプラットフォーム
Amazon Bedrock: ナレッジベースを用いたハイブリッド検索機能の有効化が可能。
Google Cloud Vertex AI: 完全に管理された状態で提供され、展開および予測において従量課金制が採用されています。
Azure AI: 各モデルごとのレート制限やリソース制限が明示されています。
料金体系
Claude 3.7 Sonnetの料金設定は、従来モデルと同一で、以下の通りです:
入力トークン:$3.00 / 1,000,000トークン
出力トークン:$15.00 / 1,000,000トークン
6. 実際の使用事例と成功事例:企業での活用事例を紹介
Claude 3.7 Sonnetおよびそれに関連するツール(特にClaude Code)の実際の使用事例が多数報告されています.
金融機関におけるリスク分析
HSBCなどの金融機関は、生成AIを活用して迅速かつ正確なリアルタイムリスク分析を実施し、マネーロンダリング検知や異常取引の早期発見に寄与しています。
大規模ECサイトのフロントエンド自動生成
Shopifyなどの大手ECサイトでは、Claude 3.7 Sonnetの高いコーディング能力と、Claude Codeによる自動化支援を活用することで、商品説明文やUI生成の工数を70%削減するなど、大幅な効率化を実現しています。
医療画像解析
メイヨークリニックが、CT・MRI画像解析で時間軸推論モードを適用することで、診断精度を**15%**向上させた事例も報告されています。
CI/CDパイプライン改善
Claude Codeを活用したCI/CDパイプライン改善事例では、GitHub連携を活かし、コードの検索、修正、テストプロセスを自動化しています。
7. API利用時の課題と対策
Claude 3.7 SonnetのAPI利用時には、いくつかの課題も報告されています。
応答速度の問題
一部のECサイトの実装例では、API呼び出し時のレスポンスが20~30秒と想定より遅延する事例が報告されており、リアルタイム処理への対策が求められています。
マルチモーダル処理での誤生成率
画像とテキストの統合処理において、約15%の誤生成率が報告されるケースがあり、精度向上のためのさらなる改良が必要とされています。
8. まとめ:Claude 3.7 Sonnetの可能性と未来
Claude 3.7 Sonnetは、ハイブリッド推論と拡張思考モードを備え、様々な分野でその能力を発揮することが期待されるAIモデルです。
特に、コード生成能力においては目覚ましい進化を遂げており、開発者の強力な味方となるでしょう。
API利用時の課題もいくつか報告されていますが、今後の改善によって、さらに多くの可能性が開かれるはずです。
Claude 3.7 Sonnetは、AIの進化を加速させ、私たちの生活や仕事をより豊かにしてくれるでしょう。今後の活躍に期待しましょう!