
大企業AI活用の第一原理であるData as a Productと、その産物であるData Productsを支配するための実践ノート

はじめに
2025年が2ヶ月経過したが、依然として大企業でのAI活用に関する話題は尽きない。今年のJDMCではData as a Productが主題となった。昨年が「生成AIにはデータマネジメントが大事だ!」というAIとデタマネお互いの領域の接続に留まっていたことと比較すると、今年は「AIを現実的にワークさせる」という実効性の観点に話題が映っているようだ。大企業でのAI活用はようやくプラトー、具体論にフォーカスが当たる非常に良い兆しだと見れる。
今日は、欧米の動きから5年遅れて日向に踏み出すこととなった、Data as a Productについて書いてみたいと思う。特に、DX部門の現場で働く読者の皆さんが企業内でData as a Productの価値を啓蒙し実践的な道筋を立てる助けになるような記事にしたい。
Data as a Productの歴史的な背景
Data as a Productは、Zhamak Dehghaniが2020年に思想展開したData Meshの中心的な原則として始まった。Data Mesh自体はデータマネジメントの分散管理メソドロジーの一種で、Team Topologyに影響を受けていると言われる。Team Topologyで中心となるのはConway's law(ソフトウェア提供者が働く組織構造が、生み出すソフトウェア構造を規定しているよ)という理論で、Data Meshでは "ソフトウェア提供のみならずデータ提供もそうである "という仮説のもと「データ提供に理想的な組織構造」を定義し、「その組織がいかにしてデータ提供のQCD(品質、コスト、納期)を担保できるか」を論じている。
一般論のTo Beとしては分かるが、組織構造は過去のビジネスを反映する(Path Dependent)ので、NetflixみたいにBy Defaultで組織構造やデータ構造を設計できるメガ・スタートアップを除いて、Data Mesh自体は実現が非常に難しく、特に伝統的なビジネスへの実効性に関しては諸説ある(多くの場合追及のROIが合わない、とも言われる)。
他方で、Data as a Productは普遍的な概念である。Data as a Productはつまり「QCDを担保したいなら、データを製品のように扱いましょう。製品であるならば、当然求められることは分かるよね?」ということであり、誰が管理するかを一旦無視すれば(Data Meshではこれを分散構造で管理してスケールさせようということだが、) 非常に納得感がある原理である。
Data as a Productの結果生まれてくる産物はData Productsと呼ばれる。ちなみに、紛らわしい"Data Products"のもう一つの解釈があり、こちらはBI Dashboardから自動運転車までも含む「データが組み込まれた製品」という意味で、少し系譜が異なる。今日はData as a ProductにおけるData Products「製品としてのデータ」にフォーカスして説明する。
Data Productsの要点・構成要素
Data as a Product文脈でのData Productsは様々なところで様々に語られている。まずGartnerによると、以下である。
A data product is essentially a set of data, metadata, semantics, and templates. They are curated and maintained to be immediately useful for specific business objectives. This principle ensures trustworthy, high-quality data that drives informed decisions and strategic insights.
【独自邦訳】Data Productsの本質は、データ、メタデータ、セマンティクス(意味情報)、およびテンプレート(活用ナレッジ)からなるワンセットです。これらは特定のビジネス目標に対して即座に活用できるよう、厳選・管理されています。この原則により、信頼性が高く高品質なデータが確保され、意思決定や戦略的なインサイトの創出を支援します。
他にも見てみる。Forbesによると以下。
Data products are defined as live, refined, fully governed and ready-to-use data assets that are instantly discoverable, contextualized, trustworthy and reusable for many use cases. Put simply, data products allow organizations to reuse data across a variety of use cases to save costs and time.
【独自邦訳】Data Productsとは、リアルタイムで管理・洗練され、完全にガバナンスされた、すぐに活用可能なデータ資産を指します。これらは瞬時に検索でき、コンテキストが明確で、信頼性が高く、さまざまな用途で再利用できるよう設計されています。簡単に言えば、Data Productsは、組織がデータを多様なユースケースで再利用できるようにすることで、コストと時間を削減する仕組みです。
GartnerとForbesが記載する内容を独自にまとめると、こんな感じに定義できるだろう。
Data itself(データそれ自体)
Metadata & Knowledge(メタデータとナレッジ)
Data Interface(再利用のための取得手段)
に分類できる。まずデータが必要で、利用するためにデータを形容するメタデータやナレッジ情報が必要で、そして再利用性を高めるために何かインターフェースを切る。これでデータ提供のQCDが飛躍します、ということだ。
何故AI活用でData Productsが求められるのか
冒頭にAIにはData as a Productの原理(とその成果物としてのData Products)が重要と書いたが、何故なのか。Gartner Top 10 Strategic Technology Trends for 2025 にあるように、大企業AI活用といえば、昨年から特にAgentic AIが世界を賑わせている。Agentic AIにより、AIが計算と分析のような意思決定の補助作業だけではなく、大企業で社員の大半が日々9時5時で行なっているなんらかの「実際の業務」の実行を自律的に行うことができるようになる。Agentic AIはSaaSなどのTool(道具)へのアクセス権限を持ち、過去プロンプトに入力されたMemory(記憶)を参照することで、人間のそれのように業務を行う。
あとはRetrieval(検索)で記憶を補完しましょう、ということだ。

RetrievalにおいてData itselfとData Interfaceが必要なのは直感的にわかる。ずっと前から、データウェアハウスやデータ仮想化技術によってデータを整備しインターフェースを切る、というのは取り組まれてきた。しかし、なぜ今になって敢えてData Products、特に従来カバーしていなかったMetadata & Knowledgeが必要なのだろうか。
少し具体例で考えてみる。例えば、「四半期末の営業マネジャーによる外勤営業の人事評価業務」であれば、Salesforceから実績(こなした商談件数、提案進捗の数、受注に至った商談件数、それぞれの金額など)を参照し、それぞれの目標値と掛け合わせて達成率や増加率を計算し、最終的にS評価をつけるのか、C評価をつけるのかを決定し、評価コメントとともに記載する。人事評価システム、例えばSuccess Factorsにドラフトを保存する、とかだろう。
この業務を行う際、前提となるメタデータとナレッジが必要ではないだろうか。メタデータであれば、例えば「何を持って商談化とみなすのか。マネージャーがクオリファイしてない案件も商談とみなすのか。」「商談フェーズ3、の定義は何か。去年Salesforceの大規模工事をしたが、前の定義との違いは何か。」「受注金額はARRなのか、粗利なのか。ランプアップ期間は未達成に加味されるのか。」「受注の定義は契約書受領日なのか、あるいは利用開始日なのか。」
ナレッジであれば、「S評価には売上達成率が一番響くのか、それとも獲得粗利の大きさか。」「営業が30人いるが、相対評価なのか絶対評価なのか。」「入社15年で受注10社と、入社3年で受注10社だとどう相対評価するか」など。
人間が業務を行う際は、これらの情報を意識的 / 無意識的に加味して業務をしており、自分の記憶を遡ったり、知ってそうな人に聞いたりしながら、遂行する。これを構造的に記録しましょう、というのがメタデータとナレッジがなわけだが、これがないとAgentic AIは「よくわかっていない」評価草案を作って出してくることになる。いくらLLMの性能が良くなろうが、メタデータとナレッジなくしてはAIは業務貢献の質を上げることができない、ましてや自走させようなんていうのは難しく、上司に都度判断を仰ぐインテリ無能が誕生する。
また、第1営業部の人事評価では売上を、第二営業部では粗利を重視して評価を行う、なども当然起こる。誰が何の業務を行うか(=一般的にユースケースと呼ばれる)によって、当然それに必要なメタデータやナレッジは異なる。つまり、同じSalesforceの同じデータを使うとしても、ユースケースによって必要なメタデータやナレッジは異なり、また無数(N:Nの関係)にあるのだ。
導かれる結論として、それぞれのユースケース毎に、データそれ自体、メタデータ、ナレッジを紐付けて管理しておくことが、Agentic AIが業務貢献を行うために必要だ、といえる。言わずもがな、これが従来と一味も二味も異なる、紛れもないData Productsである。

大企業でのData Products管理の難点と原因
じゃあData Productsやらを実践してみましょう、という話なのだが、大企業ではこれがやたら難しい。ほんとに難しい。なぜなのか。それは、先に説明したMetadata & Knowledgeを持続的に管理する難しさにある。
先の例を少し抽象化すると、そういったAI時代に重要なMetadata & Knowledgeは「業務や顧客に関する情報」と言い換えられる(※メタデータとナレッジというと、データベース構造などの「テクニカルメタデータ」に焦点が当たりすぎる場合があるが、ここでいうのは先に例で挙げたような「ビジネスメタデータ」と呼ばれるものに焦点を当てる)。
それらの情報は誰が持っているのか。もちろんIT部門(以下IT)やData Management Office(以下DMO、後ほど説明する)は持っていない。今まで事業成長を兼任しP/Lを作ってきた事業部門(Line of Business、以下LoB)が持っているのだ。ITやDMOが頑張って全件入力したら終わり!という類であれば極論は頑張ればOK、という話だがそうではない。頑張りたくても頑張れない、なぜなら知らないので。これがData Productsの管理が難しい最大の理由である、他は多分なんとかなる。
じゃあ、LoBに協力を仰ぎましょうか、となるが、そう単純ではない。彼らは多くの場合は営業部門であり、文字通り事業成長を直接的に牽引することがミッションである。本社部門が言い出した「ビジネスメタデータ」とやらには当然興味はない。お客様へ向き合う時間を増やすために営業の仕事でさえSales AssistantやPresalesに手伝ってもらって完遂しているのに、ビジネスメタデータの入力をわざわざ自分がやるの?である。
仮にLoBが営業部門でない場合も、例えばミドルオフィスやバックオフィス系の業務だった場合、そもそも彼らの多くはその領域の業務知見で食っている。ビジネスメタデータを自ら差し出すことは自分の食い扶持を減らすことと同義であり、協力してもらうのは非常に難しい。「Agentic AIが最終的にウチの仕事を奪うために、ウチがわざわざ協力しろと?」となりかねない。つまりData Products管理の難点は、組織構造的なサイロと利害対立が原因だ、と言い換えることができる。データの統合はデータベースを繋げば良いが、メタデータとナレッジの統合は「よく知らない他部門の野原課長」に丁寧にお願いすることが必要になる。野原ひろしみたいにとっつきやすい課長だと少しは気が楽だが、往々にしてそうとは限らない。

大企業でのData Products成熟への対策
だからData Productsは絶望的だ、という話ではない。ではどうするのか。ここからは対策立案と現場努力でその対策を実現まで漕ぎ着ける糸口を記載したい。要点は、サイロと利害対立を認識する、一旦DMOに知見を集める、LoBを巻き込み仕組み化する、ということ。観点を「組織・プロセス」「人材教育」「システム」、議論を「5年後」「今すぐ」に分けて整理してみる。
組織とプロセスの観点
これはDMBoKが詳しいが、大企業では最終的には連邦型と呼ばれるデータマネジメント組織・プロセスに落ち着くと言われている。端的に説明すると「事業側、本部側の両方にデータマネジメント能力があり、事業側は独自にData Products管理を行い、本部側は共通するポリシーやルール作りにより援助する」という構成になる。

しかしながらご想像の通り、一足飛びにそこに飛びつくのは難しい。あなたがDX部門の社員で、また事業部側にも本社側にもデータマネジメント能力がない場合、DX部門の近くにDMOを発足させData Products管理の初期的な業務を行い、誰のどんな業務がData Products管理をスケールさせるには必要か、を考えていく他ない。
発展的には、そこで揉んだ内容を整理しポリシーやルール化し、事業部側に展開・責任移譲していくという手順だ。
人材教育の観点
どういった専門性を、誰がどの順番でつけていけば良いのだろうか。大企業で最終的には、技術的な専門性(AIやデータサイエンス、データエンジニアリング)をLoBが持ち、ドメイン的専門性を反対にDMOが持つことが理想だ。それに加えて、そういった専門性が陳腐化しないように環流し続けることが重要である。
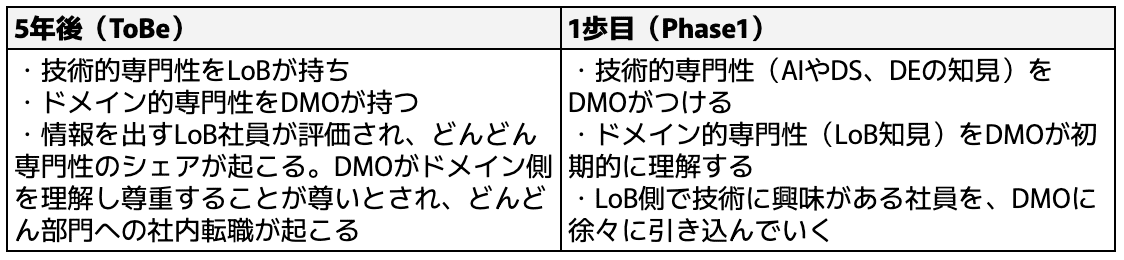
そしてこれもまた、一足飛びにはいかない。1歩目としては、まずDMOに所属する本社メンバーが技術的専門性を深め、また新規にドメイン的専門性へのキャッチアップを徐々に行なっていくことが良いだろう。そもそも技術的専門性に関しては、データサイエンティストとはいってもデータエンジニアリングに詳しいとは限らない。事業に関しても、自社のToC事業に詳しい人がToB事業にも詳しいとは限らない。なので、データ提供のQDCを高めるミッションで立ち上げったDMOメンバー達自身が、お互いから学び合って専門性を深めていく必要がある。同時に、机上の学習のみでは浅いので、実際に事業部で活躍し結果を出しているメンバーを徐々にDMOに引き入れていく。
いつの時代も先端技術に心躍る人がいる、これはITやDX部門だけではなく事業部にもいるだろう。また、事業部は今までの業務での課題や「こうあれば便利なのに」というフラストレーションを大量に持っている。その経験や知見が技術と融合することで解決しうるのであれば、今までやったことがなくても興味を持つ人はいるはずだ。
仕組みとシステムの観点
Data Productsの管理の要点は、先に述べたようにDataにMetadata & Knowledge、Data Interfaceを人間の手で紐づけることにある。これをプロフェッショナルなレベルで行うための専門ソフトウェアとして、データカタログといわれるものがある。DataとData Interfaceを紐付けるだけであればデータウェアハウスやデータ仮想化技術で良いが、Metadata & Knowledgeを運用するとなるとデータカタログが必要だ。データカタログの本質はそのコラボレーション性能であり、メールやTeamsでの一過的なExcelファイル授受では成り立ちきらない、事業部とDMOの継続的な共同業務(Program)に実効性をもたらす。

とはいっても、顔もよく知らない事業部の野原課長に、「これ買ったんで使ってみてください」みたいな話ではない。一歩目としては、先に述べた組織・プロセスの観点でData Productsの管理を託され、人材教育の観点でドメイン的専門性を学んでいるDMOチーム自身にて、データカタログを利用・運用してみるのが良い。これは単なるPoCではなく、DMOが自身のミッションを達成するための業務基盤の正式稼働を意味する。このステップを挟むことで、「何がこのシステムによる仕組み化の効用なのか」「具体的に何をどうやって事業部に協力して欲しいのか」が明確になり、信頼関係を毀損せずにData Products管理を進めることができるだろう。
どこから価値説明を始めれば良い?
「Data Productsについてなんとなくわかってきた。でもウチはデータ活用自体が進んでこなかったので、経営陣がこの概念の要点と価値を理解できるか分からない」そういった声が聞こえてきそうである。自分が所属している部門長ともクリスマス会でしか話さないのに、その上の経営陣にどうやってこの難しい概念を説明するんだ、、、(遠い目)
少し企業のお困りごと別(成熟度別)の説明方針を考えてみる。
データ活用の価値が経営に理解されない
そもそも、「横断データを二次活用することでどんな価値が生まれるか」について経営に詳細な理解がない場合。これは日本では特に自動車以外の製造業を中心としたBtoB企業、或いは営業が中心になる商社のような企業、に多い気がする。
こういった企業では、活用キラーユースケース探しの旅を行う。2025年時点では、活用キラーユースケースは、今までのデータ分析(Data Science)のテーマから探すのではなく、Agentic AIによる業務変革からテーマを探すのがおすすめだ。今や大企業のCEOはAIを今後どう使いこなすか、それにどう準備しておくか(AI Readiness)にやはり興味が高い。データ分析の時は「ああ分析ね、俺のKKD(経験・勘・度胸)の方が頼りになる」と心の底では思っていたCEOも、生成AIの登場によって「AIに備えないとマジで飲まれるかも」と思い始めている。
Agentic AIは「リスク許容度が高い業務」と相性が良いとされている。The Wall Streat Journal によると、コンタクトセンターやカスタマーサポート業務での活用が例に挙げられている。また、もっと始めやすいものとしては、従業員用の「Ask me anything」ボットがある。アドミ部門の業務負荷の削減が見込まれ、「AIとはどういうものか」が経営陣の目から見てわかりやすい。
DMOの価値が経営に理解されない
「AIにデータが必要」というのは既になんとなく正しそうな雰囲気がある言葉なので、その提供QCDを担保するDMOに対して価値を見出せない、ということはあまり聞かない。一方で、従来のIT出身者がトップの際には、それはIT部門ボールで良いのでは?(俺らデータ詳しいし、だってシステム作ったの俺らだよ?)というオブジェクションを喰らう可能性がある。
ロジックで言えば「このAgentic AIによるキラーユースケースを実現するには、利害対立する部門を跨いだデータ整備と提供が必要」で、「データ整備はITが行うが、データ提供のQCD担保を行うことにKPIを持つ組織が別で必要」だ、という話である。「これを欧米ではDMOと呼んでおり、利害対立が原因なので、既存のKPIを抱える現場に任せていても難しい。(ITはデータを守ることが責務なので、彼らにDMOを任せるのは難しい。)経営陣からの号令がないと何も始まらない。」ということを、経営陣に伝える必要がある。
Data Productsの価値が経営に理解されない
あえてData as a ProductsやData Productsという概念を具に説明する必要はない。しかし、DataとData Interfaceの整備だけでは(つまりデータウェアハウスにデータを統合するだけでは)想定しているAgentic AIのキラーユースケースは10年経っても実現しない、ということを理解してもらう必要がある。
つまり、Agentic AIのRetrievalにおけるMetadata & Knowledgeの重要性を、構図化して説明してあげることが重要だろう。「551のあるとき〜、551のないとき〜」みたいな感じで。メタデータのあるとき〜。
特に、「プロフェッショナルにAgentic AIを活用するならRetrieval対象がデータだけではインテリ無能が生まれるだけです。有能にするにはData Products(DataとMetadata & Knowledgeを紐づけること)を管理することが不可欠です」という立ち位置がわかりやすい?
2025年時点では、通信業や金融業、小売業など昔からデータを資産として活用してきた業界では、既にここら辺のフェーズにある企業も多いだろう。
データ(プロダクツ)カタログの価値が経営に理解されない
Day1ではデータ(プロダクツ)カタログの価値はだいたい理解されない。しかし、データ活用の価値に気づいており、DMOの価値に気づいており、Data Productsの価値に気づいている、そんな優良企業では「では、Data Productsの管理をスケールさせましょう!」というは自明である。ここまで来ていれば、このテーマを切り取って独立した経営マターにしなくても、「DMOの高度化をデータ(プロダクツ)カタログによって行いましょう」と言うことで既存のKPIベースで会話を始めることができる。
高度化を語るのであれば当然、DMOのKPI(事業部へのData Products提供 = Metadata & Knowlegeの整備)がなぜ上がりにくいか、まず構造的な問題を指摘する必要がある。案としては、「Data Productsの完成にはMetadata & Knowledgeが必要だが、Metadata & KnowledgeはDMOではなく各々のLoBや業務部にある。しかし彼らはMetadata & Knowledgeの提供に関して利益がない。なので、メールやTeams・或いは上司の同期など人脈を通じて頼み込むことしかできない。ここをシステムで仕組み化することで、DMOはHelpdesk的に抽象化され匿名化でき、LoBへの頼み込みを「業務」として意識変換できる。また、システムや仕組み上でやりとりされるので、Metadata & Knowledge 管理の履歴が残り、「新しい暗黙知」の発生を未然に防ぐ。」ということだ。
もし、あなたが担当としてデータ(プロダクツ)カタログの効用を信じており、他方でこれらの価値説明が通らないのであれば、裏の手としては戦略的モラルハザードの実行がある。百聞は一見にしかずではないが、人間やはり未知に対しての価値見積もりは難しい。なので、何か別の便利な理由にかこつけて一旦入れてしまい、後から価値説明のストーリーをボトムアップで組み上げるという戦術である。例えば、DMOメンバーの教育観点なんかをレバレッジし、データ(プロダクツ)カタログのスモールスタートを切る。それを使ってDMOでMetadata & Knowledgeの運用を小さく行い、「システムや仕組みがある世界とない世界で、DMOのKPI達成率がどう変動するか」を価値説明するための材料を集め、段階的な適用範囲の拡大を行うこともありうる。注意点としては、正攻法で行けるのならばその方が良い。過度にトラディッショナルな企業のための、最後の一手という位置付けに留める。
まとめ
一万字を越してしまった。今日はData as a Productとその成果物としてのData Productsについて、歴史的な背景から要点や構成要素、AI活用との交わり、Data Products管理の難点と原因、成熟への対策案と、明日から使える価値説明について、記載した。「Data Productsを支配するために」と見出しをつけたが、ここで語ったことは羅針盤のようなものにすぎず、本当に支配するための詳細はもちろん企業毎に違ってくる。専門家の助けのもと、自社で是々非々に考えていくことが必要だと思う。
日本の大企業でデータマネジメントに関わる現場の方にとって、少しでも有用な記事になれば幸いです。