
機能性表示食品の届け出約7千件を消費者庁のサイトからゲットする方法

「機能性表示食品、『根拠』に社員の論文のケース 『紅麴』サプリも」と題した記事を、朝日新聞デジタルで7月25日に配信しました。小林製薬の紅麴サプリ問題で注目される機能性表示食品の制度について書いたもので、内容をざっと説明すると、
京都大グループによると、各製品が健康効果の「根拠」とした論文には、有利な結果だけを強調した問題のあるものが多くあった。調査した32本の論文のうち、18本は特定の、とある医療専門誌に掲載されていた
各製品が健康効果の根拠とした「採用文献リスト」を、朝日新聞が消費者庁のデータベースから調べたところ、約7千件のうち半分以上が、この医療専門誌に載った論文を採用していた。しかもその割合はしだいに高まってきていた
紅麴がそうだったように、企業所属の研究者が自社製品について論文を書き、その論文が「根拠」となっていることもある。この医療専門誌のバックナンバーを調べると、約1700本の論文のうち6割超は、著者が製薬や食品などの会社勤めだった。割合は制度が始まった2015年以降に高まっていた
要するに、機能性表示食品の制度はたったひとつの、失礼ながらとくにメジャーとは言えない専門誌に相当程度寄りかかっていることが浮き彫りになった。専門家は「論文をすぐに載せたい企業の求めに専門誌側が応じる関係になっているようだ」「制度そのものに問題があった」とコメントしている
……というようなところです。
これまで私がやってきたデータ報道では、元からtidyに整形してあるデータを扱うケースがほとんどでした。今回のは自らデータを取りに行って、汚いデータを整形するというところが新たなチャレンジで、なかなか面白かったのです。
そこで、このnoteの記事では、消費者庁のデータベースをどうやって調べたか、かんたんに説明します(本来はコードを丸ごと公開したいところなのですが、記事ではふせている医療専門誌の名前がコード中に出てくるので、断念しました)。
採用文献リストは、各メーカーが消費者庁に届け出た書類のうち「機能性の科学的根拠」を示す「様式Ⅴ」という文書に記載されていて、ネット上でPDFが公開されています。たとえば小林製薬の「コレステヘルプa」という製品では、ここにあります。
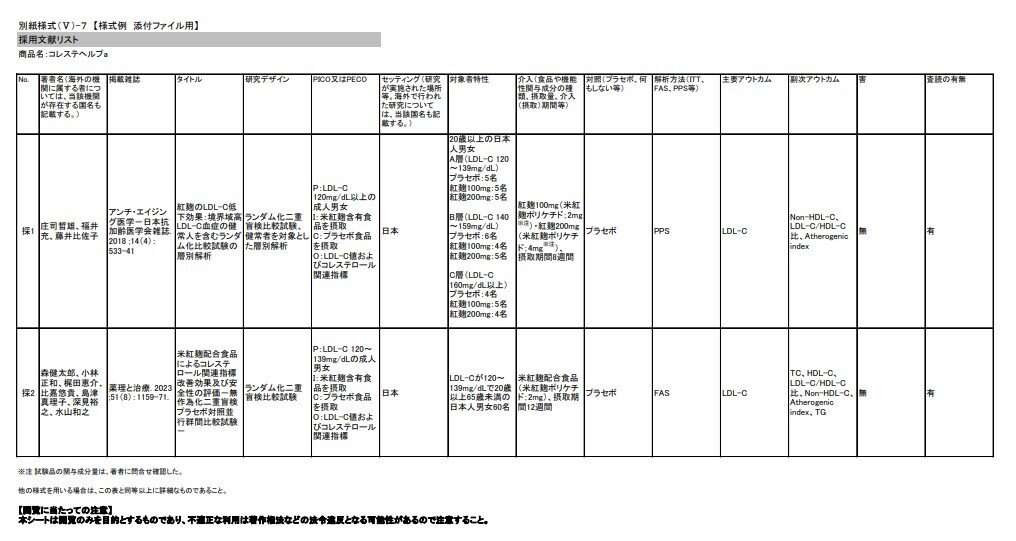
消費者庁のサイトから検索して製品を見つけ、「詳細」→「様式Ⅴ:機能性の科学的根拠」→「別紙様式(Ⅴ)-1~16の確認をされる場合はこちら→ファイル」というのを次々にクリックしていくと、このPDFにたどり着けます。ただ、この作業を全製品の届け出(8千件以上あります)についてやるのは、さすがにめんどくさすぎる。
ではどうするか。このURLをよく見てください。
https://www.fld.caa.go.jp/caaks/cssc06/youshiki5?yousiki5216File=G970%255CG970_youshiki5.pdf
「G970」という記号のようなものが2度、登場してます。実はこれ、コレステヘルプaの届出番号なのです。つまり、各製品の届出番号を同じ場所にはめこめば、各製品の科学的根拠を示す資料のURLがどんどん生成できる、というわけです。そして届出番号は、前述した消費者庁のサイトで全部をまとめたものがcsvファイルとしてダウンロードできるので、これを使えばいい。

こうやってURLを生成し、それぞれのURLにおかれているPDFを次々に読み込んで、「採用文献リスト」が載っているページをコピーしていくわけです。Rで書いたコードの中核は、こんな感じです(実際には、取得に失敗する例があるので、同じことを複数回繰り返して取りこぼしを減らすといった作業もやっています)。
library(tidyverse)
library(stringi)
library(stringr)
library(rvest)
library(xml2)
library(pdftools)
library(httr)
# 届出番号のベクトル
notification_numbers <- f_foods_original$届出番号
# 表記揺れに対応するため、「別紙様式(Ⅴ)-7」のさまざまなバージョンを作る
group1 <- c("V", "V", "Ⅴ")
group2 <- c(")", ")")
group3 <- c("-", "-", "―")
group4 <- c("7", "7")
# すべての組み合わせを生成
combinations <- expand.grid(group1, group2, group3, group4)
# 各組み合わせを連結して表示
combinations$text <- apply(combinations, 1, function(x) paste(x, collapse = ""))
# 検索対象の文字列リスト。いずれかが含まれたページを抽出
search_strings01 <- combinations$text
# 検索対象の文字列リスト。すべてが含まれたページを抽出
search_strings02 <- c("採用文献リスト", "著者名", "誌", "タイトル")
extract_text01 <- function(number, search_strings01, search_strings02) {
url <- paste0("https://www.fld.caa.go.jp/caaks/cssc06/youshiki5?yousiki5216File=",
number,
"%255C",
number,
"_youshiki5.pdf")
temp_file <- tempfile(fileext = ".pdf")
tryCatch({
download.file(url, temp_file, mode = "wb")
text <- pdf_text(temp_file)
}, error = function(e) {
return(list(text = "", num_pages = 0))
})
if (!file.exists(temp_file)) {
return(list(text = "", num_pages = 0))
}
selected_text <- ""
num_pages <- 0
for (i in seq_along(text)) {
page_text <- text[i]
first_1000_chars_cleaned <- gsub("[ \n]", "", substr(page_text, 1, 1000))
first_40_chars <- substr(first_1000_chars_cleaned, 1, 40)
if (any(sapply(search_strings01, grepl, first_40_chars)) &&
all(sapply(search_strings02, grepl, page_text))) {
# ページ番号を付加してテキストを追加
selected_text <- paste(selected_text, sprintf("Page %d:\n%s", i, page_text), sep = "\n\n")
num_pages <- num_pages + 1
}
}
file.remove(temp_file)
return(list(text = selected_text, num_pages = num_pages))
}
# tibbleの作成とデータの変換
documents01 <- tibble(
id = notification_numbers,
extraction_result = map(notification_numbers, ~extract_text01(.x, search_strings01, search_strings02)))
こうして、約8千件の届け出のうちから7389件の採用文献リストをゲットし、そこに例の医療専門誌が登場するかどうかを調べた。すると、半分超にあたる3942件がヒットした、ということでした。
もうひとつ、この医療専門誌のバックナンバーも、ウェブに載っているものすべてを調べました。こちらはバックナンバーへのリンクをまとめて記載したページから、それぞれのURLを取得した上でアクセスし、原著論文に関する情報が書かれたところを抜き出してtibbleにする、というようなことをしました。表記揺れや記載ミスもいろいろあるので、それなりに泥臭い作業ではありましたが、今回は割愛します(何しろ名前を伏せているので、割愛せざるを得ません……)。
おしまい。
この記事が気に入ったらサポートをしてみませんか?