
2024年の開発を振り返る

はじめに
今年も1年お疲れ様でした!
様々な参画先で、チャレンジングな課題に携わらせてもらい、毎日がワクワクする経験でした。特に印象に残っているのは、難易度の高い非機能要件タスクを任せていただけたことです。
バックエンドだけでなく、インフラの知見も組み合わせて、難局を突破できた時の感動は計りしなれいものでした。
この1年、本当にたくさんの方々に支えられました。
切磋琢磨しながら開発をともにしてきたエンジニアチームの方々、要件定義をしてくださるPMの方々、丁寧にQAをしてくださる方々。課題を設定し、大きな裁量を渡してくださるCTO。エンジニアリング部門だけでなく、売上のトップラインを伸ばすべく、最前線で闘ってくださるビジネスサイドの方々。皆さんのおかげで、今こうして充実した1年を過ごすことができました。本当にありがとうございます。
今回の振り返り記事では、例年以上に僕の頭の中での対話も赤裸々に書いてみました。「この課題に直面したとき、どんなことを考えて、なぜその解決策を選んだのか」というプロセスを、できるだけ詳しく共有しています。
もちろん、ここで書いた解決策はその時点での僕なりのベストアンサーであって、絶対的な正解じゃないと思っています。むしろ、サービスが成長していく中で、もっといい方法が見つかるはず。そんな前提のもと、「あぁ、こういう考えでこの選択をしたんだな」という一つの参考事例として読んでいただければ嬉しいです。
記事は結構なボリューム(4万字超え!)になってしまいましたが、興味のあるところだけつまみ読みしてもらっても全然OKです。年末年始のゆっくりした時間に、お茶でも飲みながら読んでもらえたら最高です。とにかく今回は例年以上に「もっと詳しく書きたい!」という思いでついつい筆が進んでしまいました。笑
これを読んでくださる誰かの役に立てたら、それが一番の喜びです。
それでは、対戦よろしくお願いします!!
EC2 → ECS Fargate へのリプレース

リプレイス前はフロントエンド・バックエンドともにEC2で動かしていましたが、
ワークロードに応じてインスタンス台数を増やす運用が大変
不定期にプロセスが落ち、安定性に欠ける
諸ミドルウェアの手動管理が大変
などの課題がありました。
これらを解決すべく、フロントエンド、APIサーバ、バッチ処理を全てECS Fargateへ移行しました。
リプレースをする上で悩んだ点と、それに対してどのような意思決定をしたのかについてつらつらと書いていきます。
意思決定ポイント
バッチ処理を EventBridge or cronプロセスどちらで実行するか?
ECSでバッチ処理を実行する場合は、EventBridgeからスタンドアロンでタスクを起動するのが一般的です。(Railsの場合は、起動時のコマンドを上書きしてrakeタスクを実行するイメージ)
しかし、当サービスにおいてはあえてこの方式を採用せず、バッチ用のECSサービスを作成し、その配下でバッチ用のタスク(実態はcronプロセス)を常時稼動させるようにしました。

理由としては以下の2点です。
実行間隔5分以内のバッチが複数存在しており、EventBridgeによるイベント駆動型のタスク実行ではオーバーヘッドが大きい。
5分に1回の頻度で、ECRからイメージをpullしてコンテナを起動するのは無駄が多すぎる。
wheneverというgemでバッチ処理を管理しており、EventBridgeへの移行が大変。
wheneverの設定ファイルからEventBridgeのルールを自動生成するツールもありましたが、Terraform管理との相性が悪いので見送りました。
とはいえ、バッチ用のタスクを常時稼動させる運用は、
重複実行が発生するためオートスケールは不可
リソースを常に監視する必要がある
など運用のペインが大きいので、バッチ処理自体の見直しを行った上で最終的にはEventBridgeからの単体実行にリプレースしたいと思っています。
環境変数をどこで持つか?
EC2で動かす場合は、サーバにsshログインして.envをvimで更新するような運用をしていました。
ECS Fargateで環境変数を管理するには、ざっと以下4つの選択肢があるかと思います。
ECSタスク定義のenvironmentで設定
S3に.envを置き、environmentFilesでS3オブジェクトキーを指定
Secrets Managerで管理
パラメータストアで管理
この中で2、3の組み合わせを採用しました。
>1. ECSタスク定義のenvironmentで設定
ECSタスク定義をTerraform管理する際、環境変数を追加するたびに差分が発生したり、シークレット情報の扱いが面倒になったりするので見送り。
>4. パラメータストアで管理
既存で環境変数が大量に設定されており、移行が大変だったのでお見送り。
2のS3管理であれば、.envファイルをそのままS3にアップロードし、ECSタスク定義にはS3 URLを置くだけで、ECSタスク起動時に自動で環境変数を読み込んでいるのでかなり楽です。
加えて、DBなど絶対に漏れてはいけないシークレット情報についてはS3に置くと危ないので、Secrets Managerに置くようにしました。
この組み合わせは、ECSタスク定義にてS3やSecrets Managerの参照先を設定すれば良いので、Terraform管理とも相性抜群です。(ECSタスク定義に環境変数をベタ書きだと変数が増えるたびにタスク定義側も更新をかける必要があり、運用コストが跳ね上がります)
DBマイグレーションをどのタイミングでやるか?
DBマイグレーションについては、専用のECSタスク定義を作成し、GitHub Actionsのデプロイワークフローから実行するようにしました。
具体的には、GitHub Actionsからaws ecs run-taskコマンドを実行して、マイグレーションタスクを起動 → タスクの完了ステータスの確認まで行います。
APIコンテナの起動時にマイグレーションを実行するような事例も見つけましたが、この方式ではオートスケーリングによってAPIタスクが増加するたびにマイグレーションが実行されてしまうので見送りました。
具体的にEC2→ECSへのリプレースで対応したこと
いくつかの意思決定に悩むポイントがありましたが、決定後は粛々とリプレース作業を進めていきました。具体的にやったことは以下の通りです。
ログの出力先をファイルから標準出力へ変更。nginx、puma、unicorn、delayed_job、cron など。これにより、すべてのログがCloudWatch Logsに永続化されるようになりました。
ECSサービスにおいて、追跡スケーリングポリシーによるオートスケールの設定。これにより、CPU・メモリが常に70%以下になるよう追跡して、スケールアウト・スケールインが行われるようにしました。
GitHub Actionsを使用して、ECSサービスをローリングアップデートするワークフローを構築 (B/GデプロイのニーズはなかったのでCodeDeployではなくGitHub Actionsからのデプロイとしました)
ローカル環境とリモート環境の条件を完全に揃えるために、docker-composeにて、nginx、unicorn、delayed_job、redis、mysqlコンテナを整備。これにより、開発環境とリモート環境の差異を最小限に抑えることができました。
これらの対応を通じて、手動EC2運用では実現できなかった、システムの安定性、冗長性、セキュリティ、および保守性が大幅に向上しました。
また、ローカル環境とリモート環境の一貫性が確保されたことで、検証環境にデプロイして初めて遭遇するエラーも激減し、開発の生産性も向上しました。
CircleCI → GitHub Actionsへのリプレース。デプロイ時間を25分 → 5分に短縮

当初、CI/CDパイプラインがCircleCIで動いていましたが、サポートが手薄になってきたこともあり、GitHub Actionsに全面的に移行しました。
一時は一世を風靡していたCircleCIでしたが、今ではGitHub Actionsに完全にシェアを奪われてしまいましたね・・
移行にあたって、特にデプロイ時間の短縮に力を入れました。以前は1回のデプロイに25分ほどかかっていましたが、以下2点の工夫を施すことで、最終的には5分まで短縮すること成功しました。
matrix strategyによる並列化
Dockerキャッシュの活用
まず、GitHub Actionsが提供するmatrix strategyを活用し、複数のイメージのビルドを直列ではなく並列で実行するようにしました。

さらに、Dockerのキャッシュも活用しました。これにより、package.jsonやgo.mod、Gemfileなどのパッケージ管理ファイルに変更がない場合、パッケージがキャッシュから再利用されるようになり、ビルド時間を大幅に短縮できます。
デプロイ時間の短縮は、特に検証環境へのデプロイにおいて重要です。
開発者は何十回、何百回とデプロイを行うため、待ち時間が長いと別のタスクに切り替えたり、Xを見に行ったり(笑)と作業の連続性が損なわれてしまいます。
一度設定すれば、未来永劫恩恵を受けられますし、チーム全体の開発生産性に直結する箇所なので、今後もデプロイ時間については一切の妥協をせず構築していきたいと思っています。
GitHub Actions OIDCによるAWS認証

先ほど紹介したタスクに紐づいて、もう一つ新しい取り組みを行いました。
それは、GitHub Actions上でのAWS認証の方式をIAMユーザー認証からOIDCによるIAMロール認証に切り替えたことです。
この変更の大きなメリットは、セキュリティリスクの低減です。
IAMユーザー認証の場合、GitHub Actionsのシークレット変数にAWS_ACCESS_KEY_IDやAWS_SECRET_ACCESS_KEYなどのお決まりの機密情報を保存する必要があります。万が一これらのキーが漏洩してしまうと、AWSのリソースが不正に操作され、深刻な被害につながる可能性があります。
前提として、IAMユーザーの数は最小限に抑えることが望ましいです。
OIDCを導入することで、GitHub ActionsにはIAMロールのARNのみを設定すれば済むようになりました。
なぜIAMロールのARNだけで認証が可能なのかというと、AWS側であらかじめ信頼できるGitHubリポジトリをホワイトリストに登録しておくことで、GitHub ActionsからのアクセスをAWSが安全に受け入れる仕組みがあるからです。
この仕組みにより、AWSリソースに変更を加えるようなパイプラインでは、全てIAMロールベースの認証が実現できました。
EC2の踏み台サーバにSession Managerを導入し、SSH接続を廃止

これまで、EC2の踏み台サーバへのアクセスには、22番ポートを開放し、全員にPEMファイルを配布してSSH接続を行っていました。
しかし、このやり方では22番ポートが直接攻撃されるリスクがあります。加えて、退職した人でも、鍵をローテーションしない限りは踏み台サーバへアクセスできてしまいます。
踏み台サーバへアクセスできるということは、データベースの中身も見放題ということです。
とはいえ、退職者が出るたびにPEMファイルをローテーションして、新しいものを全員に再配布するのは非現実的です・・
この課題を解決するために、Session Managerを導入し、IAMユーザー認証による仮想的なSSH接続を実現しました。
これにより、22番ポートを完全に封鎖できますし、退職者が出ても、IAMユーザーを削除さえすれば、踏み台へのアクセスを封じることができます。
今回の取り組みにより、セキュアな環境で効率的な運用が実現できるようになりました。
APIサーバのIAMユーザー認証をやめてSTSによるAssumeRole認証へ移行
RailsのAPIでAWSリソースを操作する際、当初はSDKの認証をIAMユーザーで行なっていました。
AWSのSDKでは、環境変数にAWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYを設定することで、自動的にIAMユーザーによる認証が行われるようになります。
しかし、先ほども触れたように、IAMユーザー認証ではこれらの環境変数が漏洩してしまうとセキュリティ上の脆弱性になってしまいます。
そこで、この認証方式を見直し、STSによるAssumeRole認証に移行することにしました。
移行作業自体はそれほど難しくありません。
まず、環境変数から先ほどの2つの変数を削除します。そして、ECSで動作するアプリケーションの場合、ECSのタスクロールとして最小権限を付与したIAMロールを設定すればOKです。
RailsのAWS SDKでは、先ほどの2つの環境変数が存在しない場合、自動的にSTSによるAssumeRole認証に切り替わるようになります。
この改善により、APIに直接付与していたサービス用のIAMユーザーを削除することができ、よりセキュアな体制を構築することができました。
セキュリティグループの最適化

当初、セキュリティグループが「http」や「rails」といった適当な名前で作られており、そこに穴をいっぱい開けて、一つのセキュリティグループを色んなリソースで使い回して、いわゆる「よくわからんがわちゃちゃ設定したらなんとか動いた」という状態になっていました。
この状況を改善するため、以下のようなアプローチで全面的な刷新を行いました。
サービス単位でセキュリティグループを作成することを徹底
ロードバランサー用
踏み台サーバー用
バックエンド ECSサービス用
フロントエンド ECSサービス用
データベース用
などなど
ALBのインバウンドルールについては、パブリックに置く都合上どうしても443番ポートで全面的にアクセスを受けられるようにする必要がありますが、他のサービスについては基本的にそのリソースにアクセスするサービスのセキュリティグループのみに絞るという設計にしていきました。
図で表すとこんな感じ
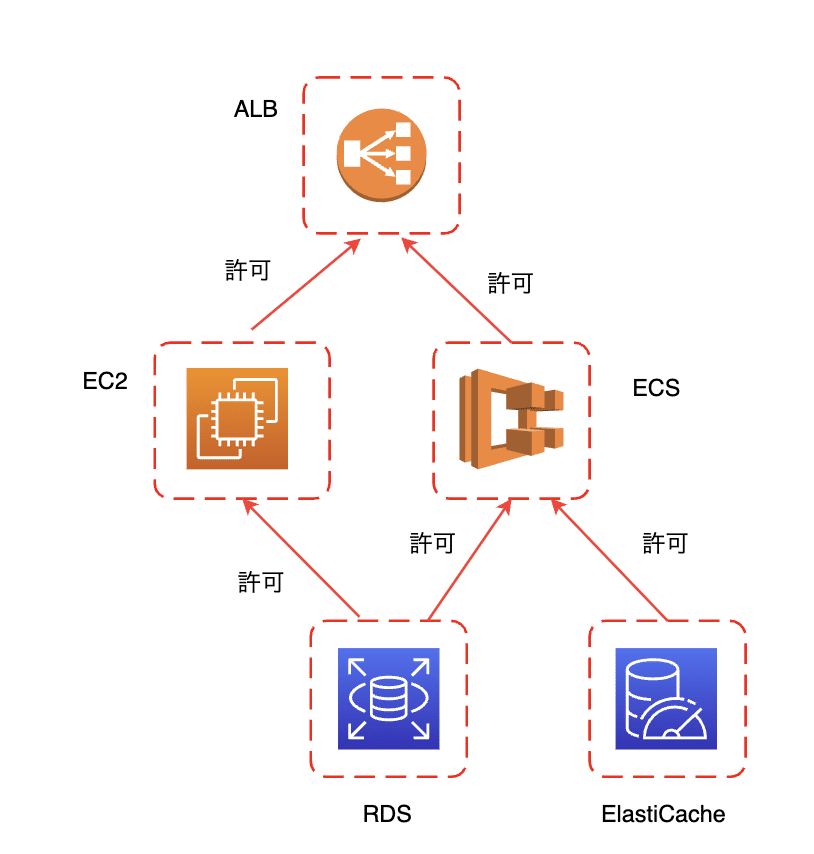
これらのセキュリティグループをTerraformで管理することによって、参照という形でセキュリティグループの依存関係が分かるため、通信経路を特定・絞ることができ、非常に見通し良くセキュリティグループを運用することができるようになりました。
CloudFront OACを導入し、S3のパブリックアクセスを廃止
これまでは、S3のブロックパブリックアクセスをオフにし、S3のURLを直接imgタグに埋め込むことで画像や動画を表示していました。しかし、この方法だとS3をダイレクトに狙われるリスクがありました。
セキュリティ強化の一環として、S3のブロックパブリックアクセスをオンにし、CloudFront経由でしかS3にアクセスできないようにするOAC (Origin Access Control) を導入しました。

OACを導入するメリットは、S3へのアクセスが必ずCloudFront経由になることです。これにより、CloudFrontでしか実現できない柔軟なセキュリティ設定やアクセス制御、暗号化などを適用できるようになり、セキュリティ面を大幅に強化することができます。つまり、入り口を一か所に絞り、そこを徹底的に守ることで、静的コンテンツ全体を保護するというイメージです。
設定自体はそれほど難しくありませんでしたが、既存のS3の直リンクがデータベースに格納されていたり、バックエンドやフロントエンドのコードにベタ書きされていたりと、既存の実装に影響が広く及んでいました。
そのため、OACの導入にあたっては、S3の直リンクをCloudFrontのURLにリプレイスする作業を慎重に進めながら、リリースを行っていきました。
OACの導入により、特定の国からのアクセスを制限したり、リファラーに基づいてアクセスを許可したりするなど、より柔軟なルールを設定できるようになり、セキュリティが向上しました。
ちょっとひと休憩

ここまでの内容はいかがでしたでしょうか?
まだまだ記事は続きますが、ここで少しお知らせをさせてください。
この度、LINE公式アカウントを開設しました。日々の技術的な気づきや、詳しく書ききれなかった実装の裏話なども、LINEでこまめに発信していく予定です!
特に、バックエンド×インフラの知見が必要となる非機能要件との奮闘記については、より深掘りした内容をシェアしていきたいと思っています。気になった方は、ぜひLINEで繋がれると嬉しいです!
それでは、本編に戻ります。
ALBにWAFを導入

フロントエンドとバックエンドで共通して使用しているApplication Load Balancer(ALB)に、AWS WAFを適用しました。
WAFのルールには、一般的にAWSが推奨するルールセットに加えて、DDoS攻撃を防ぐためのルールも設定しています。
WAFの導入にあたっては、いきなりブロックするのではなく、最初はカウントモードで運用を開始しました。
これにより、誤検知を慎重に確認しながら、徐々にブロックモードへ移行していくことができました。
なお、このプロダクトでは、一般ユーザー、企業ユーザー、社内ユーザーという3種類のユーザーが存在します。企業ユーザーや社内ユーザーが攻撃を仕掛けてくる可能性は低いと判断し、一般ユーザーからのリクエストにのみWAFのルールを適用するようにしました。
WAFを導入したことで、SQLインジェクションやクロスサイトスクリプティング(XSS)、DDoS攻撃などの脅威からアプリケーションを保護することができるようになり、プロダクトのセキュリティ面での堅牢性が大幅に向上しました。
ALB + Lambda によるBasic認証

ALB (Application Load Balancer)のターゲットグループにLambdaを配置することで、Basic認証を実現しました。
Basic認証を実現するにはざっくり3つのやり方が思い付きます。
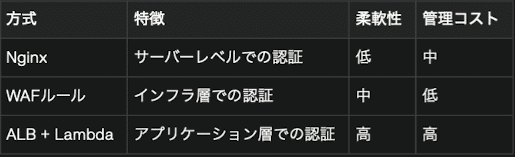
当時はまだWAFを導入できていなかったこと
フロントエンドをECSにホスティングしており、nginxコンテナは入れていなかったこと
動的に柔軟な認証を行えること
上記3つの理由により、ALB + Lambdaを採用しました。どこの会社でも必ず要求される設定なのでこの3つの手札は知っておくと便利かなと思います。
N+1問題撲滅によるページ速度改善 30秒→2秒

お客様がログイン後に最初に訪れる重要なページで、データ量の増加に伴い読み込み速度が30秒を超えるという深刻な問題がありました。この問題を解決するために、Rails側で発生していた大量のN+1撲滅に取り組みました。
「撲滅」という表現を使ったのは、N+1問題が1つや2つではなく、10箇所以上で発生していたからです。
RailsでN+1問題が起きやすい理由は、Serializerを使ってJSONを生成する際に、Serializerがネストしていくと、ルートから見てどのテーブルにアクセスしているのか把握しづらくなるためです。
調査方法としては、SQLのログを出力するように設定し、問題のページにアクセスした際に大量の無駄なSELECTクエリが出力されないようになるまで、地道にコードを読み込んで解消していきました。
この改善の結果、30秒以上かかっていた読み込み時間が2秒程度にまで短縮されました。
パフォーマンスの良いAPIと言えるレベルではないですが、N+1問題を解決するだけでもユーザーにストレスを与えない程度の速度にすることができました。
今後の改善点としては、現在のページが全データを一度に読み込む設計になっているので、フロント側で仮想スクロールを導入することでさらに快適なページにできると考えています。
また、Serializerのネストに起因するN+1問題の解決策として、以下の記事のように仕組みで防止する方法を模索したいと思っています。
RailsでN+1問題を防ぐgemとしてbulletが有名ですが、これはN+1問題が起きるようなテストデータを準備しないと落ちてくれないので、運用の難易度はかなり高いと感じています・・・
ECS Service Discoveryを導入し、システム間通信をプライベートにする

当初、システム間通信はhttps通信で行っていました。この方式だと、
一度インターネットの世界に出て
ドメインの解決をして
ロードバランサーを通り、
隣のECSサービスに入っていく
という、かなり遠回りな通信が必要でした。セキュリティ的にもよろしくありません。
これを解決するために、ECS Service Discoveryという仕組みを導入しました。
ECS Service Discoveryを使うと、同じVPC内であればローカルのエンドポイントでアクセスできるようになるので、セキュアなシステム間通信を実現できるようになります。
Kubernetesで大量のマイクロサービスを管理する場合は、通信相手のServiceのhostを指定するのがお決まりだったのですが、ECSでも似たようなことができるということを知って、個人的には大変感動した機能でした。
ECS ServiceのAPIにアクセスするために、ALB or NLB が必須と思い込んでたけど、Service Discoveryの仕組みを使えばダイレクトに繋げられるのか!
— りょうま@フリーランスエンジニア (@engineer_ryoma) April 26, 2024
これを使えば、Lambda、EC2や他のECSから http://service-name.namespace のようにプライベートネットワークでアクセスできるようになるから最高すぎる pic.twitter.com/wOuln2r7lF
これにより、VPC内に閉じたシステム間通信を実現できました。
極論ですが、これまでBasic認証やシステム間認証トークンを使っていた箇所は全て取り除くことができるようになります。(ALBのリスナールールに登録されていない前提ですが)
k6による大規模イベント負荷試験ツール作成

ウェビナー開催ツールを提供しているプロダクトで、1000人規模のイベントがあったときにサーバがワークロードに耐えられるかどうかを検証すべく、負荷試験を実施しました。
実装の工夫
k6という負荷試験のツールを使って、実際にブラウザをVM中で立ち上げて検証しようとしたのですが、いくつか課題がありました。
ローカル環境では5人分くらいのブラウザを立ち上げただけでMacBookのメモリやCPUがクラッシュしてしまう。
ECSで大量のスペックを積んでも、1000人がブラウザを起動するには天文学的なスペックを積まないと不可能。
解決方法
5人ごとに1台のECSタスクを立ち上げるという方式を採用しました。具体的には、
1000人の場合、5人ごとなので200タスクを起動
ECSタスク起動APIのレートリミットを避けるためにタイミングをずらす
1タスクあたり5人分ずつ別スレッドで仮想ブラウザを起動し、イベント開催画面にそれぞれアクセス
これによって、1000人が同時接続する大規模イベントを再現することに成功しました。
負荷試験の結果、API/DBともにワークロードが増加しても問題ないということを確認できました。
ECSにホスティングするフロントエンドのプレビュー環境を自動作成する仕組みを構築

そのプロダクトでは、Next.jsをECSにホスティングしていたのですが、パッケージアップデート系のタスクをdevelopブランチにマージするとコンフリクト地獄が発生するという辛みがあり、Amplifyのプレビュー機能のようなものが欲しいというニーズがありました。
Amplifyでは、PRを作成すると、そのブランチ専用の環境がサブドメインも含めて払い出されるというプレビュー機能がありとても便利です。
解決のため、ECSでAmplifyのプレビュー機能と似たようなことを再現しました。
やったこととしては、以下のサービスを丸っとTerraformのモジュールで作れるようにしました。
Route53 Aレコード (サブドメイン発行用)
ALBのリスナールール、ターゲットグループ
ECR、ECSタスク定義、ECSサービス
moduleの引数としてPRのブランチ名を入れたら、専用の環境が一個作成され、引数から抜いたら、関連リソースが削除されるというシンプルな仕組みです。
Terraformでしっかりリソース管理していたので、こういうやり方で実現することができました。
全体構成は以下の通り

この類の構築をやる場合、共通で使えるサービス、分けないと実現できない or 後々辛くなるサービスを的確に見極めて、できるだけ省エネしていく必要があります。かなり知恵を振り絞って構成を考えたので詳しめに解説します。
全ブランチ共通で使うサービス
ALB
ALB用のSecurity Group
ECR
imageハッシュにブランチ名のエイリアスをつけて環境を区別する
ECSクラスター
ブランチごとに分けるサービス
ALB リスナールール、ターゲットグループ
hostヘッダーのサブドメインで対象のECSサービスへリクエストを振り分ける
ECS Service
ブランチ単位でサーバの更新をかけたいため
ECSタスク定義
参照するイメージのバージョンエイリアスが異なるため
Route53 Aレコード
feature-1.example-stg.com のようにサブドメインを登録
向き先はプレビュー用のALB
上記に加えて、プレビュー環境用のデプロイパイプラインをGitHub Actionsで構築しました。内容は以下の通り
PR内で /update_feature というコメントを作成するとワークフローが起動
イメージのビルド
環境変数は検証環境共通のものを使うが、いくつかプレビュー環境独自のものが必要なので、適宜sedコマンドでreplace
ECRへブランチ名をエイリアスとしてpush
対象のECS Serviceをaws cliで更新
これにより、
terraformのmoduleにブランチ名を貼り付けてapplyするとブランチ環境構築完了
PR内で /update_feature コメントを作成すると、デプロイ
という運用フローを整備することができ、フロントエンドエンジニアが快適に大規模なコード改修が行えるようになりました。
Amplifyでやると上記がボタンポチでできてしまうので、改めてマネージドサービスの威力を感じたタスクでもありました笑
ElastiCache導入によるレイテンシ改善

背景
分析画面のページの表示が遅いという問題があり、当初は
Serializerを改修して、1レコードあたりのデータ量を減らす
N + 1問題 をなくす
などの改善はやってみたものの、どうしても複雑なクエリを実行しているため、一定以上の速度改善は厳しいという状況でした。
解決策
そこまでリアルタイム性が必要なページではなかったので、 AWS管理のElastiCache(Redis) を新たに導入し、インメモリキャッシュでの改善を試みました。
Redisのようなインメモリデータベースの特徴として、以下があります。
・ すべてのデータをメモリ上に展開・保管
・ ディスクI/Oと比較して、データアクセスが圧倒的に高速
・ RAMの特性を最大限に活用
DBから取得し、ゴニョゴニョ加工した後のデータをRedisにセットし、同じリクエストが飛んでくればRedisからそのまま返します。DBからの取得・データの加工処置がスキップされる、かつメモリ上のデータのためエンコード・デコードが不要になるためめちゃくちゃ高速になります。
余談ですが、バックエンドエンジニアにとって、データベースの適材適所を理解することは非常に重要なスキルだと思ってまして、
具体的には、
リレーショナルデータベース(RDBMS)
キーバリューストア(RedisやMemcachedなど)
ドキュメント指向データベース(Firestore、DocumentDBなど)
列指向データベース(Redshift、BigQueryなど)
これらの特性を理解し、ユースケースに応じて最適なものを選択できる能力が必須です。
この分野について深く学べる書籍として、『データ指向アプリケーションデザイン』を強くお勧めします。この本はデータベース設計の考え方について体系的に解説されており、実務で直面する様々な判断の指針となる、まさにバイブル的な一冊です。
UXへのこだわり
この改善で特にこだわったポイントとしてはUXの方です。
一般的には、アプリケーションキャッシュの扱いとして、
1時間に1回キャッシュを削除する
キャッシュ対象のリソースに変更があった時についでにキャッシュを削除する
という運用をするかなと思います。
今回については、数字が1時間も更新されないというのは不便だし、とはいえ毎分変わるような必要もない、欲しいときにデータが更新されてればいいというニーズでした。
そこで、
ダッシュボードの画面にローディングボタンを配置
クリックしたらくるくると回って最新のデータがクエリを元に生成
キャッシュにセットされて返却
ローディングボタンの隣に最終更新時刻を表示
という仕様にしました。
効果
これにより、ページの描写速度が30秒→50ms以下になり劇的にUXが向上しました。
この仕様にすることで、
最新のデータが不要な人にとっては爆速で表示される
最新のデータが欲しい人にとっては、ローディングボタンをクリックすれば1分程度で最新データが出来上がる
というUXを実現することができ、ユーザー体験とパフォーマンスのバランスが取れた良い改善事例だったかなと思います。
Railsアプリケーションのログの改善(Semantic Logger)

Railsのログがテキスト形式になっていて、調査しづらいというペインからスタートしたタスクです。
実装アプローチ
まず、検索性能を上げるためにJSON構造にしたいというところでいろんなgemを調べた結果、semantic_loggerが良さそうでした。
拡張したログ情報
デフォルトだとhostやheaderなどの基本的な情報しか入っていないので、ミドルウェア層(controllerのafter_action) で、以下の情報を追加し、トレーサビリティを高めました。
ログインユーザーのID
ログインユーザーのロール
ログインユーザーが所属する企業のID
エンドポイント (method + path)
最適化のポイント
同時に、今まで不要に出ていたヘルスチェックのログを除外し、ログが汚染されないようにしました。
効果
これにより、「このデータ消えちゃったんだけど誰か削除しましたか?」のようなお問い合わせに対してもすぐに回答できるようになり、加えてクライアントからの監査要件にも応えられるようになりました。
ログというのはどうしても軽視されがちなところですが、調査をする上で非常に重要な足跡になりますし、ちょっとサボるとチリツモでコストに効いてくるので、絶対に妥協しない方が良いかなと個人的に思っています。
【ログを制する者はプロダクトを制す】
— りょうま@フリーランスエンジニア (@engineer_ryoma) November 6, 2024
今年は3社でログの改善をやってきたけど、この辺りを全てクリアしているプロダクトはなかなか無いので要チェック。
・ヘルスチェックなど不要なログを除外しているか
・SELECTクエリを除外しているか
・ログインユーザーの属性情報をpayloadに入れているか
・JSON形式などに構造化されているか
— りょうま@フリーランスエンジニア (@engineer_ryoma) November 6, 2024
・リクエスト単位でIDが発行されており、一連のログをまとめられるか
・ログの検索ついてチームメンバーが運用で使いこなせているか
これらを全てクリアしていれば、かなりスマートかつ低コストな運用を実現できるはず。
AWSアカウント分離プロジェクト

AWSアカウントを分離したい目的は2つあります。
誤操作(ヒューマンエラー)の防止
セキュリティと育成の観点
誤操作(ヒューマンエラー)の防止
検証環境でごにょごにょ何かをやるときに、そこに本番環境の資産があると常に気を張って地味なストレスがかかりますし、油断すると間違えて本番の方で検証してしまったという事故も起こり得ます。
セキュリティと育成の観点
サービスが成長して組織が大きくなってくると、リファラル一本釣りの採用ではスケールに限界がきて、いわゆる身内以外の人を採用する必要があります。時にほぼ未経験の新卒を採ることがあるかもしれません。
同一アカウントに本番と検証環境が同居していると、どうしてもポリシーで制限をかけるのは厳しいので、AWSのログイン権限を渡さないという極端な意思決定をするしかありません。
もし、検証環境専用のアカウントがあればどれだけ壊しても大丈夫なので、新卒や副業・業務委託のメンバーでも自由にAWSの資産にアクセスしてもらえるようになります。
まずは全てのリソースをTerraform化
手動で同一の環境を作るのは至難の技ですし、資産性がないので、まずは全リソースをTerraform化することから始めました。
terraform importで既存リソースをインポート
moduleを使ってリファクタ
terraform state move でリファクタ後に変更のあったステートファイルのアドレスを引っ越し
terraform planで差分が0になるまで微調整
どうしてもコード化できないものは定数やdataリソースで逃げる
という地道な作業をひたすら繰り返しました。Lambdaに関してはソースコードベタ書き状態だったので、バックエンドのリポジトリにスクリプトを引っ越ししつつコンテナ化を行い、Terraform内にロジックがないように工夫しました。
Lambda内でコンテナとして動かすことで、Terraform側ではECRのarnだけを持てば良くなり、ソースコードの管理が不要になります。
副業での稼働でしたが、5ヶ月ほどかけて全てのリソースをTerraform化していきました。
terraform applyによる複製
本番環境は絶対に壊せないので、検証環境を別アカウントに逃すという方針にしました。
一気に複製を行うと、原因の切り分けが大変になるので、module単位で少しずつterraform applyを行い、正しい挙動になるか細かく確認。という手順を繰り返して引っ越し作業を進めていきました。
Terraformにより爆速で新しい環境が出来上がっていくのは感動の体験でした。自炊と一緒で、準備には多大な時間を要しますが、複製作業自体は一瞬で終わりましたね。笑
データ移行
Terraformにより同一リソースを複製するだけでは、ただの箱ができただけです。プロダクトはデータがあって初めて動きます。
以下の手順でデータを地道に移行していきました。
マルチアカウント間での作業になるのでIAMポリシーによる認可の設定が必要です。
データベースの移行
スナップショットを取って別のアカウントに受け渡し
ECRのイメージの移行
エクスポート、インポートという概念はないので、スクリプトを組んでローカルからaws cliで移行
S3のデータの引っ越し
aws cp コマンドで引っ越し
Cognito User Poolのデータ移行(これが地味に大変でした)
スクリプトを組んで、全ユーザーをCSV化 → 新アカウントのインポート機能に流し込み
実際のスピード感としては、Terraform化するまで5ヶ月程度(副業稼働)、アカウント分離の実施は2日ぐらいでした。
特にアカウント分離の作業自体は、200%の集中力で15時間ぶっ続けて作業しました。移行作業中は検証環境が使えなくなりますし、ダラダラ長引くと結局中止になるという結末になりがちなので・・・
開発チームから「AWSアカウント移行を2日でやり切るのは流石に変態すぎる」というありがたい?褒め言葉もいただけました。笑
IAMユーザーの運用の工夫
アカウント分離をしたときに避けたいのが、全員が複数のIAMユーザーを持つという運用です。
アカウントを切り替える際に再ログインが必要となり面倒ですし、IAMユーザーを何個も作るのはセキュリティ的によろしくありません。
そこで、IAMスイッチロールという仕組みを使って、マルチアカウントで簡単にアカウントを切り替えられるようにしました。
IAMユーザーはそれぞれ1つで、各AWSアカウントにAdmin、PowerUser、ReadOnlyの3種類のIAMロールを用意。AWSコンソールの右上のメニューから切り替えるイメージです。

スイッチロールをするには、各メンバーにコンソールでの設定や、ローカルのaws credentialsの設定をしてもらう必要があったので、ドキュメントを充実化し、加えてハンズオンの時間を設けて一人残らず面倒で後回しにすることがないようにしました。
教訓
アカウント移行作業はかなり骨の折れる作業ですし、なんだかんだやり切る胆力がなく、中途半端な状態でプロジェクトが終わってしまうこともザラにあります。インフラ構築時点で、少し手間をかけてでもマルチアカウント運用で始めることを強く強くお勧めしたいです。
Lambda@Edgeによる静的コンテンツのアクセス制御

S3に置かれたファイルの認可における課題
S3で管理する静的コンテンツを配信する場合、CloudFront経由の有無によらず、ファイルのURLを知っている人は誰でもアクセスできてしまうという問題があります。
特にクライアント企業の機密情報が含まれるファイルだと、権限のない人が適当にURLを推測してダウンロードできるのは、セキュリティ的に相当まずいです。
一応パスをランダムな文字列にすれば予測は難しくなりますが、それでも公の場所に内部情報が晒されている事実に変わりはありません。
解決のための4つのアプローチ
この課題に対して大きく分けて4つのアプローチがありました。
DBの中にファイルのバイナリデータを置き、API経由でコンテンツを取得する
CloudFrontの署名付きCookieを使う
WAFを使う
Lambda@Edgeを使う
結論としては、4. Lambda@Edge を採用しました。
>1. DBの中にファイルのバイナリデータを置き、API経由でコンテンツを取得する
APIの認証で守れるため安全ではありますが、動画ファイルを保存するとDBのストレージが凄まじい勢いで肥大化していくため、最近のWeb開発だとあまり見ないパターンです。(昔のRailsならImageMagicの接続先をDBにするやり方をチラほら見ました)
>2. CloudFrontの署名付きCookieを使う
ファイルはS3に置き、CloudFrontの署名付きCookieでアクセス制限をかけるというパターンです。ファイルURLへのアクセス時にCookieも一緒に送れるため、CloudFront側で認可判定ができます。
今回の問題を理解するポイントとしては、ファイルURLをクリックしてコンテンツをダウンロードする際に、カスタムヘッダーは送れないが、Cookieであれば送れるという点です。
しかし、認証周りで複雑なシーケンスとなっている都合上、署名付きCookieをサーバ側で発行するタイミングが難しく、導入を見送りました。
>3. WAFを使う
CloudFrontにつけているWAFで制御するやり方もあります。しかし、WAFではhostヘッダーの有無や、静的なパスの指定による制御はできますが、動的なトークンやパスを認可するほどの柔軟性はありません。
ということで、柔軟性抜群のLambda@Edgeを採用しました。
前提として、S3にはOAC(オリジンアクセスコントロール) を設定し、CloudFrontからのアクセスしか受け付けていないため、全てのリクエストがCloudFrontにつけたLambda@Edgeを通過します。
全体の構成は以下の通りです。

閲覧制御をかけたいコンテンツは、S3の/private/* に置く
CloudFrontのデフォルトビヘイビアのオリジンはS3に設定
/private というビヘイビアを作成し、オリジンは同様にS3とする
ただし、当ビヘイビアの関数の関連付けにて、ビューワーリクエストにLambda@Edgeを設定する
Lambda@Edgeから静的コンテンツの認可APIを呼び出す。その際、Cookieやパスも一緒に送る
APIでは、Cookieやパスの組み合わせで柔軟な認可ロジックが存在し、閲覧OKなら200、不可なら403を返す。
Lambda@Edgeにて、APIから200レスポンスが返ってきた場合のみS3へのアクセスを継続する。それ以外はdenyする
この仕組みにより、静的ファイルへ直アクセスしたとしても、指定のCookieが存在していなければ403ページを表示して閲覧制御をかけられるようになりました。
APIでゴリゴリにロジックを実装できるので、極端な話、「このプロジェクトに属している、かつ指定の権限以上のユーザーしか閲覧できない」 などの要件にも応えられるようになります。
Lambda@Edgeの特徴と学んだ注意点
余談ですが、このLambda@Edgeというのが実は結構クセモノでして、AWSのサービスの中に「Lambda@Edge」というものがあるわけではないんです。
Lambdaを特定条件(リージョン、環境変数の有無など) で動かせば、それが初めてLambda@Edgeとして機能するというなんとも分かりづらい独特な作りとなっています。なので、実際に動かすまでが一苦労でした。
デプロイやログの出力先も普通のLambdaとは勝手が違うので、そこは気をつけないといけないポイントです。
例えば、Lambda@Edge自体はバージニア北部にあるのですが、アクセスログは、アクセスしたユーザーに最も近いリージョン(ap-northeast-1) に出力されるなど、初見殺しの仕様にハマりまくりました笑
Lambda@Edgeを使った静的コンテンツの認可基盤は、導入のハードルは高いですが、一度入れてしまえば、どんな複雑な認可要件にも応えられる最強の柔軟性を獲得できるので、ぜひ導入を検討してみても良いかなと思いました。
RubyからGoへリプレース。バージョン管理の辛みからの解放

そのプロダクトには、Lambda関数やECSタスクとして動作する10個程度の小規模なサブシステムが存在し、当初はすべてRubyで実装されていました。(Lambda上ではコンテナランタイムとして動かします)
問題の発端は、Rubyのバージョン更新。セキュリティ上の理由でRubyのバージョンはこまめに上げざるを得ないんですが、これが本当に面倒な作業でした。
Rubyではバージョン更新を行うと破壊的な変更が入ることが多く、さらには実際に動かしてみるまで、壊れてるかどうかも分からないという恐怖があります。
なので、Rubyのバージョンを上げる度に総回帰テストをガッツリ走らせる必要があるのですが、ただでさえ手が足りないQAチームに依頼する運用は限界が来ていました。
Goのバージョン管理のシンプルさとbuildの安心感
脱Rubyを決断した最大の理由は、Goのバージョン管理のシンプルさです。Goは、バージョンを上げても基本的に下位互換性が維持されており、破壊的変更は滅多に起きません。
皆無とは言えませんが、そういう稀なケースでもビルド時にエラーで落としてくれます。つまり、CI/CDパイプラインでイメージをビルドする際に、万が一問題があれば落ちるため、動かない状態でデプロイが成功し、サーバが起動するという悲劇は起き得ないです。
加えて、そもそものパッケージ管理(go.mod )の仕組みが非常に優秀で、依存関係がコマンド一発で解決します。
JavaScriptのnpmとは違って、ローカルの環境構築にて依存関係周りでハマることもほぼほぼありません。
リプレース作業は生成AIにより一瞬で完了
リプレース作業自体は、生成AI(Cursor) で9割ぐらいやってもらいつつ、最終調整を自分の手でやるだけでした。時間としては、3時間程度でしょうか。生成AIがなかったら、間違いなく丸1週間はかかっていると思います。
晴れて、バージョン更新後のリグレッション地獄から解放
というわけで、当プロダクトのサブシステム群はGoへの移行でバージョンアップ後のリグレッション地獄から晴れて解放されました。
もちろん、最低限の動作確認はしますが、リグレッションテストの工数自体は10分の1程度になりました。
みなさんも、同じようなバージョン管理の悩みを抱えてるなら、ぜひGoを検討してみてください。
AWSリソース監視のダッシュボード作成

AWSのリソースを包括的に監視するために、CloudWatchダッシュボードを作成しました。
このダッシュボードには、以下のウィジェットを配置しています。
フロントエンドとバックエンドのECSに関するメトリクス
CPU使用率
メモリ使用率
タスク数
ロードバランサー(ALB)のAPIに関するメトリクス
リクエスト数
500エラー数
レスポンスタイム
RDSに関するメトリクス
CPU使用率
メモリ使用率
コネクション接続数
これらのメトリクスをダッシュボード上に一括で可視化することで、システム全体の状況を俯瞰できるようになりました。
毎月の定例会議では、このダッシュボードを全員で確認して、システムの稼働状況を振り返っています。何らかのスパイクやアラートが発生した場合には、Next Actionを設定して適切な監視と対応を行う体制を整えています。
AWS Chatbot + CloudWatch Alarm + SNS によるリソース監視アラートの作成

リソースダッシュボードはできたものの、障害発生時に気づける仕組みがなかったため、アラート通知機能を作りました。
具体的には、CloudWatch Alarm + SNS + AWS Chatbot をTerraformで構築しました。

監視対象は以下の通り
ECS
サービスのCPU/メモリ(バッチ、API、フロント)
RDS
CPU/メモリ
ストレージ
ALB
5xxレスポンス数
それぞれの閾値を設定し、CloudWatch Alarmから超過時にSNSトピックにイベントを流します。SNSからChatbot経由でSlackの指定チャンネルに通知されるようにしました。
工夫した点として、AWSのデフォルト通知は英語でわかりづらいので、ディスクリプションを整えました。
例えば「RDSの残ストレージが5GB下回りました。」などと日本語で書いて、何が問題なのかパッと見てわかるようにしています。
これにより、障害発生時にすぐ気づいて対応できるようになり、安定したサービス提供ができるようになりました。
AthenaによるALBログ解析基盤の構築

サイト全体的に遅いページがあり、まずはどのAPIが遅いのか特定したいという要求がありました。
API単位のレスポンスタイムを取る仕組みがなかったため、ミニマムかつ柔軟にレイテンシーを見れるようにしたいと思い、AthenaによるALBログ解析基盤を構築しました。
ALBのログはS3に吐き出されますが、そのログをAthenaでSQLクエリを発行して解析できるようにデータベース/テーブルを定義しました。
最終的に以下のようなSQLでレイテンシ60秒以上のエンドポイントを洗い出すことができます。
SELECT
parse_datetime(time, 'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') AT TIME ZONE 'Asia/Tokyo' AS jst_time,
domain_name,
request_verb AS method,
request_url AS url,
target_status_code AS status_code,
CAST(target_processing_time AS DOUBLE) AS response_time
FROM
access_logs
WHERE
parse_datetime(time, 'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') AT TIME ZONE 'Asia/Tokyo'
BETWEEN timestamp '2024-10-30 00:00:00 Asia/Tokyo' AND timestamp '2024-10-30 23:59:59 Asia/Tokyo'
ORDER BY
jst_time
LIMIT 10
;これによりパフォーマンスの悪いAPIのパスを洗い出し、一つ一つ潰していくことができました。
Athenaはログ調査やデータ基盤など、S3の中身を調べたい時に非常に強力なツールなのでおすすめです。
Cloudflare R2導入による動画配信コストの削減

とあるクライアント様のイベントページのLPに動画を埋め込んでいたのですが、CloudFront経由でS3から配信していて、月15万円を超える高額な配信料がかかっていました。
そこで、Cloudflare R2に着目しました。R2はAWSのS3に相当するストレージサービスですが、外部ネットワーク配信料が無料という、えげつないサービスです。
Cloudflare R2の威力はこの記事で知りました。当時、あまりの衝撃に目を疑ったのを今でも覚えていますw
具体的にやったこととしては、
Cloudflareアカウントを開設
R2を設定
S3の動画をR2に移行
カスタムドメインを割り当てて配信開始
という流れです。
CloudFlare で300MB以上のファイルをアップロードするのに、cliからやる必要があるんですが、まさかのaws cliから上げる仕様でビビりましたw
カスタムドメイン設定時、CNAMEを他のプロバイダーで管理していたため若干ハマりましたが、Businessプラン(200ドル/月) にすることで解決しました。
本件、Freeプラン → Businessプランにアップグレードすることでできるようになりました! https://t.co/PRnvJJwa3R
— りょうま@フリーランスエンジニア (@engineer_ryoma) October 18, 2024
導入して3ヶ月ほど経過しましたが、月あたりの配信料は0円、Businessプラン代が3万円で、トータル月12万円程度のコスト削減に成功しました!
今後、どれだけアクセスが増えようとも200ドル/月が固定なので、あまりのコスト削減の威力に感動を覚えた一件でございました笑
Step Functionsによる1年先のメール予約配信機能
メール予約配信の要件として、
1年先まで予約可能
指定時刻の大きなズレは許されない (遅くとも + 1分)
システムメンテナンスでDBが落ちている場合でもリカバリできると嬉しい
というかなりシビアなものでした。
パッと思いつく3つの手札を検討したがどれもNG
そのプロダクトはRailsで動いており、指定時刻に何かの処理を実行する手段として以下3つの手札がありました。
バッチ処理で定期的にポーリング
Sidekiqのperform_at
SQSのメッセージタイマー
結論として、今回の要件では上記の手札は使えませんでした。
>1. バッチ処理で定期的にポーリング
数分のズレも許されないので、毎分実行のバッチ処理にする必要があり、あまりにも無駄が多い。加えて、配信対象数が増えてくると1分以内にメールを配信しきれないという辛みが待っています。
極端な話、バッチでのポーリングでヒットしたレコードが1万件レベルになると、for文による配信では間に合わない未来が想像つくかなと思います。
>2. Sidekiqのperform_at
Sidekiqのキューの保管はRedisで行われており、揮発性が高く1年というタイムレンジを保証するにはあまりにも心許ない。
>3. SQSのメッセージタイマー
最大待機時間は15分のため、1年というタイムレンジでは要件を満たせない。
Step FunctionsのWait状態で行けた!
そこで色々調査したところ、Step FunctionsのWait状態という新しい手札がを見つけました。
指定時刻まで待機し、時間になったら次の処理に進むというまさに要件にピッタリの機能です。さらに、最大待機時間も今回の要件ドンピシャの1年!
絶望の中に光が差し込んだ瞬間でした笑

これで、1年先の予約実行の課題は突破しましたが、まだシステムメンテナンス時のリカバリをどうするかという課題が残っていました。
こちらについても、Step Functionsのエラーハンドリングのリトライオプションという機能がピッタリでした。
数時間のメンテがあっても、エラー時に1時間後、3時間後とBackoff方式でリトライすることで、メンテが明けた時に成功させることができます。(メールの配信時刻がズレたとしても送信して問題ないという仕様をPMとすり合わせの上意思決定しました。)
これにより、1年後の予約配信であっても、1分ズレることもなく、サーバレスで、たとえシステムメンテがあってもリカバリ送信できる、強力な予約配信システムを整備することができました。
Step Functionsの可能性は無限大ですね。
最大50万件のメール配信システムの構築

当初、メール配信をfor文による同期的な実装で行っていましたが、メールの配信対象者数が1000件以上になるとAPIがタイムアウトエラーになるという課題がありました。これを機にメール配信基盤を刷新しようという方針となり、非機能要件として以下の3つが追加されました。
最大50万人のユーザーに向けて一斉送信できること
遅くとも1時間以内には送信完了すること
送信に失敗したユーザーを判別でき、リトライによるリカバリーができること
システム設計に明るい人であれば、この要件がいかに厳しいかなんとなく察していただけるかなと思います。
せっかくなので、設計案の変遷を時系列順に紹介します。
before. for文に同期的な処理
当初はfor文を使ったシンプルな実装でした。
users.each do |user|
SendGridService.new.call(user.id)
endしかし、メール配信数が増えるにつれてAPIがタイムアウトになるという問題がありました。
STEP1. 並列処理
次に、メール送信を並列処理でやる案を検証してみました。
Railsで並列処理をするにはparallelというgemが有名です。
https://github.com/grosser/parallel
Parallel.each(users, in_threads: 1000) do |user|
SendGridService.new.call(user.id)
end処理速度は改善されましたが、今度はDBコネクションプールが枯渇してしまうという問題が発生しました。1万件以上の規模になると安定して動作しませんでした。
STEP3. Sidekiqで非同期処理に挑戦
そこで、Sidekiqを使用した非同期処理にアプローチを変更しました。
APIとしては、メール送信ジョブをキューに入れて処理が完了です。DBへの複数INSERT処理やSendGridへの送信処理などを非同期処理として逃すことができるので、時間の短縮になるのでは?という狙いです。
users.each do |user|
SendEmailJob.perform_later(user.id)
end
しかし、このやり方もうまくいきませんでした。
大量のメール配信ジョブによってワーカープロセスが圧迫され、システム全体の非同期処理のパフォーマンスに影響が出てしまいました。

「検証環境でパスワード再設定メールがいつまで経っても送られてきません・・」という報告が相次ぎました。
やはり、50万件規模の配信となると、APIコンテナとタスク内で同居しているSidekiqコンテナでやるにはあまりにも貧弱になってしまうという課題が浮き彫りとなりました。
STEP4. ECSタスクによる分散処理
上記の検証を経て、次は、メール配信処理を別のECSタスクに逃す方式を試みました。

APIが動作するサーバとは別環境へ配信処理を逃す
1000件ごとに並列でECSタスクを起動することでスピードアップ
という2つの狙いがあります。
この方法である程度のスケーラビリティは確保できましたが、これも解決には至りませんでした。

AWSのECSタスク起動APIのレートリミット(1秒間に20コールまで)に引っかかってしまいました。
sleepで逃げるというやり方もありましたが、APIでやるにはちょっとヤンチャすぎます。
加えて、APIから大量のECSタスクを起動した後は、誰もタスクのステータスを監視していないので、インフラ側の起因でとあるECSタスクだけ落ちてしまった場合はリカバリのしようがありません。
いわゆる、「後は野となれ、山となれ」状態です。笑
上記の検証を繰り返していきながら、こんなことができると嬉しいなと思いました。

APIから何か中央集権のコントローラーのようなものを起動し、
そのコントローラーがレートリミットに引っかからないような間隔でECSタスクを起動
大量に立ち上げたECSタスクの結果を見守り、何か問題があれば、リトライ
それでも失敗するなら、そのタスクの管轄の配信対象者をDBに保存し、Slack通知
これらを全て実現できるサービスがないか探したところ、ピッタリのものが見つかりました!
STEP5. Step Functionsによるブレイクスルー
はい、またしてもStep Functions です。
この記事で2回目の登場。AWSが生み出した最高傑作ですね笑
詳細は省きますが、最終的にこんな構成に辿り着きました。

メール配信APIでは、Step Functionsを起動してブラウザへレスポンスを返すのみ
50万件のメール配信対象ユーザーを1000件ごとに分割してMap Stateへ進む。(並列処理)
それぞれの並列処理内では、Wait Stateによりランダム秒数待機
ECSタスク起動APIのレートリミット突破と、DBへの一斉書き込み負荷を分散する狙い
ECSタスクがインフラレイヤーで落ちたらエラーハンドリングを行う
万が一、ワークフローが失敗したらSlackへ通知
これにより、50万件のメールを1時間以内に送信完了できるようになり、高い配信能力を獲得できました。
まとめ
まるでパズルのピースが最後にぴたりと収まるように、Step Functionsを導入することで、それまでの全ての課題が一気に解決されました。
APIタイムアウトの問題
APIの責務をStep Functionsの起動に留める
DBコネクション枯渇問題
複数のECSタスクに分割し、1タスク内では同期的に処理を行うこと、使用するコネクションは1つでOKとなる
非同期ワーカー枯渇問題
メール配信処理をAPIとは別のECSタスクに逃すことで解決
そもそも1時間以内にメールを配信できない問題
メール配信処理を複数のECSタスクに分割することで、実行環境レベルでの並列化を実現
インフラ起因でECSタスクが落ちた時にエラーハンドリングできない問題
Step Functionsというオーケストレーションサービスにより、ECSタスクの完了ステータスを見て、リトライ、別ステップへ移動などのエラーハンドリングが可能

かなり難易度の高い非機能要件で心が折れそうでしたが、社内でもお褒めの言葉をいただき感無量でした。
APIサーバをLambda → ECSへリプレース

当初API Gateway + Lambdaのサーバーレス構成でAPIサーバーを動かしていましたが、Lambdaの諸々の制限がきつくなってきたため、ALB + ECSの構成に移行しました。
Lambda特有の辛み(制限)としては以下のようなものがありました。
最大実行時間: 15分(900秒)
ペイロードサイズ制限
同期呼び出し: 6 MBまで
非同期呼び出し: 256 KBまで
一時ストレージ: 512 MBまで
サーバレスなのでインメモリキャッシュが使えない
特にCSVインポートなどの大容量ファイルをアップロードしてゴリゴリに演算処理をする箇所が耐えられなくなっていました。
移行に際しては、Lambda依存のGoのコード(lambdaHandler周り) をECS用に書き換え、RDS Proxyの排除、インターフェース修正、デプロイパイプラインの変更など、細かい調整を加えました。インフラの大胆な構成変更も行いました。
このリプレースにより、ECSによる安定した手堅いAPIサーバーを提供できるようになりました。
toCのメディアのようなシステムでは、Lambdaのスケーラビリティが大活躍しますが、toBの基幹システムや管理画面など重たい処理が多数走るようなシステムではECSの方が向いていると思いました。
プロダクトの成長フェーズというより、用途に応じた使い分けが重要だと学んだ一件でございました。
Amplify + GitHub Actionsによるマルチテナント運用

toB向けSaaSにおいて、企業の商品ページ(以下、LP) をデフォルトのUIではなく、柔軟にカスタマイズしたいというニーズが出てきました。WordPressにあるような制作機能をつけるのはtoo muchだったので、一旦はフロントエンドアプリケーションから独立させたLP専用の環境を構築するという意思決定となりました。(制作自体もコーディング担当者が手動で行います)
当初は、CloudFrontにつけているLambda@Edgeで特定の商品IDに応じてページをリダイレクトするという運用をしていましたが、ニーズの高まりを受けて、この運用では限界が来ていたという事情もあります。
業務要件だけ決まっており、あとは技術選定から丸っと任させていただ来ました。
フロントエンドのホスティング先の選定
ECS、CloudFront + S3、Vercelなどいくつかプランはありましたが、
爆速で構築可能
低コストで運用可能
運用の柔軟性はある程度妥協できる(WAFやキャッシュなどのハンドリングは考慮しなくて良い)
できればAWSで完結したい
ということで、Amplifyを採用しました。
この辺りの判断基準として以下のポストで解説しています。
結局、Next.jsのデプロイ先ってどこがメジャーなんだろ。
— りょうま@フリーランスエンジニア (@engineer_ryoma) December 9, 2024
多少高くても無難にいくならECS、
運用の柔軟性は捨てて、爆速で安く作るならAmplify、
工数をかけてでも安く柔軟に運用したいならCloudFront + S3 + Lambda(SSR)
という使い分けの基準はあるけど、どれがマジョリティなのかは不明。
モノレポ、マルチテナント運用を実現するためのディレクトリ戦略
フロントエンドアプリはNuxt.jsで実装されるのですが、管理のしやすさを考慮して、モノレポ・マルチテナントでコード管理をすることにしました。
GitHubリポジトリは1つで、ディレクトリによって企業の資産を分け、それを企業専用のAmplifyにデプロイするという戦略です。
認証やテンプレート化のしやすさを考慮しつつ、フロントエンドエンジニアと議論しながら最適なディレクトリ構成を探求していきました。
Amplifyを初期設定済みで作成するワークフローを構築
GitHub Actionsのworkflow_dispatchを利用し、企業専用のAmplifyアプリを初期設定込みで自動構築するワークフローを実装しました。
企業専用のサブドメインを入力する必要があるので、フォームから必要項目を入力の上、デプロイを手動で開始できるやり方を採用した背景です。
ワークフローでは以下を行います。
Amplify appの作成
GitHubリポジトリとの連携
ブランチの作成
サブドメインをブランチへ紐付け
Basic認証によるアクセス制御
環境変数の設定
差分ベースのビルドの設定
この中で工夫したのが、差分ベースのビルドの設定です。
モノレポ・マルチテナント運用の場合、何も設定をしないとコードpushにより全企業のAmplifyが反応してビルド・デプロイが走ってしまいます。無駄が多いので、理想的には企業のディレクトリに差分があった場合のみ対象のAmplifyのデプロイを走らせたいところです。
これを実現するために、差分ベースでビルド・デプロイを走らせるピッタリな仕様がありました。

具体的には、環境変数に
AMPLIFY_DIFF_DEPLOY = true
AMPLIFY_DIFF_DEPLOY_ROOT = 企業のディレクトリ
を設定するだけで、Amplifyがディレクトリの差分を監視して、ビルド・デプロイを行うようになります。(Amplify最高!)
ドキュメント作成とハンズオンによる運用の定着化
最後に、カスタムLPの運用手順をマニュアル化し、初回構築時にはハンズオンサポートを行うことで、誰でもスムーズに構築フローを回せる体制を整えました。
Amplifyはこれまでも使ってはいましたが、こんなにも強力な機能が揃っているとは知らず、改めてその威力に驚いた一件でした。今後もさらなる進化に期待しています。
履歴一覧のパフォーマンス改善 10s → 50ms

ユーザーの行動履歴を取得するAPIのパフォーマンスが10s以上かかるという課題があり、さらに対象のユーザーの履歴が0件でも遅くなっていくという状態でした。
行動履歴はDynamoDBで管理しています。
グローバルセカンダリインデックスはしっかり作成されていました。
パフォーマンス悪化の原因
DynamoDBから履歴データを取得する際に、カーディナリティの低い条件(企業 × レコード種別) で検索を行い、メモリ上でさらなるフィルタリングを行う処理になっていました。
ユーザーの履歴が0件でも重くなっていたのは、企業単位で全データを取得していたためです。
対応方針
ユーザーIDを含むグローバルセカンダリインデックスを使うようにしてデータの取得を行うように変更しました。
結果
履歴一覧APIのレイテンシが10s → 54ms に改善しました。

特にこの履歴APIは複数のAPIから呼ばれるマイクロサービスのAPIだったため、かなりインパクトの大きい改善につながりました。
一覧系のAPIのパフォーマンスを改善する際にさまざまな手札がありますが、今回はデータストアがDynamoDBということで、カーディナリティの高いグローバルセカンダリインデックスが効くように検索条件を変えることでパフォーマンスが大きく改善した事例になります。
キャッシュモードと差分モードを組み合わせた、一覧ページ表示速度改善

ある一覧ページについて、以下の条件で表示速度を改善する必要がありました。
Redisにキャッシュされたデータを使うとリアルタイム性にかけるためNG
かといってユーザーに都度、更新ボタンを押してもらうUXもNG
ページングも避けたい
この難しい条件を乗り越えるため、APIにキャッシュモードと差分モードを用意する設計を考案しました。
ざっくりいうと、
初回描写はキャッシュモードで取得し、一旦画面の描写を終わらせる。
遅延読み込みにて、差分モードで取得し、更新のあったオブジェクトに対してDOMの更新を行う
という仕組みです。画像のレイジーロードの手法に近いかもしれません。
シーケンス図で解説
1つ目はキャッシュモード。mode=cacheというクエリパラメータをつけるとこのモードになります。

この動きは単純で、Redisから最新のデータを取得してレスポンスを返すです。レスポンスタイム50ms以下と爆速でレスポンスを返します。
続いて、差分モード。mode=diffというクエリパラメータをつけるとこのモードになります。

ブラウザからリクエストを受けて、API内で以下を実行します。
Redisからキャッシュデータを取得
DBから最新データを取得
キャッシュデータとDBの最新データのdiffを取る
差分があれば、Redisに最新データをセット
ブラウザへは差分のみをレスポンスとして返す
実際にDBへの複雑なクエリを発行するので、こちらは5秒前後かかる低速APIとなります。
差分のみをレスポンスとして返すのが工夫ポイントでして、全最新データを返してしまうと、ブラウザで全てのDOMの更新が走ってしまうのでユーザー体験が損なわれてしまいます。
差分のみをレスポンスとして返すことで、ブラウザではDOMを部分的に更新するだけでよくなり、パフォーマンスが良くなります。
「更新」と一言で言っても、create、delete、updateがありますが、これらを別々のフィールドで表現することでフロント側での制御をしやすくしました。
{
"cached": [], // キャッシュモードの時はここに入る
"created": [], // 差分モードの時の新規作成差分
"updated": [], // 差分モードの時の更新差分
"deleted": [], // 差分モードの時の削除差分
}なお、差分については、Goの go-cmpを使いました。
テストでwantとresultの差分を見るためによく使われるパッケージですが、プロダクトとして使うのはちょっとトリッキーかもなという懸念はあります。あくまで、パフォーマンスは捨ててリアルタイム性を担保するAPIなので、導入の意思決定をしました。
これによってユーザーとしては、
初回描写はキャッシュモードにより、50msでレスポンスが返るため、爆速で表示される。
並行して、差分モードのAPIコールが走り、数秒後にしれっと最新データに更新される。
という体験となり、無限ローディングで待たされるストレスから解放されました。
注意点ですが、このような対応をすると、フロントエンドとしてはキャッシュモードと差分モードどちらを呼べば良いかわからず、認知負荷が高くなります。あらゆる手札を模索しても解が見つからず、最終手段として出した案なので、もっと簡単な案があれば、極力避けた方が良いことは間違いないです。一応、苦肉の策でこういう案もあるかもよという参考程度にとどめてもらえれば幸いです。
DataDog ログ解析ダッシュボードの改善

とあるアプリケーションで、DataDogにログを送っていましたが、UIが見づらく、バックエンドメンバーが活用しきれていないという課題がありました。
そこで、「困ったらこれを見てね!」という全てが揃った調査しやすいダッシュボードを作成し、この課題を解決しました。改善ポイントは以下の通りです。
調査に必要な情報に絞る(実行時刻、ステータス、http method、http path、ログインユーザーID、メッセージ、パラメータ、など)
デフォルトの不要なフィールドを排除
詳細は別画面で見れるようにする
完成図はこんな感じ(モザイクでほぼ何もわからないと思いますが笑)

ダッシュボードの整理により、開発者がログを活用しやすくなり、障害調査やお問い合わせ調査のスピードアップにつながりました。
Fargateスポット導入によるECSコスト削減

ECSのコストが肥大化してきたため、コスト削減施策の一つとしてFargateスポットを導入しました。
Fargateスポットは、EC2スポットインスタンスと似たコンセプトで動作します。AWSのサーバー全体で需要が高まる時間帯には、運が悪いとタスクが突然終了してしまう可能性があります。一方、需要が少ない時間帯は通常通り動作します。このようなデメリットを受け入れる代わりに、通常価格の30%、つまり70%引きでECSを利用できるというものです。
検証環境であれば一時的なコンテナの終了が発生しても大きな問題にはならないので、Fargateスポットを導入してみました。その結果、検証環境におけるECSのコストを月に3万円程度削減することに成功しました。
実際に運用してみた感想ですが、月に1回程度、エンジニアメンバーから「何かサービスが落ちているかも?」と報告があり、「Fargateスポットなので数分お待ちください🙏」というやり取りが発生する程度でした。
開発に支障をきたすほどの頻度でコンテナが終了することはなく、許容範囲内の影響に収まっているかなと思います。
その他コスト削減施策

その他、複数のコスト最適化施策を実施しました。
具体的には、
Amazon RDSに対してReserved Instance (RI)を購入
Amazon ECSのコスト効率化のためにSavings Plansを導入
トラフィックの少ない夜間・週末においては、低負荷サービスのECSタスク数を最小構成の1にスケールダウン (それを行うためのGitHub Actionsのscheduleワークフローの作成)
オーバープロビジョニングされているリソースについては、CloudWatchメトリクスを詳細に分析しながら、パフォーマンスと費用対効果の最適なバランスポイントまでリソースをダウンサイジング
ECR、S3にライフサイクルポリシーを適用して不要なリソースを自動的に削除
プライベートサブネット内からS3、ECRへの通信をNATからVPCエンドポイントへ移行
などなど。
これらの施策により、年間で全クライアント様合計で1,000万円以上のコスト削減を達成することができました。
SREとして、コスト最適化への意識は必須のスキルだと考えています。AWS利用料の削減分は企業の収益に直結するため、今後もCost Explorerを活用したコスト分析、最適化施策の立案・実行のサイクルを継続的に実施していきたいです。
Terraform, Kubernetesによるサンドボックス環境作成
新しい技術の検証や負荷試験を実施する際、自由に作っては壊せる環境が欲しいということでサンドボックス環境の構築をしました。
dev, stage, 本番環境はすでに存在していましたが、
dev環境はフロントエンドがローカルからつなげて開発している手前、簡単にはインフラを変更できない
stage環境もQAの方がリグレッションテストで使っているので無理
本番はもってのほか。
ということで、新環境をつくろうという流れです。
技術的な成長という観点で、個人的にはこのタスクが最大の手応えを感じました。
新しい環境を作るには、当たり前ですが既存の環境がどのように動いているのか完璧に理解しなければいけません。それもあって、この時期はひたすら以下のサイクルを回していました。
既存の構成をくまなくチェック
少しでも理解が怪しいところは記事や書籍でインプット
理解できたら 、TerraformやKubernetesのファイルを少しずつ増やしてapply
接続確認
これを繰り返したことで、既存の構成が手に取るように理解できるようになり、手を動かしたことも相まって飛躍的にスキルが向上したことを感じました。
構築した内容としては以下の通りです。
### Terraform
プロダクトで使用する全てのGoogle Cloudリソース
### Kubernetes
ExternalSecrets、SecretStore、Istio、Ingress、PersistentVolume、 ServiceAccount、StatefulSet、DaemonSet、Deployament、 HorizontalPodAutoscaler、
Argo Rollout、VirtualService、Argo CD、Argo Workflow、その他CRD etc...
これに加え、運用の効率化・コスト削減の一環として以下の対応も入れました。
dev環境のDBインスタンスのデータをサンドボックス環境にdumpするCLIの作成
サンドボックス環境でお金がかかるリソース(GKE, GCEインスタンスとCloud SQL) を夜に自動停止するCronWorkflow
今では、バックエンドメンバーが毎日愛用する環境になっており、大変やりがいのあるタスクとなりました。
Google Managed Prometheus導入。自前のPrometheusを廃止

当初、API単位のリクエスト計測のため、自前でGrafanaとPrometheusを運用していましたが、コストの都合上、PrometheusのStatefulsetでは3日分のメトリクスデータしか保存しておらず、エンプラのクライアント様が求めるオブザーバビリティの要件に対応できないという課題がありました。
そもそもGrafanaの管理画面も使いこなせておらず、形骸化していました・・
そこで、Google Cloud Managed Service for Prometheusを導入し、自前管理から脱却しました。
具体的には、以下を対応しました。
GKEのマネージド コレクションを有効にする
各マイクロサービスでカスタムリソース PodMonitoringを定義
アプリケーション側でPrometheus用のAPIを用意する
MonitoringでPromQLを書いてダッシュボード作成
90パーセンタイルのレイテンシ
1分ごとのリクエスト数
アーキテクチャはざっくりこんな感じ

これにより、最大で24ヶ月間のメトリクスデータを保持できるようになり、長期的にAPIのパフォーマンスを計測できるようになりました。
加えて、リソースの監視がGrafanaの画面から移動したことで運用監視がGoogle Cloudに集約され、メンバーのSLOへの意識が高くなりました。
運用で見るべきページがあちこちに散らばるとどうしても関心の対象外になってしまいますよね・・
Prometheusの自前運用でデータを長期保存できないペインはあるあるだと思うので、同じ悩みを持っている方の参考になれば幸いです。
検証環境へのKubernetesリソースのデプロイを手動によるkubectl applyからArgo CDへ移行

そのプロダクトでは、環境はdev, stage, prodと3つあるのですが、
dev環境のKubernetesリソースへのデプロイがstage、prodとは異なり、GitHub Actions上から手動でkubectl applyしている状態でした。
手順の違いによる認知負荷の問題があったため、Argo CDへの統一を提案し、実施しました。
この時は、まだ想像を絶する苦労があるとは知らずに・・
いざ、蓋を開けてみると、想定外の依存関係や古い設定など、様々な課題が発覚しました。一つ一つライブラリのコードから調べて解決していき、最終的に他の環境と同じくArgo CD経由でデプロイできるようになりました。
思った以上に工数が膨らみましたが、溜まっていた負債を解消でき、非常に良い取り組みになったと思います。
ちょっとした教訓ですが、ぱっと見で簡単に解決できそうな課題でも、歴史を長く知る人しか把握していないパンドラの箱というものがあり、後回しにされているものはそれなりの理由があるんだなと学びましたw
なんとか、リプレースを完遂できて良かったです。
Amplifyにてシステムメンテナンス画面へリダイレクトするCLIツール作成

そのプロダクトでは、1顧客ごとに1つのAmplifyアプリを用意しており、システムメンテナンス時には合計15個前後のAmplifyアプリの設定を手動で変更してリダイレクト設定をしていました。
しかし、クライアント数の増加に伴い、この作業量が増大し、設定ミスによるヒューマンエラーのリスクも高まってきました。
これらの課題を解決するために、全てのAmplifyアプリのリダイレクト設定を一括で行う対話式のCLIツールを開発しました。
このツールでは、対象の環境を入力し、リダイレクト設定を適用するAmplifyアプリのIDを指定すると、そのアプリがシステムメンテナンスモードに切り替わります。さらに、"all"と入力すると、AWSアカウント内の全てのAmplifyアプリの設定が一括で変更されるようにしました。
ターミナルでの対話例↓
実行モードを選択してください。(on: メンテナンスモード, off: メンテナンスモード解除)
ex) on / off (ONにすると、全てのユーザーはアクセスできなくなります) > on
対象の環境を選択してください。
ex) dev / prd > dev
メンテナンスモードにするアプリ名をカンマ区切りで入力してください。AWSアカウントに存在する全てのアプリを対象にする場合は「all」と入力してください。
ex) app1,app2 / all >
メンテナンス期間にリダイレクトするURLを入力してください。
ex) https://help.example.com/maintenance/20241001 > https://help.example.com/maintenance/20241001
aws amplify update-app --app-id xxxxxxxxxx --custom-rules '[{ "source": "/<*>", "target": "https://help.example.com/maintenance/20241001", "status": "302" }]'
aws amplify update-app --app-id xxxxxxxxxx --custom-rules '[{ "source": "/<*>", "target": "https://help.example.com/maintenance/20241001", "status": "302" }]'
aws amplify update-app --app-id xxxxxxxxxx --custom-rules '[{ "source": "/<*>", "target": "https://help.example.com/maintenance/20241001", "status": "302" }]'
上記のコマンドを実行しますか?
yes / no > yesツールの内部では、各環境のAWS認証情報を読み取り、AWS CLIを使ってAmplifyアプリの設定を更新しています。
工夫した点は、既存の設定をスナップショットとしてバックアップしておくことです。これにより、メンテナンス終了後に元の設定に正確に戻すことができ、設定の不整合を防ぐことができます。
加えて、実行前にdry-runとして実行予定のコマンドも標準出力することで、安心感を持って最後のyesを入力できるようにしました。
このCLIツールの導入により、これまで20〜30分かかっていたメンテナンス画面の設定作業が、コマンド一発 1〜2分で完了するようになりました。また、設定ミスによるヒューマンエラーもゼロになり、運用の安定性が向上しました。
Amplify + 自前CloudFront + WAFによるシステムメンテナンス画面表示

前回開発したCLIツールによって、メンテナンス運用はある程度効率化できましたが、新たな要望が出てきました。
メンテナンス中に社内の関係者のみがサービスにアクセスできるようにし、本番環境の確認を行った上でメンテナンスモードを解除したいというものです。
お客様に公開する前に入念なチェックを行うのは当然の要求だと思います。
しかし、Amplify管理のCloudFrontは隠蔽されており、AWSコンソールには表示されないため、WAFを適用できないという大きな制約があります。
なお、2024年12月にAWSから発表があり、Amplifyのファイアーウォール機能がGAされたようです!㊗️ (もっと早く出てほしかった・・)
AmplifyではWAFを適用できないという課題を解決するため、Amplifyの前段に自前のCloudFrontを配置する構成への移行を決断しました。
具体的なアーキテクチャは以下の通り。
before

after

afterでは、自分で作成したCloudFrontを前段に置き、デフォルトのビヘイビアとして、オリジンにはAmplifyが生成したブランチのドメインを指定します。そして、Route 53のサブドメインの向き先を、AmplifyのマネージドなCloudFrontから自前のCloudFrontに変更していきます。
HTTPSの終端は自前のCloudFrontになるため、Certificate Managerで証明書を取得し、各CloudFrontに設定しました。
自前のCloudFrontを前段に置いたことで、貴重な貴重なCloudFrontのコントロール権を獲得し、WAFを適用できるようになりました!(ただWAFを使いたいだけなのにこの仕打ちはあまりにも不憫・・・)
WAFさえつけられれば勝ったようなもの。
全CloudFrontディストリビューションに共通のWAFを作成し、メンテナンス用のルールグループを設定します。メンテナンス時には、指定したIPアドレス以外をブロックし、カスタムレスポンスとして指定のページに302リダイレクトするルールを適用します。
あとはメンテナンス時にルールを作成、解除する時はルールを削除するだけで全サブドメインを一括で切り替えられるようになります。
この移行作業は、Amplifyアプリの数が多いこともあり、DNSの設定を大幅に変更する大規模なプロジェクトとなりました。
特に大変だったのが本番環境への反映です。
夜中の23時から作業を開始し、5時間かけて一つ一つのAmplifyアプリとDNSの向き先を変更していきました。どうしてもダウンタイムが発生してしまうため、最小限に抑えつつ、速やかに移行作業を進めるのは本当に骨の折れる作業でした。しかし、無事に完了したときの達成感は言葉では表せないほどのものでした。
加えて、WAFについては、メンテナンス期間中のみルールが変更されるため、Terraformでの管理が難しい面がありました。Terraformのライフサイクル設定を巧みに使い、メンテナンス期間中であってもterraform planに余計な差分が出ないように工夫しました。
誰もが避けたがる、神経をすり減らすような困難なタスクではありましたが、全てやり遂げたことで、以降はWAFの設定を少し変更するだけで全てのAmplifyアプリをメンテナンスモードに切り替えられるようになりました。
個人的にはこのタスクが今年一年で最も大変だったかなと思っていますw
参考
ストアドプロシージャ × CROSS JOINによる大量テストデータの作成

プロダクトのパフォーマンス向上のために、ボトルネックとなっているスロークエリを特定する必要があり、その下準備として1000万レコード規模の大量のダミーデータを用意することになりました。
ダミーデータを効率的に生成する方法はいくつかありますが、今回はDBに詳しいチームメンバーの助言のもと「CROSS JOIN」という手法でやることにしました。
CROSS JOINを使えば、種データの2乗でレコードを増やすことができます。
例) 3000レコードでCROSS JOINを実行→900万レコード完成。
さらに、CROSS JOINを活用しつつ、MySQLのストアドプロシージャを併用することで、本番の値に近いダミーデータを作成する工夫を行いました。
このプロジェクトを通じて、
普段あまり使わないCROSS JOINという機能を知れたこと
MySQLのストアドプロシージャの柔軟性と強力さを実感することができたこと
が大きな収穫でした。
これまでは、複雑な処理が必要な場合にすぐにアプリケーション側のスクリプトに逃げていましたが、今後はMySQL完結でサクッとデータメンテナンスをやるという手札ができたのは大きいです笑
キーワード検索機能のパフォーマンス改善(FULLTEXT INDEXを廃止)

ある予約一覧ページの検索機能にMySQLのFULLTEXT INDEXを使っていましたが、レコード数の増加(数百万規模)に伴い、スロークエリが多発するようになってしまいました。
具体的には、予約ユーザーの漢字名、ひらがな名、電話番号カラムを繋げたSTORED GENERATEDカラムを作成し、そこにFULLTEXT IDNEXを張っていました。
さらに、このFULLTEXT INDEXが原因でスキーマ変更に1〜2時間かかるようになりました。
FULLTEXT INDEXを効かせたカラムがあると、スキーマ変更時にINSTANT DDL が使えず、テーブルの再構築が走ってしまいます。こうなると数百万件のレコード、およびインデックスを再作成するため、実行時間の増加とリソースの大量消費という辛みが出てきます。こうなるとシステムメンテナンスは必須です。
そこでFULLTEXT INDEXを外し、検索対象カラム(漢字、ひらがな、電話番号)に対してそれぞれ個別に複合インデックスを張るようなスキーマ設計にしました。
予約のデータは、必ず検索対象日時 (from, to) と対象の企業(company_id)と一緒に検索をするので、以下3つの複合インデックスを張りました。
idx_searched_time_company_id_user_name
idx_searched_time_company_id_user_kana_name
idx_searched_time_company_id_user_tel
そして、ユーザーが検索で入力した文字種別(漢字、ひらがな、電話番号) に応じて、使用するインデックスを明示的に指定するようにしました。
MySQLでは、オプティマイザーというものが使用するインデックスをよしなに決定してくれるのですが、複雑なケースだと期待した通りに動作してくれないことがわかりました。そこでUSE INDEXを使って明示的にインデックスを指定することで、高いパフォーマンスを引き出すことができました。
この改善によって、FULLTEXT INDEXを完全に排除でき、スロークエリもなくなり、スキーマ変更の時間も2時間から10分に大幅短縮できました。
このタスクを通しての教訓ですが、FULLTEXT INDEXは、検索エンジンを使わずにサクッと全文検索をできるので、大変便利ではあるのですが、あくまでマスターデータのようなテーブルでの使用にとどめ、プロダクトのメインテーブルなどには使わないことをお勧めします・・・
Goルーチンによる一覧ページ負荷試験ツールの作成

特定の一覧ページに対して負荷試験を行うために、Goルーチンを活用した負荷試験ツールを自作しました。
負荷試験ツールとしては、k6やGatlingなど有名なOSSが数多く存在しますが、今回のテーマはミニマムかつ最速で負荷試験を実行することでした。
前述のOSSはキャッチアップコストがそれなりにかかりますし、複雑なシナリオも不要だったので、ローカルでサクッとツールを作った背景です。
このツールの内部動作は非常にシンプルでして、Goルーチンにより大量のスレッドを立ち上げ、各スレッドにてリクエストを送信する前後の時間を計測します。そして、計測した時間をローカルのCSVファイルに書き出していくというものです。
ローカル環境からの実行でしたが、同時に1万リクエストもの負荷をかけることができたので、サクッと負荷試験をやりたい場合には、このようなシンプルなツールでも十分に役割を果たせるのではないかと感じました。
日次レポート送信バッチ, データ基盤の改修

サービスの利用実績を日次で集計し、S3にアップロードするレポート送信バッチ処理を実装しました。データ自体はBigQueryのデータ基盤から条件に合致するものを一括で取得し、JSONの配列をS3に出力するというよくあるバッチ処理です。
このバッチ処理では、日次レポートに加えて、バックアップとして月次での実行パターンもありました。
日次だとそうでもないのですが、月次の場合、100万件超えの取得となりメモリに収まらないという問題があります。
この課題を解決するために、BigQueryからデータを一括で取得するのではなく、1000件ずつの取得とし、指定のロジックで加工したデータを少しずつtmpファイルに書き出していくアプローチを採用しました。つまり、メモリ上ではなくファイルストレージにデータを蓄積していきます。
この手法により、レポートのデータ件数が数百万件でも、安定してレポートを出力できるようになりました。
加えて、BigQueryのデータマートまで所望のデータを生成するために、dbtを書きまくる経験も得られ、手触り感を持ってデータ基盤周りを改修・デバッグできるようになりました。
バッチ処理なので、メモリを大量に積むという手もありますが、そうするとメモリ使用量の監視体制を整えないといけなかったり、しまいには監視が疎かになり、Out of Memory (OOM) エラーが発生するという事態を何度も経験してきました。過去の苦い経験を活かし、今回はハードウェアのスペックに頼る力技ではなく、ファイル書き出しによる適切な設計で課題を解決できたことは、自分にとって非常に良い経験となりました。
本番リリース運用手順の改善

プレ環境への前日リリースによる、リリース時間の短縮
サービスの成長に伴い、本番リリースにかかる時間が大幅に伸びるというペインが出てきました。
この課題を解決するために、運用改善の提案を行いました。
まず着目したのは、本番環境と並行して存在するプレ環境への前日リリースです。
プレ環境とは、営業担当者がデモで使用する環境で、本番環境と同じDockerイメージのバージョンを使用していますが、データベースやGCPリソースなどのインフラ資産は分離されています。一般的なステージ環境というのも別で存在しており、それよりさらに本番に近いという環境です。
従来は、本番リリースの前にプレ環境へのリリースも行っていたため、作業時間は6時間前後になっていました。
そこで、プレ環境に対してはできるところまで前日にやってみるのはどうか?という提案をしました。
プレ環境のリリース手順を分解すると、
Terraformによるインフラの更新
データベースのマイグレーション
データメンテナンス
releaseブランチへのマージによる最新イメージのbuild
Argo CDによるPodの更新
となっており、3までは事前にできると考えました。
この提案を実行したところ、本番リリースの所要時間が2時間ほど短縮されました。
リリース時間の短縮以上に大きなメリットもありまして、これまで本番リリース前に、プレ環境への terraform apply を行うのですが、そこで初めて気づくエラーにかなりの時間を要していました。
devやstage環境で発生しなかったのに、本番環境へのapplyでエラーが起こるのはTerraform運用あるあるだと思います笑
従来は本番リリース当日に焦りながらデバッグしていましたが、1営業日前のプレ環境リリースでそれらの問題を事前に特定・解決できるようになりました。
この副次的なメリットにより、本番リリース時にはデバッグを終えた状態で安心してterraform applyを実行できるようになりました。
1日前の先行リリースを提案したことで、リリース作業の効率化だけでなく、リリース担当者の精神的な安定にも寄与できたと感じています。
予約数制限機能の設計

このプロジェクトでは、ある重要なクライアントから予約数制限機能の要望があり、それを実現するために工夫を凝らした設計を行いました。
このプロダクトは複数のマイクロサービスで構成されており、予約を作成するAPIは非常に重要な位置づけにあります。デグレは絶対に許されず、ビジネスへの影響も大きいため、慎重に設計する必要がありました。
予約数制限機能の要望は1社からのものでしたが、重要なクライアントなのでなんとか要望に応えたいという背景です。
SaaSを開発する上で避けられないあるあるの悩みかなと思いますw
そこで、BFF(Backend For Frontend)を活用することで、既存のマイクロサービスに影響を与えずに要件を実現する設計を考案しました。
具体的には、BFFから現在の予約を取得するAPIと、時間ブロックを取得するAPIを呼び出し、それらのデータを加工して、各時間ブロックの予約状況を取得するAPIを新たに作成しました。
これにより、特定のクライアントの場合のみ、フロントエンドから新しいAPIを呼び出すだけで、予約数が上限に達しているかどうかを判断でき、超過している場合はエラーを表示できるようになります。
もう1点工夫したのが、要件定義の段階から関与し、非機能要件についてビジネス側と良い着地点を見つけられたことです。
この手の上限機能を開発する場合、本来なら排他制御が必要です。しかし、予約のAPIはコアなロジックを持っているため、特定のクライアントのためだけに排他制御を導入するのはリスクが高いと判断し、ビジネス側と調整してその要件を落とせないか提案しました。
今回は、時間ブロックあたりの予約数が1つ2つオーバーしても全く問題ない要件でした。エンジニアが勝手に排他制御が必要だと思っていても、クライアントからすればそこまで気にしていない、というケースは多々あるので、要件定義の段階でしっかり確認するのは大事だと改めて感じました。
非機能要件を緩められたことで、以下のシーケンスに着地できました。
画面表示の際に、時間ブロック単位の予約数APIを呼んで残数を取得
満席になった場合、セレクトボックスから時間枠を除外
予約作成のボタンクリック後に、フロントエンドから再度、時間ブロック単位の予約数APIを呼んで最新の予約状況を取得
上限を超えていればエラーメッセージを表示
バックエンドでガチガチに守るのではなく、フロントエンドでのバリデーションに留めるという方針です。
全く同じタイミングで送信すれば1つ2つは上限を超えてしまう可能性はありますが、非機能要件ですり合わせ済みなので、この設計で耐えられました。
詳細設計以降は、新卒メンバーに対応いただきました。相手が嫌な気分にならないレビューの仕方や不明点の説明、納期を意識したタイムスケジュールの作成など、マネジメントの観点でも大きな学びのあるプロジェクトでございました。
Cloud Monitoring アラートポリシーの通知内容改善

本番環境でサーバーエラーが発生した際に、Cloud Monitoringのアラートポリシーを使用してSlackに通知する運用をしていました。しかし、通知内容にはログエクスプローラーのリンクがクエリパラメータ付きで貼られているだけで、そのリンクをクリックしてGoogle Cloudのコンソールへ遷移しないとエラーの詳細がわからないという課題がありました。
勤務時間中であればPCでリンクをクリックするだけで済みますが、外出中や休日にスマートフォンで通知を受け取った場合、Google Workspaceの認証を突破しないとエラー内容を確認できないため、心理的なハードルが高くなってしまいます。
この問題を解決すべく、通知内容に
発生したAPIのエンドポイント(method + path)
エラーメッセージ
スタックトレース
を含めるように修正しました。
具体的には、Metricsベースのアラートポリシーからログベースのアラートポリシーに変更することで、通知内容に詳細情報を含められるようになりました。
この改善により、スマホでアラート通知を受け取った際にも、その場ですぐにエラーの概要を把握できるようになり、アラートへの初動を速くすることができました。
一方で、常に通知に敏感になるというブラックな副作用も出てきましたがw
参考
SRE定例の企画

サービスが成長するにつれ、バックエンドチームで以下の課題が出てきました。
言語やミドルウェアのバージョンアップ対応について、特定のメンバーが思い出したタイミングでやっている。そのため、更新漏れがあったり、作業が属人化したりしている。
せっかくリソース監視用のダッシュボードを整えたものの、それぞれが気になった時に見る程度になっており、存在感が薄い。
クラウドのコストについて一部のメンバーだけが関与しており、チーム全体でのコスト意識にばらつきがある。
これらの課題を解決するために、SRE定例なるもの企画し、始動に向けて旗振りを行いました。
この定例会では、以下の3つのパートに分けて議論を進めています。
リソース監視ダッシュボードの確認
全マイクロサービスのレイテンシ監視ダッシュボードの確認
AWSとGCPのコスト分析と考察
ミドルウェアの最新バージョンの確認
各パートは持ち回りで担当者を決め、事前に調査・分析を行ってから定例会で発表するという流れです。
これにより、コストや最新バージョンの確認方法、ダッシュボードの使い方など、チームメンバー全員のリテラシーを高める狙いがあります。同時に、SREに対する意識の向上にも繋がると期待しています。
定例会の運営をスムーズにするため、Notionのテンプレートも作成しました。
まだ始まったばかりの取り組みですが、チームメンバーからの反響は上々です。今後、継続的な改善を重ねることで、より強固なSRE体制を構築していきければと思っています。
まとめ

以上、この1年間で携わらせていただいた数々のプロジェクトの詳細をお伝えさせていただきました。40,000字越えの超大作に最後までお付き合いいただき、本当にありがとうございます。
この記事を書きながら、改めて実感したのは、技術への情熱を共有し、励まし合える素晴らしいコミュニティの存在です。皆様からいただく反応の一つ一つが、新たな挑戦への原動力となっています。
2025年も、より複雑な技術的課題に立ち向かい、その過程で得られる知見や学びを、できる限り丁寧にアウトプットしていきたいと思います。この記事を読んでくださった方々の中から、「よし、自分もチャレンジしてみよう!」と思っていただける方が一人でも増えれば、これ以上の喜びはありません。
最後になりましたが、この1年、本当にありがとうございました。皆様にとって、来る2025年が、さらなる成長と発見に満ちた素晴らしい1年となりますように。
それでは良いお年を!
LINE公式アカウントで質問や感想など募集しています!
この度、LINE公式アカウントを作成しました。Xではパブリックすぎて発信できないような知見を共有する場にできればと思ってまして、興味のある方はぜひLINEで繋がっていただけると幸いです。
技術やキャリアに関するちょっとした意思決定の相談も承っていますので、お気軽にご連絡くださいませ!