
PythonでSpotify2017年トップ100を分析してみた後編

はじめに
今回は音楽配信サービスとして世界的にも有名なSpotifyのデータセットを使用し、2017年のトップ100を分析してみました。今回はKaggleにあった内容をRからPythonに読み換えて、写経してみました。
学習内容
・Top100にランクインした曲、アーティストを分析する
・決定木の可視化に使用したdtreevizの使い方
使用するライブラリ
以下、使用するライブラリとなります。
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
・dtreeviz
決定木を可視化するためのライブラリ
データセット
以下、CSVファイルをこちらからダウンロードしてください。
・data.csv
Spotifyが利用可能な53カ国200位までの2017年日次ランキング
・featuresdf.csv
2017年のSpotifyトップ100曲の詳細データ
Top100の中にアーティスト別に何曲がランクインしたか
アーティスト別にTop100の中に何曲ランクインしているかを表示します。
plt.figure(figsize=(15,8))
ax = sns.barplot(x="index", y="artists", data=df_top_artist[0:10])
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・一番多いアーティストで4曲がベスト100にランクイン
・一番曲がヒットしたアーティストはEd SheeranとThe Chainsmokers
Top100の中でどのアーティストのプレイ時間が長かったか
Top100にランクインしている曲の長さと、ストリーム回数をかけた時間をプレイ時間とします。そのプレイ時間が長かったアーティストを表示します。
df_daily_jpn = df_daily[df_daily["Region"] == "global"]
df_daily_jpn = df_daily_jpn.groupby(["Artist", "Track Name"])[["Streams"]].sum()
df_feature_for_concat = df_feature.set_index(["artists", "name"])
df_top100_jpn = pd.concat([df_feature_for_concat, df_daily_jpn], axis=1, join='inner')
df_top100_jpn = df_top100_jpn.reset_index()
df_top100_jpn["Playing time"] = df_top100_jpn["duration_ms"] * df_top100_jpn["Streams"] / 60000
df_top100_jpn = df_top100_jpn.rename(columns={'level_0': 'artist'})
df_top100_jpn = df_top100_jpn.groupby(["artist"])[["Playing time"]].sum().sort_values("Playing time", ascending=False)
df_top100_jpn = df_top100_jpn.reset_index()
plt.figure(figsize=(15,8))
ax = sns.barplot(x="artist", y="Playing time", data=df_top100_jpn[0:10])
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・1位Ed Sheeran、2位The Chainsmokersが定位置
Top100の曲が2017年を通して何日100以内にランクインしたか
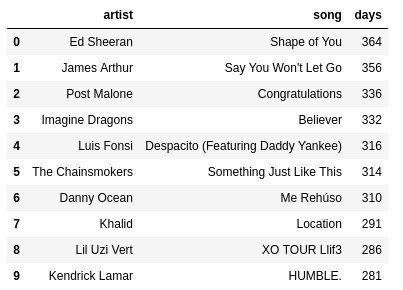
・Shape of Youは100以内に364日ランクインした。一年のうち、一日のみランク外だったという恐るべき記録
2017年Ed Sheeranの曲TOP100デイリーランキング
2017年Ed Sheeranの曲がTOP100デイリーランキングでどのようにランクされたかを表示します。
plt.figure(figsize=(15,8))
ax = sns.scatterplot(x="Datetime", y="Position", data=df_ed_sheeran, hue="Track Name")
ax.set_xlim("2017-01", "2017-12")
ax.invert_yaxis()
ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=18)
・Shape of Youが1月から4月半ばまで首位をキープ
・3月は多くの曲が100位までにランクインしている
・Perfectが9月から段々と順位を上げ、10月にはTop20以内に入っている
曲が持つ特徴の相関関係
曲にはそれぞれ特徴があります。例えば、ダンスのしやすさやエネルギッシュなど。これらの特徴を数値化した値を曲一つ一つが保持しています。

これらの特徴の相関を表示します。
df_only_feature = df_feature.iloc[:, 3:]
corr = df_only_feature.corr()
plt.figure(figsize=(20,10))
sns.heatmap(corr, square=True, vmax=1, vmin=-1, center=0, annot=True)
・energyとloudnessが一番高い相関関係にある
・valence(ミュージカル調)はdanceabilityとloudnessと高い相関関係にある
・speechiness(曲の中にセリフがある)とloudnessは低い相関があり
どのキーの曲がTop100に多いか、または少ないか
plt.figure(figsize=(15,8))
ax = sns.barplot(x="key", y="count", data=df_key, order=df_key["key"])
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
最も一般的なキーはC#, Dbで最も一般的ではないのがD#, Ebとなりました。音楽に疎いものでこれがなにを表しているかがよくわかりませんが。。。
energy、valenceとdanceabilityの相関を密度プロットで表示
energy、valenceとdanceabilityの3つの特徴について密度プロットを使用し、相関を表示します。
plt.figure(figsize=(15,8))
sns.distplot(df_feature["energy"],kde=True,rug=True,label="energy")
sns.distplot(df_feature["valence"],kde=True,rug=True,label="valence")
sns.distplot(df_feature["danceability"],kde=True,rug=True,label="danceability")
plt.title('Density plot of Energy, Valence and Danceability',size=20)
plt.xlabel('Energy, Valence and Danceability')
plt.ylabel('Density')
plt.legend() #実行させないと凡例が出ない。
plt.show()
・値が0~1に収まっている
・分布がほぼ同じとなっている
loudnessの分布
energyとloudnessには高い相関があることがわかりました。これを確認するため、loudnessの分布を表示します。
plt.figure(figsize=(15,8))
sns.distplot(df_feature["loudness"],kde=True,rug=True,label="loudness")
plt.title('Density plot of Energy, Valence and Danceability',size=20)
plt.xlabel('Energy, Valence and Danceability')
plt.ylabel('Density')
plt.legend() #実行させないと凡例が出ない。
plt.show()
・値が大きい曲が多い
・energyの分布と似ている
最も重要な特徴はなにか
どのような特徴を持っている曲のランキングが高くなる傾向になるかを計算します。今回使用した分析手法は決定木分析となります。
そして、決定木を可視化するためにこちらのライブラリを使用しました。
df_only_feature = df_feature.iloc[:, 3:]
array_100 = np.arange(1, 101)
array_feature_value = df_only_feature.values
regr = tree.DecisionTreeRegressor(max_depth=3)
regr.fit(array_feature_value, array_100)
viz = dtreeviz(regr,
array_feature_value,
array_100,
target_name='rank',
feature_names=list(df_only_feature.columns))
viz
・keyが3.5未満、livenessが0.058未満(なぜかここだけ分岐点が表示されていない)、valenceが0.7475以上の場合、順位が高くなる可能性がもっとも高い。
・一方、keyが3.5以上、valenceが0.7325未満、livenessが0.2745以上の場合、順位が低くなる可能性が最も高い。
まとめ
・2017年Ed Sheeranの曲はランキングも上位かつプレイング時間が最も長かった
・Shape of Youは2017通年ずっと上位にランキングされていた
・keyが3.5未満、livenessが0.058未満(なぜかここだけ分岐点が表示されていない)、valenceが0.7475以上の場合、順位が高くなる可能性がもっとも高い。
・keyが3.5以上、valenceが0.7325未満、livenessが0.2745以上の場合、順位が低くなる可能性が最も高い。
参考資料
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。