
Pairsをpythonで分析してみた〜顔写真編〜

今回すること
前回のプロフィールデータ編に引き続き、今回は取得した顔写真の解析を行います。具体的にはFace++のAPIにて写真を読み込み、顔のスコアを取得します。そして、取得したスコアが高いユーザーは多くのいいねを獲得しているかどうかを確認します。
学べること
顔のスコアが高いといいねの獲得数が増えるのか
Face++の使い方
Mask R-CNNの使い方
環境
主に利用したライブラリとなります。
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
・Face++
顔認識API。
・Mask R-CNN
写真に写っている物体についての詳細情報を推測する。
ディレクトリ構成
./
├── pairs_picture -- Pairsから取得した全写真が格納されている
├── not_person -- Mask R-CNNで抽出された顔の写っていない写真が格納されている
└── python
├── face_detection
├── target_file.dump -- Face++で抽出されたデータのdump
Face++とは
中国の企業が開発した顔認識API。無料でAPIを使用することができます。写真から年齢、人種、性別などのデータを推測する。今回はこのAPIを使用し、顔のスコアを算出します。
Face+の使い方
アカウント登録
こちらのフォームに必要な情報を記入し、アカウント登録を完了させます。
API Key取得
アカウント登録完了後、Face++のWebサイトの右上にあるConsoleをクリックします。画面左上にあるApps→API Keyをクリックしてください。以下の画面が表示され、API Keyが確認できます。

写真の解析
ここから、実際にPairsから取得した写真のデータを解析します。以下、使用したコードとなります。詳細については、英語となりますがドキュメントを確認ください。
ポイント
・return_attirbutesに取得したい項目を設定します。例:age, genderなど
・動作が不安定なことがあり、時々処理が途中でストップしてしまうことがあります。そのため、1000件毎にpickleを利用し取得した結果を保存します。
写真選定条件
・写真に一人の顔のみ写っている。(写っていないものはもちろん対象外。二人以上の場合はどちらがユーザーか判断できないため)
・サングラスをしていない
・少なくとも片方の目が写っている
・少なくとも片方の目が開いている
・顔の目より上が写真のフレーム外に飛び出していない
import requests
import base64
from collections import defaultdict
from pathlib import Path
import pickle
endpoint = 'https://api-us.faceplusplus.com'
face_dict = defaultdict(str)
src = sorted(Path('/home/r/pairs_picture').glob('org*/*.jpg'))
for i, file in enumerate(src):
print("{}:{}".format(i,file))
img_file = base64.encodestring(open(file, 'rb').read())
response = requests.post(
endpoint + '/facepp/v3/detect',
{
'Content-Type': 'multipart/form-data',
'api_key': "UmDY8643OxCLfQMy5Zerh6qdP8SoZlH8",
'api_secret': "tr1ncBBBjiOxUgOidvs-rRm3hbGfLeIL",
'image_base64': img_file,
'return_attributes': 'gender,age,headpose,facequality,eyestatus,emotion,ethnicity,beauty,mouthstatus'
}
)
try:
result = response.json()
if len(result["faces"]) != 1:
continue
if result["faces"][0]["attributes"]["mouthstatus"]["surgical_mask_or_respirator"] >= 90:
continue
if result["faces"][0]["attributes"]["glass"]["value"] == "Dark":
continue
if result["faces"][0]["attributes"]["eyestatus"]["left_eye_status"]["occlusion"] >= 90 or target_pictures[i]["faces"][0]["attributes"]["eyestatus"]["right_eye_status"]["occlusion"] >= 90:
continue
if result["faces"][0]["attributes"]["eyestatus"]["left_eye_status"]["no_glass_eye_close"] >= 90 or target_pictures[i]["faces"][0]["attributes"]["eyestatus"]["right_eye_status"]["no_glass_eye_close"] >= 90:
continue
if result["faces"][0]["attributes"]["eyestatus"]["left_eye_status"]["normal_glass_eye_close"] >= 90 or target_pictures[i]["faces"][0]["attributes"]["eyestatus"]["right_eye_status"]["normal_glass_eye_close"] >= 90:
continue
if result['faces'][0]['face_rectangle']['top'] <= -55:
continue
face_dict[file.name[:-4]] = result
except:
print("{}:{}でエラーが発生".format(i,file))
if i % 1000 == 0 and i != 0:
with open('/home/r/python/face_detection/target_file.dump', 'wb') as f:
pickle.dump(face_dict, f)defaultdict(str,
{'772_2': {'image_id': 'GVClzJvQkoBglvdgGYqkdg==',
'request_id': '1538978287,0a217b33-7816-4012-b56a-54971ba37a2a',
'time_used': 385,
'faces': [{'attributes': {'emotion': {'sadness': 0.0,
'neutral': 0.022,
'disgust': 0.0,
'anger': 0.0,
'surprise': 0.0,
'fear': 0.0,
'happiness': 99.977},
'beauty': {'female_score': 51.652, 'male_score': 59.329},
'gender': {'value': 'Female'},
'age': {'value': 36},
'mouthstatus': {'close': 0.178,
'surgical_mask_or_respirator': 0.0,
'open': 99.82,
'other_occlusion': 0.001},
'glass': {'value': 'Normal'},
'headpose': {'yaw_angle': -7.993689,
'pitch_angle': 3.6196244,
'roll_angle': 7.6936493},
'eyestatus': {'left_eye_status': {'normal_glass_eye_open': 99.741,
'no_glass_eye_close': 0.001,
'occlusion': 0.001,
'no_glass_eye_open': 0.214,
'normal_glass_eye_close': 0.043,
'dark_glasses': 0.001},
'right_eye_status': {'normal_glass_eye_open': 98.738,
'no_glass_eye_close': 0.001,
'occlusion': 0.043,
'no_glass_eye_open': 1.138,
'normal_glass_eye_close': 0.079,
'dark_glasses': 0.001}},
'facequality': {'threshold': 70.1, 'value': 84.102},
'ethnicity': {'value': 'ASIAN'}},
'face_rectangle': {'width': 66,
'top': 161,
'left': 85,
'height': 66},
'face_token': 'ddc6e655e2d0fdfe871b3da964fccf5b'}]}pickleを読み込む
with open('/home/iwata/python/face_detection/target_file.dump', 'rb') as f:
target_pictures = pickle.load(f)一番スコアが高い写真のスコアを抽出
顔のスコアは'beauty': {'female_score': 51.652, 'male_score': 59.329}と、男女別のスコアが表示されます。男女のスコアの平均を算出し、各ユーザー毎に一番スコアが高かった写真を対象とします。
pre_id = ""
score = 0
score_dict = defaultdict(list)
work_dict = {}
for i, a in target_pictures.items():
before_under_bar = i.find("_")
id = i[:before_under_bar]
if id != pre_id and work_dict != {}:
#idが変わったら、値が一番大きいkeyとvalueを設定
max_kv = max(work_dict.items(), key=lambda x: x[1])
score_dict[max_kv[0]] = round(max_kv[1], 2)
work_dict.clear()
#idが変わるまで辞書に入れる
work_dict[i] = (a['faces'][0]['attributes']['beauty']['female_score'] + a['faces'][0]['attributes']['beauty']['male_score']) / 2
pre_id = id
Mask R-CNNで人間が一人しか写っていないかを確認
Face++を利用して顔認識を実施しても似顔絵やアートなど実際の人間の顔でないものまで抽出してしまいます。なので、他ツールを使って更に人であるかをチェックすることとしました。そこで使用したのがこのMask R-CNNです。
Mask R-CNNとは
物体検出の手法。これを使うことによって、写真に写っている物体が何かを特定します。詳細はこちらを参照。
Mask R-CNNをインストール
インストールにつきましては、こちらを参照。
物体検出
Githubからインストールしたリポジトリdemo用のipynbファイルがあります。こちらを流用し、"Run Object Detection"のコードを以下のように修正しました。Face++で抽出したファイルをMask R-CNNで確認し、人間が写っていないデータをnot_personディレクトリに移動させます。
ポイント
・現行のソースコードだと白黒画像を読み込むとエラーとなります。理由は3次元前提しているからのようです。白黒画像は2次元の配列となります。そのため、白黒画像の場合は1次元追加してあげる必要があります。
・detectで取得したクラスの中に"person"が含まれているかを確認します。写真に人が一人でも写っていればクラスの中に"person"が含まれます。含まれていない写真は取り除きます。
from pathlib import Path
import shutil
src = sorted(Path('/content/drive/pairs_picture/').glob('*.jpg'))
for i, file in enumerate(src):
print("{}:{}".format(i, file))
image = skimage.io.imread(str(file))
#白黒画像の場合、次元を追加する
if image.ndim == 2:
image = image[..., np.newaxis]
results = model.detect([image], verbose=1)
r = results[0]
#取得した結果のラベルに1(人)が含まれていない写真を抽出する
if not np.any(r['class_ids']==1):
shutil.copy(str(file), "/content/drive/not_person/")目視確認
Mask R-CNNを使用しても、実際の人間の顔でないものが検出されてしまうことがあります。ここまで来ると数も多くないかと思います。目視で確認し、対象としないファイルはnot_personディレクトリに移動させます 。
スコアの対象とする写真を決定する
Mask R-CNNと目視で抽出したファイルは対象外となります。よって、dumpファイルからこれらのデータを排除します。排除後、再度上記の物体検出〜目視確認を繰り返し、スコアの対象とする写真を決定します。
芸能人のフェイススコアを確認
そもそもユーザーAはスコア70点!と言われても、ピンとこないかと思うので、女性芸能人を数人ピックしてスコアが何点になったかをご紹介してみたいと思います。
北川景子
"female_score": 88.219, "male_score": 86.143

長澤まさみ
"female_score": 84.52, "male_score": 81.401

桐谷美玲
"female_score": 79.489, "male_score": 79.815

井川遥
"female_score": 75.017, "male_score": 74.709

ブルゾンちえみ
"female_score": 69.097, "male_score": 63.012

尼神インター 誠子
"female_score": 60.984, "male_score": 61.611

スコアとgoodを持ったデータフレーム作成
mysqlに格納されている前回の記事でも使用したデータを取り出します。そのデータと今回作成したデータを結合します。
df_score = pd.concat([data_from_pairs, data_from_pictures], axis=1, join="inner")スコアのヒストグラム
スコアのヒストグラムを表示します。結果、Pairsの女性ユーザーのスコアは60-70点台が多いようです。
sns.distplot(df_score["score"], kde=False, rug=False, bins=10) 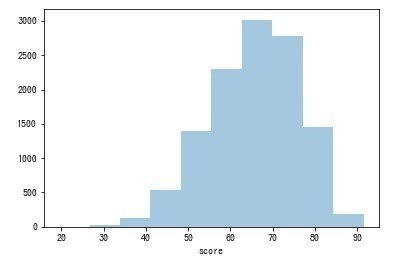
いいね - スコア
100~500以上のいいねを獲得したユーザーのスコアに差異はほとんどありません。しかし、0~99いいねを獲得したユーザーと100以上を比較すると、顔のスコアに差異が見られます。もし、あなたが少しでも美人とマッチングしたいと願うなら100以上のいいねのユーザーを対象とすることで時短ができるかもしれませんね。
df_len = df_len.sort_values(['good_range']).reset_index(drop=True)
ax = sns.barplot(x='good_range', y='score', data=df_len)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)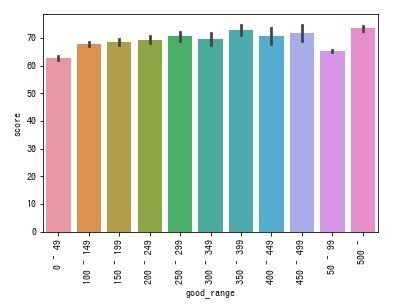
まとめ
いいねが100以上のユーザーのスコアは高い傾向にある。
Face++使用すると写真に写っている顔から顔のスコア、年齢、性別などを簡単に取得できる。
Mask R-CNN物体検出を簡単に実行するできる。
課題
ざっとハイスコアが算出されたユーザーを確認すると写真が
・snow
・プリクラ
のユーザーが多数確認されました。こちらのブログを参照し、それらの写真も対象からはずすようにトライしました。しかし、結果としてうまく判定モデルが作成できなかったため、今回は断念しました。
さいごに
もし、このデータとこのデータを組み合わせて関係を調べてみたらおもしろそうじゃないというご意見、もしくはこれはこうしたほうが良いというご指摘等ありましたらご連絡ください。
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。