
Tinderをpythonで分析してみた〜顔写真編〜

今回すること
前回のプロフィールデータ編に引き続き、今回は取得した顔写真の解析を行います。具体的にはFace++のAPIにて写真を読み込み、顔のスコアを取得します。そして、取得したスコアが高いユーザーは多くのいいねを獲得しているかどうかを確認します。
学べること
・スコアはどの値が多いか、または少ないか
・どの都市の顔のスコアが高いか
・どの地域に顔のスコアが高いユーザーがいるか
環境
主に利用したライブラリとなります。
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
・Face++
顔認識API。
対象データ
性別:女性のみ(男性のデータまで分析すると時間がかかるため、今回は女性のみとしました)
年齢:制限なし
対象都市:
全44都市
アジア:東京、ソウル、香港、シンガポール、バンコク、クアラルンプール、ジャカルタ、デリー、ムンバイ
北米:ニューヨーク、ロサンゼルス、シカゴ、ワシントンDC、トロント
中南米:メキシコシティ、サンパウロ、ブエノスアイレス、サンティアゴ、ボゴタ
ヨーロッパ:ロンドン、パリ、ベルリン、マドリッド、ローマ、ミラン、チューリッヒ、ジュネーブ、ウィーン、アムステルダム、ストックホルム、コペンハーゲン、オスロ、ヘルシンキ、ワルシャワ、プラハ
ロシア:モスクワ
中東:イスタンブール、ドバイ、テルアビブ
アフリカ:ヨハネスブルグ
オセアニア:シドニー、メルボルン
件数:各都市1000件収集。よって、総データ件数は44,000件
Face++について
Face++を利用して、顔写真のスコアを算出します。
詳細については前回まとめたので、こちらを参照してください。
スコアとプロフィールのデータを結合
mysqlに格納されている前回の記事で使用したデータを取り出します。そのデータと今回作成したデータを結合します。
data = pd.concat([user, face_score], axis=1, join="inner")スコアのヒストグラム
sns.distplot(data["score"], kde=False, rug=False, bins=10)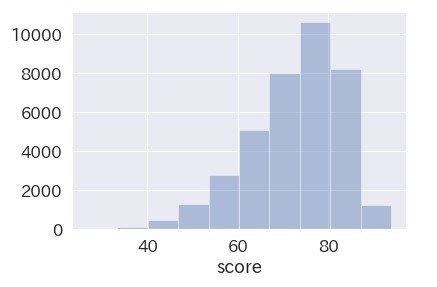
Tinder女性ユーザーのスコアは70-80点台が多いです。
ちなみにPairsの女性ユーザーのスコアは60-70点台が多かったので、Tinderの方が美人が多いようです。
各都市のスコア平均
df_avg = data.groupby(['city']).mean()
df_avg = df_avg.sort_values(['score'], ascending=False)
df_avg = df_avg.reset_index()
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='score', data=df_avg)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・ボゴタ(コロンビア)が堂々の一位。ワールドカップのときも騒がれましたがやはり美人が多い結果となりました。
・アジアでは韓国がトップ。
・二位のドバイは現地人は宗教上の関係でほぼ使用していなさそうです。よって、ドバイに来る移民は顔のレベルが高い。
・東京はほぼ真ん中。可もなく不可。
・スコアが低い都市を見てみると、アメリカの都市が多い。
各地域のスコア平均
以下、各地域のスコア平均となります。(上記の対象データを参照すればおわかりかと思いますが、ロシア、オセアニア、アフリカは含まれる国が一つとなっています。)
df_avg_continent = data.groupby(['continent']).mean()
df_avg_continent = df_avg_continent.sort_values(['score'], ascending=False)
df_avg_continent = df_avg_continent.reset_index()
plt.figure(figsize=(15,8))
ax = sns.barplot(x='continent', y='score', data=df_avg_continent)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・各地域で大きい差はなし
・南米が一番スコア平均が高く、北米(アメリカ、カナダ)はスコア平均が低い
各地域で一番スコアが高かった女性の写真
def concat_tile(im_list_2d):
return cv2.vconcat([cv2.hconcat(im_list_h) for im_list_h in im_list_2d])
#同じサイズでないとタイル状に並べることができないため、サイズを640,640に統一する
im_list = [cv2.resize(x, dsize=(640, 640)) for x in im_list]
#im_listには各都市で一番スコアが高かった写真をcv2.imreadで読み込んだ結果が格納されている
im_tile = concat_tile([[im_list[0], im_list[1], im_list[2], im_list[3]],
[im_list[4], im_list[5], im_list[6], im_list[7]],
[im_list[8], im_list[9], im_list[10], im_list[11]],
[im_list[12], im_list[13], im_list[14], im_list[15]],
[im_list[16], im_list[17], im_list[18], im_list[19]],
[im_list[20], im_list[21], im_list[22], im_list[23]],
[im_list[24], im_list[25], im_list[26], im_list[27]],
[im_list[28], im_list[29], im_list[30], im_list[31]],
[im_list[32], im_list[33], im_list[34], im_list[35]],
[im_list[36], im_list[37], im_list[38], im_list[39]],
[im_list[40], im_list[41], im_list[42], im_list[43]]])
cv2.imwrite('/tmp/opencv_concat_tile.jpg', im_tile)
・すべての写真が各都市のミスにふさわしい女性となっている
・日本と韓国の写真はどれかひと目でわかる
まとめ
・Tinderのユーザーの方がPairsのユーザーより顔のスコアが高い(日本のスコアはそれほど高くないので、海外の女性はより美人が多そう)
・都市ではボゴタが一位、地域で見ても南米が一位。
・北米はスコアが低い。
・日本と韓国は写真の撮り方が他の国と比べてユニーク
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。