
機械学習でAirbnbのデータを分析してみた

はじめに
今回はAirbnbのデータをPython・機械学習を用いて分析してみようと思います。元ネタはMediumにあった英語の記事となります。
データ取得先
Inside Airbnbというサイトにデータセットがありました。こちら、Airbnbが管理しているサイトではなく、ある個人の方が独自にAirbnbからデータを集めてアップしているとのことです。
本来なら一番イメージがつきやすい日本、東京のデータを使用すべきかと思います。しかし、このサイトに日本のデータはありません。なので、今回はベタにニューヨークのデータで分析してみることとします。ちなみに元ネタの方はカナダ・トロント在住のようなのでトロントの分析をしています。
使用するデータ
・listings.csv.gz(2018/12/6収集分)
物件や、その物件を保有しているホストの情報が記載されている
・calendar.csv.gz(2018/12/6収集分)
登録されているリスティングが予約可能か否か、価格がいくらかの情報が記載されている。対象は1年分(2018/12/06〜2019/12/05)
学べること
・カレンダーからどの月の価格が高いか、またはどの週の価格が高いを知ることができる
・登録されている物件の詳細、特徴量の相関を知ることができる
・物件の価格にもっとも影響を与える特徴量を機械学習にて予測し、その特徴量が何かを知ることができる
Calender
では、まずはCalenderの方から見ていきましょう。
calendar = pd.read_csv('calendar.csv.gz')
print('We have', calendar.date.nunique(), 'days and', calendar.listing_id.nunique(), 'unique listings in the calendar data.')![]()
1年分の365日、49056件のリスティングが登録されています。
2018年12/06現在の予約受付可否
calendar.available.value_counts()
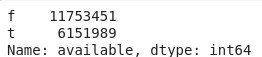
fはFalse(不可)、tはTrue(可能)を表します。よって、約2/3はすでに予約ができない状態になっていることがわかります。
日毎平均予約受付率
calendar_new = calendar[['date', 'available']]
calendar_new['busy'] = calendar_new.available.map( lambda x: 0 if x == 't' else 1)
calendar_new = calendar_new.groupby('date')['busy'].mean().reset_index()
calendar_new['date'] = pd.to_datetime(calendar_new['date'])
plt.figure(figsize=(10, 5))
plt.plot(calendar_new['date'], calendar_new['busy'])
plt.title('Airbnb Toronto Calendar')
plt.ylabel('% busy')
plt.show();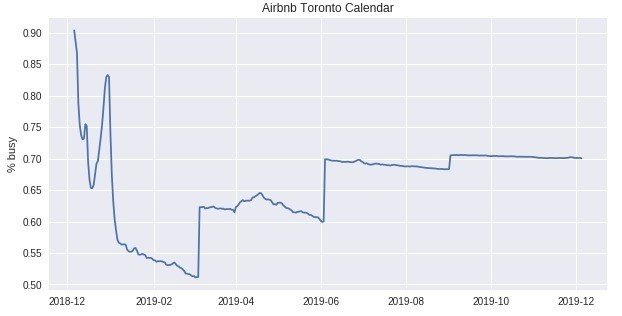
・直近はやはり予約が埋まっている率が高くなっている
・3月頃が一番予約が可能。それでも半分以上は予約を受け付けていない
・6月以降は予約を受け付けていない率が高い。これはホストも先の予定が判明していないため、現状予約ができない状態になっているのではないかと推測される
月毎の平均価格
calendar['date'] = pd.to_datetime(calendar['date'])
calendar['price'] = calendar['price'].str.replace(',', '')
calendar['price'] = calendar['price'].str.replace('$', '')
calendar['price'] = calendar['price'].astype(float)
calendar['date'] = pd.to_datetime(calendar['date'])
mean_of_month = calendar.groupby(calendar['date'].dt.strftime('%B'),
sort=False)['price'].mean()
mean_of_month.plot(kind = 'barh' , figsize = (12,7))
plt.xlabel('average monthly price');
・1月、2月の価格が安い。冬は安い傾向にあるよう。
・その反面、夏が高くなる
週毎の平均価格
calendar['dayofweek'] = calendar.date.dt.weekday_name
cats = [ 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
price_week=calendar[['dayofweek','price']]
price_week = calendar.groupby(['dayofweek']).mean().reindex(cats)
price_week.drop('listing_id', axis=1, inplace=True)
price_week.plot()
ticks = list(range(0, 7, 1)) # points on the x axis where you want the label to appear
labels = "Mon Tues Weds Thurs Fri Sat Sun".split()
plt.xticks(ticks, labels);
・想像通り、金曜日と土曜日が高くなる
・他はそれほど金額に差がない
Listings
ここからは物件の情報を見ていきましょう。
listings = pd.read_csv('/content/drive/Airbnb/listings.csv.gz')
print('We have', listings.id.nunique(), 'listings in the listing data.')![]()
ニューヨークには49056件のリスティングが登録されているようです。
地区毎の総物件数
listings.groupby(by='neighbourhood_cleansed').count()[['id']].sort_values(by='id', ascending=False).head(10)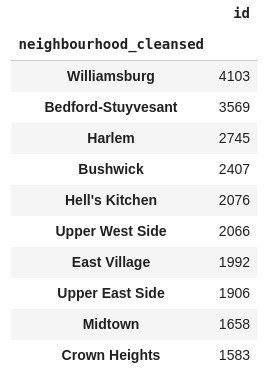
ニューヨークの物件はそれほど地区によって差がないようです。元ネタのトロントと比べてもらうと差が明らかです。
外れ値を除外し、価格の分布を表示
価格が"0"と"600"より大きいレコードを外れ値とし除外します。除外済みのデータを分布を表示します。
listings.loc[(listings.price <= 600) & (listings.price > 0)].price.hist(bins=200)
plt.ylabel('Count')
plt.xlabel('Listing price in $')
plt.title('Histogram of listing prices');

リスティングが100件以上ある地区を対象として、箱ひげ図を表示します。
select_neighbourhood_over_100 = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('neighbourhood_cleansed')\
.filter(lambda x: len(x)>=100)\
["neighbourhood_cleansed"].values
listings_neighbourhood_over_100 = listings.loc[listings["neighbourhood_cleansed"].map(lambda x: x in select_neighbourhood_over_100)]
sort_price = listings_neighbourhood_over_100.loc[(listings_neighbourhood_over_100.price <= 600) & (listings_neighbourhood_over_100.price > 0)]\
.groupby('neighbourhood_cleansed')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='neighbourhood_cleansed', data=listings_neighbourhood_over_100.loc[(listings_neighbourhood_over_100.price <= 600) & (listings_neighbourhood_over_100.price > 0)],
order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show();
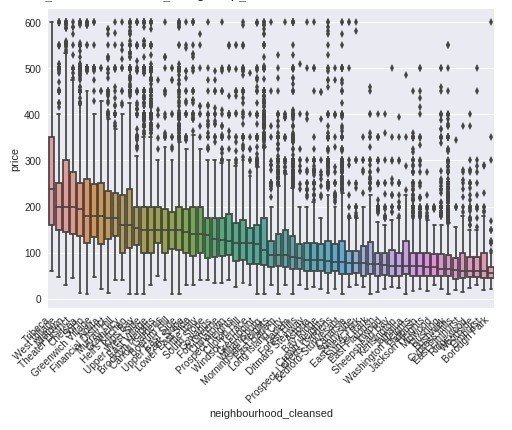
Tribecaという地区の中央値が一番高くなっています。ちなみにWikipediaによると"今日、トライベッカはアメリカで最もファッション性が高く、憧れられる地区の1つであり、セレブが住んでいることで知られる。トライベッカはニューヨーク市内の最も安全な地区になっている"とのことです。おしゃれで安全な場所には高い値がつくということでしょうか。
物件のタイプと価格との関係
select_property_over_100 = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('property_type')\
.filter(lambda x: len(x)>=20)\
["property_type"].values
listings_property_over_100 = listings.loc[listings["property_type"].map(lambda x: x in select_property_over_100)]
sort_price = listings_property_over_100.loc[(listings_property_over_100.price <= 600) & (listings_property_over_100.price > 0)]\
.groupby('property_type')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='property_type', data=listings_property_over_100.loc[(listings_property_over_100.price <= 600) & (listings_property_over_100.price > 0)], order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show();
・リゾート、サービスアパートメント、ホテルの中央値が高い
・villaは別荘のことらしいですが、中央値が低い。私達が連想する別荘とは違うのかも
・ホステルはやはり中央値が低くなっている
部屋のタイプと価格の関係
listings.loc[(listings.price <= 600) & (listings.price > 0)].pivot(columns = 'room_type', values = 'price').plot.hist(stacked = True, bins=100)
plt.xlabel('Listing price in $');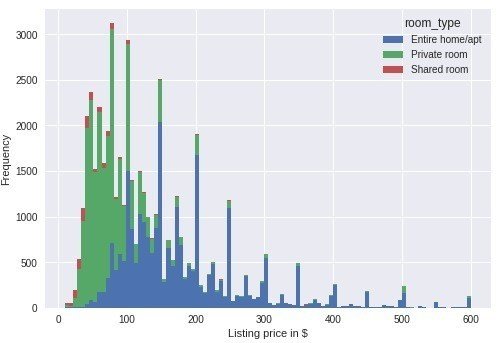
一軒家、アパートすべてを対象とした物件の数が一番多いようです。
アメニティ(部屋の設備)
pd.Series(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))\
.value_counts().head(20)\
.plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show();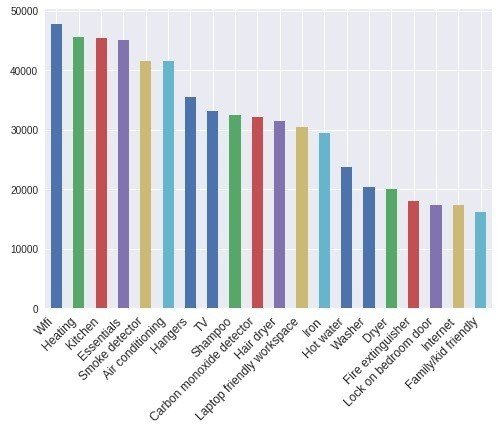
これも上位は順当な結果になってますね。Heating(暖房)が多い結果を見ると、ニューヨークはやはり寒いんだなという印象です。
アメニティと価格の関連
amenities = np.unique(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))
amenity_prices = [(amn, listings[listings['amenities'].map(lambda amns: amn in amns)]['price'].mean()) for amn in amenities if amn != ""]
amenity_srs = pd.Series(data=[a[1] for a in amenity_prices], index=[a[0] for a in amenity_prices])
amenity_srs.sort_values(ascending=False)[:20].plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show();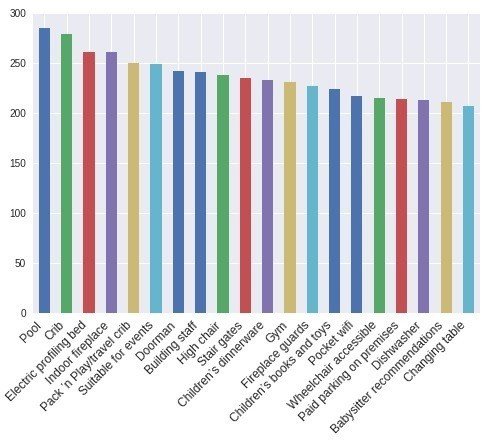
でました、金持ちの象徴のプールは価格との関連が一番高いようです。続いて、Crib(ベビーベッド)。うーん、これについてはよくわかりませんね。理由が気になるところ。
ベッドの数と価格の関連
listings.loc[(listings.price <= 600) & (listings.price > 0)].pivot(columns = 'beds',values = 'price').plot.hist(stacked = True,bins=100)
plt.xlabel('Listing price in $');
・ベッドが一つの物件は安いものから高いものまで多岐に渡る
・ベッド0が意外と目立つ
・最大値はベッド21台。どんな家なんだろうか・・・
select_beds_over_5 = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('beds')\
.filter(lambda x: len(x)>=5)\
["beds"].values
listings_beds_over_5 = listings.loc[listings["beds"].map(lambda x: x in select_beds_over_5)]
sns.boxplot(y='price', x='beds', data = listings_beds_over_5.loc[(listings_beds_over_5.price <= 600) & (listings_beds_over_5.price > 0)])
plt.show();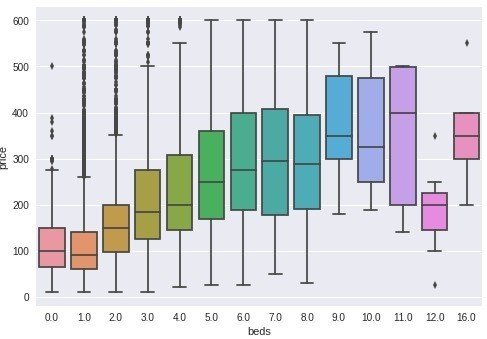
・ベッドの数が増える度、価格の中央値も上昇
・ベッド9~11台ある物件の価格が高い
・12台、16台は11台より価格が低くなっている。大人数が安く泊まるための物件?
数値データをヒートマップで表示
#accommodatesは収容人数
corr = listings.loc[(listings.price <= 600) & (listings.price > 0)][col].dropna().corr()
plt.figure(figsize = (6,6))
sns.set(font_scale=1)
sns.heatmap(corr, cbar = True, annot=True, square = True, fmt = '.2f', xticklabels=col, yticklabels=col)
plt.show();
・価格は収容人数との相関が一番高い
・収容人数とベッドルームの数、ベッドの数に相関がある
物件の価格予測モデル作成
前処理と特徴エンジニアリング
listings['price'] = listings['price'].str.replace(',', '')
listings['price'] = listings['price'].str.replace('$', '')
listings['price'] = listings['price'].astype(float)
listings = listings.loc[(listings.price <= 600) & (listings.price > 0)]アメニティを特徴エンジニアリングを行い数値データに変換
from sklearn.feature_extraction.text import CountVectorizer
listings.amenities = listings.amenities.str.replace("[{}]", "").str.replace('"', "")
## カラム内の単語の出現頻度を数えて、結果を素性ベクトル化する(Bag of words)
count_vectorizer = CountVectorizer(tokenizer=lambda x: x.split(','))
amenities = count_vectorizer.fit_transform(listings['amenities'])
df_amenities = pd.DataFrame(amenities.toarray(), columns=count_vectorizer.get_feature_names())
df_amenities = df_amenities.drop('',1)f(False), t(True)の値を0,1に置換
columns = ['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic',
'is_location_exact', 'requires_license', 'instant_bookable',
'require_guest_profile_picture', 'require_guest_phone_verification']
for c in columns:
listings[c] = listings[c].replace('f',0,regex=True)
listings[c] = listings[c].replace('t',1,regex=True)価格系のカラムをすべてドルマークを消し、nanは0で置換
listings['security_deposit'] = listings['security_deposit'].fillna(value=0)
listings['security_deposit'] = listings['security_deposit'].replace( '[\$,)]','', regex=True ).astype(float)
listings['cleaning_fee'] = listings['cleaning_fee'].fillna(value=0)
listings['cleaning_fee'] = listings['cleaning_fee'].replace( '[\$,)]','', regex=True ).astype(float)次の数値特性を使用します
listings_new = listings[['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic','is_location_exact',
'requires_license', 'instant_bookable', 'require_guest_profile_picture',
'require_guest_phone_verification', 'security_deposit', 'cleaning_fee',
'host_listings_count', 'host_total_listings_count', 'minimum_nights',
'bathrooms', 'bedrooms', 'guests_included', 'number_of_reviews','review_scores_rating', 'price']]
nanを中央値で埋めます
for col in listings_new.columns[listings_new.isnull().any()]:
listings_new[col] = listings_new[col].fillna(listings_new[col].median())カテゴリ変数をダミー変数に変換します。
for cat_feature in ['zipcode', 'property_type', 'room_type', 'cancellation_policy', 'neighbourhood_cleansed', 'bed_type']:
listings_new = pd.concat([listings_new, pd.get_dummies(listings[cat_feature])], axis=1)最後にアメニティと新しく作成したリスティングのデータフレームを結合します。
listings_new = pd.concat([listings_new, df_amenities], axis=1, join='inner')LightGBM
元ネタはランダムフォレストとこのLightGBMで価格決定に重要な特徴量を確認しています。結果がLightGBMの方が良かったため、こちらのみ載せることとします。正直チューニングについてはわかっていないため、これは今後の課題としたいと思います。
from lightgbm import LGBMRegressor
y = listings_new['price']
x = listings_new.drop('price', axis =1)
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state=1)
fit_params={
"early_stopping_rounds":20,
"eval_metric" : 'rmse',
"eval_set" : [(X_test,y_test)],
'eval_names': ['valid'],
'verbose': 100,
'feature_name': 'auto',
'categorical_feature': 'auto'
}
class LGBMRegressor_GainFE(LGBMRegressor):
@property
def feature_importances_(self):
if self._n_features is None:
raise LGBMNotFittedError('No feature_importances found. Need to call fit beforehand.')
return self.booster_.feature_importance(importance_type='gain')
clf = LGBMRegressor_GainFE(num_leaves= 25, max_depth=20,
random_state=0,
silent=True,
metric='rmse',
n_jobs=4,
n_estimators=1000,
colsample_bytree=0.9,
subsample=0.9,
learning_rate=0.01)
clf.fit(X_train.values, y_train.values, **fit_params)
y_pred = clf.predict(X_test.values)
print('R^2 test: %.3f' % (r2_score(y_test, y_pred)))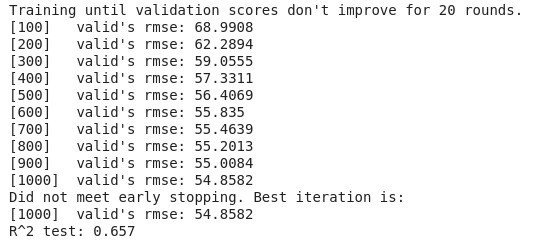
feat_imp = pd.Series(clf.feature_importances_, index=x.columns)
feat_imp.nlargest(20).plot(kind='barh', figsize=(10,6))
・一軒家もしくはアパート全て貸し切りがもっとも重要度が高い
・RMSE誤差が約54.8
・テストデータに対するr2が0.657
まとめ
・コードを写経することは作成者の意図がわかるため、今後も続けていく価値がある
・価格は収容人数との相関が一番高い
・一軒家もしくはアパート全て貸し切りがもっとも物件の価格に対して重要度が高い
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。