
Tinderをpythonで分析してみた〜プロフィールデータ編〜

はじめに
前回のPairsをpythonで分析してみたに引き続き、Tinderをpythonで分析してみました。全3回を予定しており今回はプロフィールデータ編となります。
経緯
日頃からTinderを愛用しているのですが、いかんせんマッチがまったくといっていいほどありません。そこでユーザーのことを知ればマッチをもっと増やすことができるかもしれないと考えに至り、今があります。
問題点
しかし、前回のPairsとは違い、TinderにはユーザーがどれだけLikeを獲得しているかを確認する術がありません。よって、データ分析の結果マッチングを増やすというゴールを設定するのは困難です。
目指すゴール
上記、問題点から今回目指すゴールはシンプルに世界中でTinderを使用しているユーザーを知るということとします。
環境
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・mysql
収集したデータを格納するためのデータベース
・pynder
Tinderのデータを取得するためのAPI
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
データ収集
pynderを利用し、データを収集します。収集したデータをmysqlに格納します。pynderの利用方法についてはこちらを参照ください。
可視化
収集したデータをmatplotlib, seabornを使用して、データの関係性を可視化していきます。全ての項目をグラフにするとかなり冗長になってしまいます。そのため、私の独断と偏見で厳選して紹介します。
対象データ
性別:男女
年齢:制限なし
対象都市:
全44都市
アジア:東京、ソウル、香港、シンガポール、バンコク、クアラルンプール、ジャカルタ、デリー、ムンバイ
北米:ニューヨーク、ロサンゼルス、シカゴ、ワシントンDC、トロント
中南米:メキシコシティ、サンパウロ、ブエノスアイレス、サンティアゴ、ボゴタ
ヨーロッパ:ロンドン、パリ、ベルリン、マドリッド、ローマ、ミラン、チューリッヒ、ジュネーブ、ウィーン、アムステルダム、ストックホルム、コペンハーゲン、オスロ、ヘルシンキ、ワルシャワ、プラハ
ロシア:モスクワ
中東:イスタンブール、ドバイ、テルアビブ
アフリカ:ヨハネスブルグ
オセアニア:シドニー、メルボルン
件数:男女毎に1000件収集。よって、総データ件数は44,000件
すでにお気づきの方もいらっしゃるかもしれませんが、今回上海や北京などの中国のデータは含まれていません。理由は単に取得することができなかったからです。これはおそらく中国でFacebookの使用ができないため、Tinderへの登録が困難であることと推定されます。
平均年齢
稀にユーザーの中に100歳や200歳など実際に登録しているとは思えない年齢のユーザーがいます。そのため、61以上のユーザーはこの統計には加えないこととします。
df_age = data[data['age'] <= 60]
df_age = df_age.groupby(['city', 'gender']).mean()
df_age = df_age.sort_values(['age'], ascending=False)
df_age = df_age.reset_index()
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='age', hue='gender', data=df_age)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・東京男性の平均年齢は27..5歳、女性は24歳となりました。男性は少し高め、女性は高めの結果でした。
・北ヨーロッパは男性の平均年齢が高く、女性は低めです。
・比較的暑い国の平均年齢が低めとなっています。
・ソウルと香港は男女の年齢差が低くなっています。
職業を記入しているユーザーの総数

・東京は男性の記入数は少なめですが、女性は多め。
・女性の職業一位が大学生、二位が学生となります(どちらも職業ではないというツッコミが聞こえそうですが。。。)
・英語圏の都市の記入数が多い
・ソウルが唯一女性のほうが男性より記入数が多い
職業詳細
df_job_content = data[((data['job'] != ""))]
df_job_content = df_job_content.groupby(['job']).size()
df_job_content = df_job_content.reset_index().sort_values(0, ascending=False)
df_job_content = df_job_content[0:9]
df_job_content = df_job_content.rename(columns={0: 'count_job'})
plt.figure(figsize=(15,8))
ax = sns.barplot(x="job", y="count_job", data=df_job_content)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
世界的に見ても一番多い職業は学生となりました。学生って職業なんですね。知りませんでした。
会社詳細
df_job_content = data[((data['job'] != ""))]
df_job_content = df_job_content.groupby(['job']).size()
df_job_content = df_job_content.reset_index().sort_values(0, ascending=False)
df_job_content = df_job_content[0:9]
df_job_content = df_job_content.rename(columns={0: 'count_job'})
plt.figure(figsize=(15,8))
ax = sns.barplot(x="job", y="count_job", data=df_job_content)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)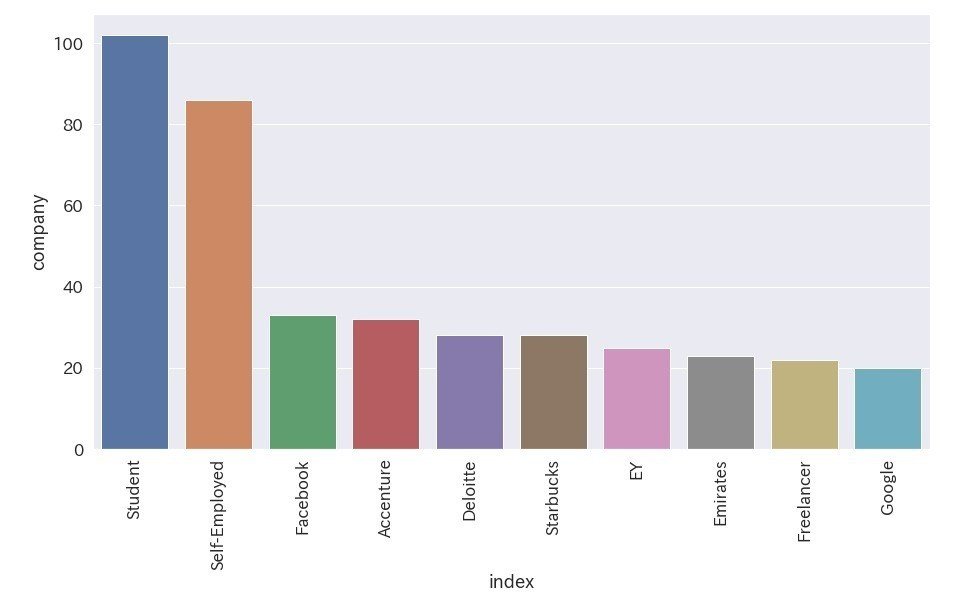
・職業に続いて、会社でも学生が一位となりました。
・Accenture, Deloitte, EYなどコンサルティングファームに勤めているユーザーが多い
・個人的にはFacebookに所属しているユーザーが多いという印象
プロフィール文字数の平均
df_bio = data
df_bio["bio"] = data["bio"].str.replace('?', '')
df_bio["bio"] = df_bio["bio"].str.replace('\n', '')
bio_columns = df_bio.columns[df_bio.columns.str.contains('^city|gender|bio')]
df_len = pd.DataFrame(columns=["city", "gender", "bio", "len_bio", "len_bio_category"])
#1行毎取り出す
for i, row in df_bio[bio_columns].iterrows():
list_append = []
list_append.append(row["city"])
list_append.append(row["gender"])
list_append.append(row["bio"])
list_append.append(len(row["bio"]))
list_append.append(len_bio_category)
df_append = pd.DataFrame([list_append], columns=["city", "gender", "bio", "len_bio", "len_bio_category"])
df_len = df_len.append(df_append)
df_len_bio = df_len
df_len_bio[["len_bio"]] = df_len[["len_bio"]].astype(int)
df_len_bio = df_len_bio[(df_len_bio['len_bio_category'] != "0")]
df_len_bio = df_len_bio.groupby(['city', 'gender'])['len_bio'].mean()
df_len_bio = df_len_bio.reset_index().sort_values('len_bio', ascending=False)
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='len_bio', hue='gender', data=df_len_bio)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・東京は男女共に比較的長めにプロフィールを書いている
・英語圏の都市のユーザーはプロフィールを長めに書いている
・ソウルのみ女性の方が長いプロフィールを書く
プロフィールに身長を記述しているユーザーの総数
df_height = data[data['bio'].str.contains(r'((?i)[4-6][\.\"\'\’\”\,] ?(1\d|\d)(\W|\s)?|[4-6][\.\"\'\’\”\,]? ?(1\d|\d)?(\W|\s)*(feet|ft)|1[\.\"\'\’\”\,m]?[4-9][0-9](\s|\W|cm|m|$))')]
df_height = df_height.groupby(['city', 'gender'])['bio'].size()
df_height = df_height.reset_index().sort_values(["bio", "city"], ascending=[False, True])
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='bio', hue="gender", data=df_height)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・東京は男性の数が多く、女性は標準。
・ソウルはなんと男性400人超えています。40%以上のユーザーが身長を記入していることとなります。大変興味深い結果となりました。
・北ヨーロッパの女性が身長を他の地域と比べ、記入している数多いようです。
登録写真数
photo_columns = data.columns[data.columns.str.contains('city|gender|photo')]
df_photo = pd.DataFrame(columns=["city", "gender", "num_photo", "photo1", "photo2", "photo3", "photo4", "photo5", "photo6", "photo7", "photo8", "photo9", "photo10"])
#1行毎取り出す
for index_org, row in data[photo_columns].iterrows():
#空白、nullを取り除く
removed_space_and_null = [x for x in row if x != ""]
update_photos = removed_space_and_null
update_photos.insert(2, len(removed_space_and_null[2:]))
#update_photosを""でパディング
update_photos[len(update_photos):13] = [""] * (13 - len(update_photos))
df_append = pd.DataFrame([update_photos], columns=["city", "gender", "num_photo", "photo1", "photo2", "photo3", "photo4", "photo5", "photo6", "photo7", "photo8", "photo9", "photo10"])
df_photo = df_photo.append(df_append)
df_photo[["num_photo"]] = df_photo[["num_photo"]].astype(int)
df_num_photo = df_photo.groupby(['city','gender'])['num_photo'].mean()
df_num_photo = df_num_photo.reset_index().sort_values('num_photo', ascending=False)
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='num_photo', hue="gender", data=df_num_photo)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・東京は男女共に写真の登録が少ない。女性はワースト。
・アジアは写真の登録数が男女共に少ない傾向あり。
・英語圏は写真の登録数が多い。
Instagram登録数
TinderはInstagramと連携し、Instagramのデータをプロフィールに載せることができます。しかし、ユーザーによっては連携はせず、プロフィールに自分のIDを載せている場合もあります。以下のグラフはどちらかでもあてはまっているユーザーの総数を表示しています。
df_instagram_bio_column = pd.merge(df_instagram, df_bio_instagram, on=["city", "gender"])
df_instagram_bio_column.set_index(["city", "gender"], inplace=True)
df_instagram_bio_column = df_instagram_bio_column.sum(axis=1)
df_instagram_bio_column = df_instagram_bio_column.reset_index().sort_values(["gender", 0], ascending=[True, False])
df_instagram_bio_column = df_instagram_bio_column.rename(columns={0: 'count_instagram'})
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y="count_instagram", hue="gender", data=df_instagram_bio_column)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・ヘルシンキとイスタンブールは女性の方がInstagramの情報を登録している
・東京の女性はInstagramの情報を記述していないユーザーが多い
・香港は男性と女性ユーザーとの登録数差が大きい
spotify登録しているユーザーの総数
df_spotify = data[data['spotify_theme_artist1'] != ""]
df_spotify = df_spotify.groupby(['city','gender'])['spotify_theme_artist1'].size()
df_spotify = df_spotify.reset_index().sort_values(['spotify_theme_artist1', "city"], ascending=[False, True])
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='spotify_theme_artist1', hue="gender", data=df_spotify)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・地域毎の傾向はないように見える
・登録数が極端に少ない都市はspotifyが利用できない国
男性ユーザーのspotify人気アーティスト
df_spotify_male = data[(data['spotify_theme_artist1'] != "") & (data["gender"] == 0)]
df_spotify_male = df_spotify_male['spotify_theme_artist1'].value_counts()
df_spotify_male = df_spotify_male.reset_index()
df_spotify_male = df_spotify_male[0:10]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='index', y='spotify_theme_artist1', data=df_spotify_male)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・Drakeが一番人気。
・Ariana Grandeが意外にも男性で二番目に人気。個人的に聞いたことがあるのは海外の男性はAriana Grandeのような女性アーティストを聴かないとのこと。もし、女性アーティストの曲を聴いてるいる男性が人がいたら、その人はゲイと思われるからだそうです。しかし、データを見るとその傾向はなさそうに見えます。
女性ユーザーのspotify人気アーティスト
df_spotify_female = data[(data['spotify_theme_artist1'] != "") & (data["gender"] == 1)]
df_spotify_female = df_spotify_female['spotify_theme_artist1'].value_counts()
df_spotify_female = df_spotify_female.reset_index()
df_spotify_female = df_spotify_female[0:10]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='index', y='spotify_theme_artist1', data=df_spotify_female)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・Drakeが男性ユーザーと同じように一位
・DrakeがPost Maloneより2倍多い。女性にとってDrakeがダントツ人気。
地域毎のspotify人気アーティスト
以下、見にくいですが地域(アジア、ヨーロッパなど)毎の人気アーティストを表示します。
df_spotify_continent = data[data['spotify_theme_artist1'] != ""]
df_spotify_continent = df_spotify_continent.groupby(['continent', 'spotify_theme_artist1'])['continent', 'spotify_theme_artist1'].size()
df_spotify_continent = df_spotify_continent.reset_index().sort_values(["continent", 0], ascending=[True, False])
df_spotify_continent = df_spotify_continent.rename(columns={0: 'count_artist'})
g = sns.FacetGrid(df_spotify_continent, col="continent", size=10, sharex=False, col_wrap=4)
def limit_barplot(data, **kws):
sns.barplot(data.spotify_theme_artist1[0:5], data.count_artist[0:5])
g.map_dataframe(limit_barplot)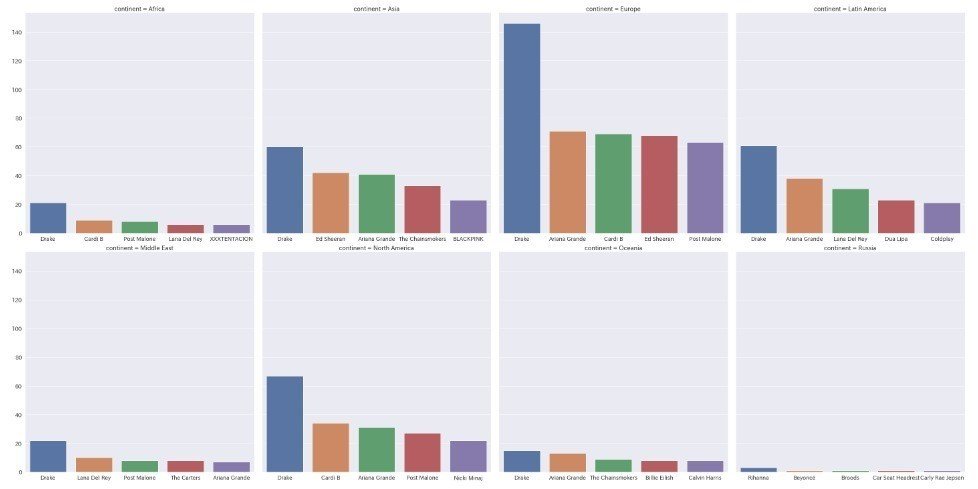
・すべての地域でDrakeが一番人気。Drakeは外国人とトークするために必須のネタと思います。
まとめ
・一番多い職業はStudent
・ソウルの男性の約4割は身長をプロフィールに記述している
・東京の女性は一番Instagramの情報を載せていない
・Drakeが世界で一番人気のアーティスト
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。