
【DataCamp】31_Case Study: School Budgeting with Machine Learning in Python

DrivenDataのBox-Plots for Educationという課題。
データのダウンロードはどうするんだ?と悩みまくりましたが、ググったら出てきました。
Join the competition!を押してログインすると、DATA DOWNLOADが現れます。
やってるうちに目的を忘れてしまいますが、目的は予算の各項目にラベルをつけることです。
ラベルは下記の9つのカテゴリーがあります。
・Function
・Object_Type
・Operating_Status
・Position_Type
・Pre_K(幼稚園前の教育)
・Reporting
・ Sharing,
・Student_Type
・ Use
まず、TrainingData.csvをインポートしてみましょう。120MB超えてて重い…。

ん?DataCampと出力が違うなあ。

400277行もあります!DataCampでは1560行にカットされているみたいです。
列は全部で25個で、Function ~Operating_Status の9列がラベル、Object_Description~Text_1の16列が特徴量です。
ラベルは欠損値がありませんが、特徴量は全ての列で欠損値があります。
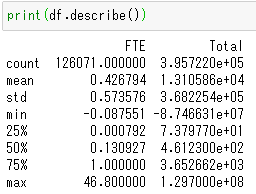
↑数値列の要約統計量。FTEは"full-time equivalent"の略で、その予算項目が被雇用者に関するものであれば、被雇用者がフルタイムで働いている割合を示します。totalは支出の合計額。

objectは23列、float64はFTEとtotalの2列のみです。
機械学習アルゴリズムは数値に対して機能するので、文字列を数値化しないといけません。
pandasにはcategoryというデータ型があり、astypeメソッドでobject→categoryに変換します。category型にすると、pd.get_dummies()関数でダミー変数に変換できます。
ラベルの9列をobject→categoryに変換しましょう。

ここで、pandasのapply()メソッドを使います。DataFrameの軸に沿って、関数を適用します。引数はfunctionとaxis。デフォルトでaxis=0だから、axis=0は書かなくてもいいです。
ラベルの各列が、いくつカテゴリを持つか。

ここで、pandasのnunique()メソッドを使います。指定した軸における、別個の要素の数を数えます。
ラベルは104種類も要素がありました!train_test_splitだと、訓練データに出現しないが、テストデータには出現するラベルもあるでしょう。
StratifiedShuffleSplitというのもありますが、単一の目的変数でしか働きません。
今回は目的変数が多いので、multilabel_train_test_split()を使用します。
数値列のみの特徴量で予測する
数値列のみの特徴量で、multilabel_train_test_split()を使ってみます。


y_trainとy_testのColumnsにあるFunction_Aides Compensation to Operating_Status_PreK-12 Operatingは、Function_Aides Compensation列からOperating_Status_PreK-12 Operating列までの意味。
OneVsRestClassifier(estimator)
One-vs-the-rest (OvR) multiclass strategy.
yの各列を独立に扱う。各列(クラス)ごとに一つの分類器を適合させる。
引数はestimator(推定量)
multiclass(多クラス)は3つ以上のクラス。binary(2クラス)は2つだけのクラス。
よく分からん…。

すごく時間がかかって、デフォルトのソルバーが変わるよ~って警告もでましたが、0.0というスコアが出ました。数値列のみでは予測できないことが分かりました。
予測
![]()
提出形式は、可能性のあるラベルの個々の確率なので、predict_proba()メソッドを使います。
自然言語処理(NLP)
数値列だけでは予測できないことが分かったので、文字列の列も予測に加えます。
まずは、特徴量のPosition_extra列のみに注目してみましょう。この列は、Position_Typeラベルによって捕獲できなかった付加的な情報を記述しています。例として、8960行を見てみましょう。
Object_DescriptionはExtra Duty Pay/Overtime For Support Personnel(サポート要員の残業代)。これは誰に払ったものでしょう?Position_Typeは単にOtherとなっていてよく分かりません。Position_Extraを見ると、BUS DRIVERでした。

Position_extra列のBag of Words

Position_extra列には、385個のトークン(単語)がありました。
公式ドキュメントによると、get_feature_names()は1.2で削除されるので、非推奨だそうです。

vocabulary_属性は、辞書形式で、公式ドキュメントの説明によると
A mapping of terms to feature indices.
(用語の特徴インデックスへのマッピング)この説明だとよく分かりません。
値順に並び替えてみると

値は出現回数ではなく、番号・アルファベット順に振られた番号でした。登場回数はどこで見ればいいのかな???
token_patternを変えてみましょう。上は数字、アルファベットから始まる単語でしたが、今回は全ての非空白文字から始まる単語です。

'&'や'(no', '-'など、記号から始まる単語が増えたので、トークンの数も増えました。
次は、特徴量のすべてのテキストデータの列を使いましょう。BoW表現を計算するために、DataFrameの各行のテキストデータを、単一の文字列に変換しなければなりません。
例として、0行目を見てみましょう。

特徴量のすべてのテキストデータの列を、一つの文字列にします。NaNと数値を除くと、'Teacher-Elementar KINDERGARTEN KINDERGARTEN General Fund' になります。

to_drop = set(to_drop) & set(data_frame.columns.tolist())
これ、必要なんですかね??to_dropそのままでいい気がするんですが。

文字列メソッドjoin?
特徴量のすべてのテキストデータの列を、一つの文字列にしました。上と同様に、0行は'Teacher-Elementar KINDERGARTEN KINDERGARTEN General Fund' になりました。

bow表現を計算すると、3284個のトークンがありました。
Pipeline
pipelineを使ってみましょう。まずは数値列のみで。
欠損値があるとエラーになるので、欠損値を埋めます。上ではテキトーに-1000で埋めましたが、今回はImputerで埋めます。Imputerはデフォルトでその列の平均値で埋めます。
ちなみにImputerはもう使えないみたいです…。

めっちゃ計算に時間かかる…
![]()
結果はやはり0でした。数値列だけでは予測できませんね。
次はテキストデータのみでpipelineを使ってみましょう。

![]()
テキストデータのみは良さそうです。
次回は文字列とテキストデータを合わせましょう。(続く)