【DataCamp】29_Unsupervised Learning in Python③, ④

教師なし学習の後半です。
③Decorrelating your data and dimension reduction
次元削減の最も基本的なPCA(主成分分析)について。非相関と次元削減の2ステップ。
非相関
最初のステップは非相関。PCAはデータサンプルを軸に沿って回転させる。平均が0になるようにサンプルをシフトさせる。
扱うデータセットはwineとgrains。分かりやすいように特徴量は2つだけです。散布図に表せて、主成分も分かりやすい。
-wine
wineのデータセットです。'total_phenols', 'od280'の列をnumpy arrayにして、samplesという名前にします。


変換前

PCAで変換後

変換後は相関係数、平均値共に0に近くなっています。
-grains
grainsのデータセットです。今回、grainsはwidth, lengthの2列だけの (210, 2)のnumpy array。
widthとlengthはどの列か?元データを確認します。
UCI Machine Learning Repository seeds Data Set
スクロールすると、Attribute Informationに5. width of kernel, 4. length of kernelとあります。列が逆になっているのが少しめんどくさい…。


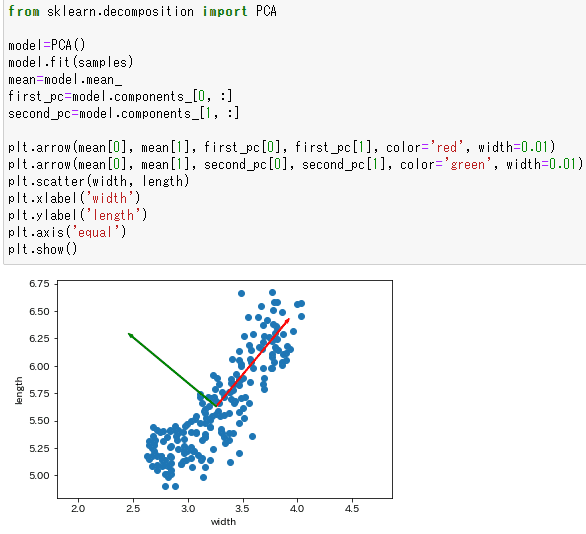
widthとlengthは正の相関があります。PCAを使って相関をなくします。

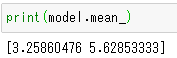
次に、主成分の2軸を矢印で表示しましょう。主成分は下記の通り。第1主成分は[ 0.63910027 0.76912343]、第2主成分は[-0.76912343 0.63910027]。

PCAの.mean_属性は、特徴量ごとの平均値
plt.arrow(x, y, dx, dy)は(x, y)から(x+dx, y+dy)まで矢印を表示します。
第1主成分は赤、第2主成分は緑の矢印で表しました。
次元削減
内在次元とは、データセットを近似するために必要な、分散が大きい特徴量の数。内在次元を調べて、内在次元以外の次元を削除します。
-iris
まず、irisからsepal length, sepal width, petal widthの3つの特徴量を取り出します。

3次元にプロット

z軸(petal length)方向への分散は小さく、sepal lengthとsepal widthの2つの特徴量のみで概算できそうです。
特徴量が2~3の場合、散布図で内在次元を特定できますが、それ以上の特徴量だとどうでしょう?
分散が大きいPCA特徴量を数えることで、内在次元を識別できます。
PCA特徴量の分散を調べます。

最初の2つの特徴量(sepal lengthとsepal width)の分散が大きく、petal lengthは無視して良さそうです。
次は4つの特徴量 'sepal length', 'sepal width', 'petal length', 'petal width'で行います。

特徴量が4つでも、内在次元は2つのようです。
PCAを使用して、次元を2つ減らします。

plt.scatter()の引数、cは文字列ではなく、数値のリストでなければなりません。
次元を4から2に減らしましたが、種を区別することができました。
-fish
こちらは特徴量が6つある6次元。こちらもPCA特徴量の分散をプロットしてみましょう。前半と同様に、標準化します。

あれ???他の分散が表示されない…。
→make_pipelineで引数をpca, scalerとしていました。逆。make_pipelineの引数は、ステップの順番でなければいけません。

fishの内在次元は2が良さそうです。
PCAを用いて、次元削減をします。


次元を6から2に減らしましたが、4種に区別できます。
-documents
documentsは文章のリストです。
documents=['cats say meow', 'dogs say woof', 'dogs chase cats']
これをTfidfVectorizerでcsr_matrix形式で表されるword frequency array(単語頻度配列)に変換します。

-wikipedia
コースのトップページからダウンロードしたWikipedia airticlesフォルダを解凍すると、3つのファイルがあります。

preprocessing.mdはMarkdown Documentationファイルで、メモ帳などのテキストエディタで開けます。開くと、wikipedia-vectors.csvの前処理の仕方が書いてあります。親切!
wikipedia-vocabulary-utf8には、単語がaaronからzooまで13125個あります。
wikipedia-vectors.csvをインポートします。行が単語、列が文書になっています(preprocessing.mdによると、行が文書、列が単語だと、列が長すぎてCSVで扱いづらいため)。

行と列を入れ替えて

csr_matrixに変換。airticlesができました。

titles:文書のタイトル一覧

上位50個の単語。PCAはn_components入力しないと、全ての要素が保持されます。しかし、TruncatedSVDはn_componentsのデフォルトは2。

あれ?第一成分の分散が低い??PCAとは違う??
あと、どの単語に対応しているか分からないかしら?
④Discovering interpretable features
NMFはNon-negative matrix factorizationの略で、日本語だと非負値行列因子分解。factorizeは「因数分解する」という意味。
・次元削減方法
・PCAと違い、解釈可能
・すべてのfeatures(特徴量)は非負(ゼロ以上)でなければならない。適用できるデータは、単語頻度配列や画像、audio spectrogram, e-コマースサイトでの購入履歴など。
・必要なcomponents(成分)の数を指定する
・csr_matrixとnumpy arrayの両方に使える
・PCAの主成分のように、サンプルから学習する成分がある。成分の次元はサンプルの次元と同じ。成分は常に非負。順番はない。
・NMF features(変換されたサンプル)と成分で、元のサンプルを再構築できる。
word frequency arrays(単語頻度配列)
・行が文書、列が単語
・入力値は、文書内でのそれぞれの単語の頻度。tf-idf (term frequency-inverse document frequency)を用いて表される。tfは文書内での単語の頻度。idfは、theなどの頻繁に出てくる単語の影響を減らす、重みづけの方法。
-wikipedia
wikipediaの記事の単語頻度配列を用いて、NMFを適用する。成分の数は6。
先程のcsr matrixのarticlesを用います。
articlesを変換したNMF featuresを、小数点第2位まで表す。
nmf_features.round(2)
→nmf_featuresはnumpy arrayで、numpy.ndarray.roundメソッドを使います。引数は小数位。

articlesを変換したNMF featuresに、文書のタイトルをつけて分かりやすくしましょう。

この中から、'Anne Hathaway'と'Denzel Washington'の行を取り出してみましょう。

df.loc['列名']は列をSeriesで取り出します。


この二人はどちらも、3番目のNMF featuresがかなり高い値です。これは、両方の記事は、主に3番目のNMF成分を用いて再構築される(※)ことを意味します。
※補足説明
NMF成分


NMF成分の3番目×NMF featuresの3番目となるため。
<NMF learns topics of documents>
まず、単語頻度配列(word frequency array)の列名のリストである、wordsを作成します。単語はaaronからzooまで13125個あります。
'wikipedia-vocabulary-utf8.txt' を読み込み

セパレータ(改行コード\n)で分割してリスト化してwordの完成。

先程、'Anne Hathaway'と'Denzel Washington'の両方の記事で、3番目のNMF featuresがかなり高い→主に3番目のNMF成分を用いて再構築されることが分かりました。3番目のNMF成分はどんなtopicsでしょう?
df.nlargest()メソッドは大きい方からn個選ぶ。デフォルトは5個。

これらのtopicsが、'Anne Hathaway'と'Denzel Washington'の両方の記事で共通であることが分かりました。
他の記事も見てみましょう。

0はBlack Sabbath(バンド)、1はRadamel Falcao(サッカー選手)、4はLeukemia(白血病)、5はAlexa Internetでした。


-digit
samplesは(100, 104)の2次元配列で表される、100個の画像。各行は13x8の単一の画像。
数値だけなので、np.loadtxtでインポートします。

samplesの0行目の画像を描画してみましょう。

「7」でした。
他の99個の画像も見たくてfor文に。%matplotlib notebookにすると図が重なって見えないので、%matplotlib inlineにしました。他は0-9の数字かと思いきや、意味をなさない画像が殆どでした。


次はNMFを用いて、このdigitsデータセットを分解します。成分数は7。
wikipediaと同じようにnmf_featuresを見てみましたが、スパースではないので、「○○の行は〇番目のnmf_featuresがすごく高いね~」という発見は特にありませんでした。どれも似た値。

7個の成分を画像にしてみましょう。


「8」を構成する7本の線になりました。だからn_components=7にしたのか~と納得。
ちなみに、n_components=4にすると、数本の線が現れました。
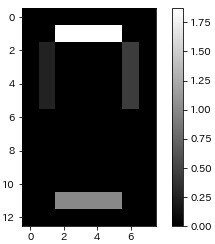
n_components=10にすると、7つは「8」を構成する7本の線に、残り3つは下図のようなグレーになりました。

-artists
<インポート>
まず、csr_matrixのartistsを作ります。
"Musical artists"フォルダを解凍すると、artists.csvとscrobbler-small-sample.csvの2つのファイルがあります。
scrobbler-small-sample.csvは2895x3。列は、user_offset, artist_offset, playcountの3つ。artist_offsetがcsr_matrixのrow, user_offsetがcolumn, playcountがdataのようです。
1行目は列名なので飛ばします。np.loadtxt()のdtypeのデフォルトはfloatなので、dtype='int64'にします。

csr_matrixに変換します。

artistsができました!
artists.csvから、artist_namesも作ります。

最後に空白があったので、削除しました。

<スケーリング>
全てのユーザーが同じ影響力を持つように、スケーリングします。
MaxAbsScaler:各feature(列)の最大絶対値が1を超えないようにするスケーリング。


確かに、最大値は1.0になっています。
スケーリングがややこしいので、表にまとめてみました。

<アーティストをオススメする>

norm_featuresは(111, 20)のnumpy array。アーティストが111名、ユーザーが20名です。
アーティスト名を入れて分かりやすく。

The Beatlesを聴く人は、他に何を聴いているでしょう?

The Beach Boysなどでした。