ネットからデータをインポートする

DataCampのIntermediate Importing Data in Pythonを受講中です。
①Importing data from the Internetを自分でも試してみました。
・データセットをインポートしてローカルに保存する
・pandasデータフレームにロードする
・HTTPリクエストを作成する
・HTMLのようなデータをスクレイピングする
・BeautifulSoupを利用してHTMLを解析してデータに変換する
・urllibとrequestsパッケージ
データセットをインポートしてローカルに保存する
カリフォルニア大学アーバイン校の機械学習リポジトリ(保管場所)。ワインの品質のデータセット
Download : Data Folderをクリックすると、winequality-red.csvやwinequality-white.csvをダウンロードするページが現れる。
クリックしてダウンロードするが、このようなことを1000回も手動でするのは大変。
![]()
ダウンロードしたいファイルがあるURL+ファイル名

urllib.request.urlretrieve(url, ファイル名):URL で表されるネットワークオブジェクトをローカルファイルにコピーする。retrieveは「取得する」という意味。

確かにダウンロードされています!
今度は赤ワインの方をpandas DataFrameにロードし、先頭を表示します。

ちなみにこのファイル、CSVだけれどセミコロン;区切りなんですね。
他にもタブ区切りやスペース区切りもあるそう。
ローカルに保存しないでDataFrameにロードする
pd.read_csv()は第一引数をURLにできます。

ixはlocやilocに似たもので、行や列を指定します。df.ix[: , 0:1]は0列の全行、つまりfixed acidity列を指定しています。

非推奨だからlocやiloc使ってよ!と言われます。なぜDataCampはここでixを使ったのか…。謎。
ちなみにfixed acidityは酒石酸濃度らしいです。
Excel スプレッドシートをインポートする
Excelスプレッドシートのダウンロードはpd.read_excel()を使います。DataCampでは用意された資料だったので、ここでは国連の人口予測のデータをダウンロードしてみましょう。
import pandas as pd
url="https://population.un.org/wpp2019/Download/Standard/Population/WPP2019_POP_F01_1_TOTAL_POPULATION_BOTH_SEXES.xlsx"
xls=pd.read_excel(url,sheet_name=None)
print(xls.keys())あれ?エラー…。
Unsupported format, or corrupt file: Expected BOF record; found b'\r\n\r\n<!DO'

pandasでExcelファイル(xlsx, xls)の読み込み(read_excel)
pandas.read_excel()では内部でopenpyxlとxlrdというライブラリを使っているらしいので、インストールを確認→既にインストールしていた。
調べてみると、ごみが残っているとか難しいので一旦保留。
しかたないので、ローカルに保存して少し遊んでみる。pd.ExcelFile()

ちなみに、列名は17行目、データは18行目から始まります。


parseにもskiprowsがあるので、16行飛ばすと
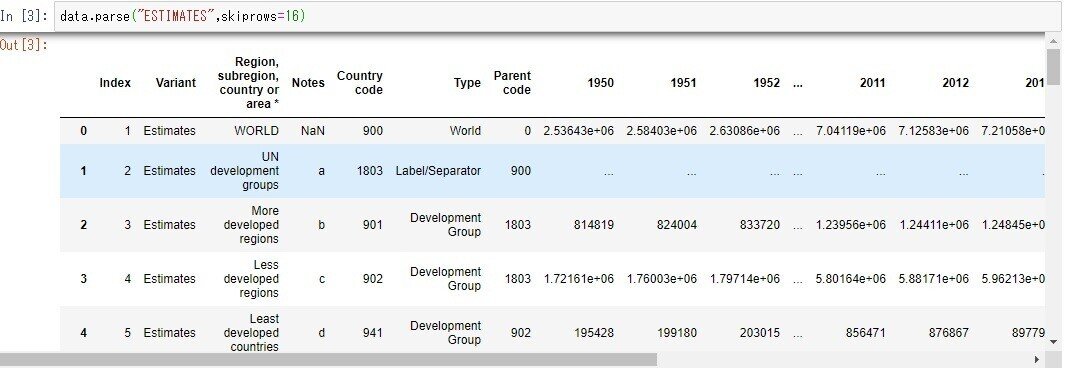
お、いい感じ!
HTMLデータをインポートする
DataCampの例を自分でもやってみます。あれ?またエラー…

Request関数を使用してGETリクエストをパッケージ化し、リクエストを送信して、urlopen関数を使用してレスポンスをキャッチする。これにより、読み取りメソッドが関連付けられたHTTP Responseオブジェクトが返される。次に、この読み取りメソッドを応答に適用します。HTMLを文字列として返し、変数htmlに格納する。そして、応答を閉じる。
url="https://en.wikipedia.org/wiki/Main_Page"とすると、エラーは起こりませんでした。

Requestsモジュールを使う
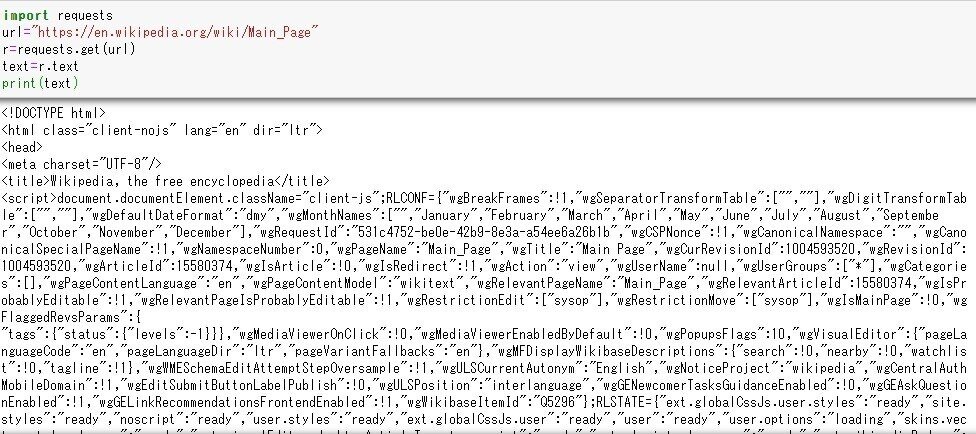
import requests
Requestsパッケージをインポートする。
r=requests.get(url)
URLを指定し、リクエストをパッケージ化し、リクエストを送り、レスポンスをキャッチする。
HTMLを文字列として返す応答にtextメソッドを適用する。
BeautifulSoup
HTMLから構造化データを解析し、抽出する。

r=requests.get(url)ここでも、Requestsモジュールを使用して、webからHTMLをscrape(データなどを取得する)する。
soup=BeautifulSoup(html_doc)
print(soup.prettify())次に、結果のHTMLからBeautifulSoupオブジェクトを作成し、prettify(きれいに飾り立てる)する。出力されたHTMLはインデントされている。
タイトルやテキストを抽出する。

HTML内のハイパーリンクを全て抽出する。
