
Python tkinterを使ってOpenAIで画像を生成させるプログラム④

OpenAI APIの無料トライアル5ドル分を使い切り昨日突然トライアル期間が終了してしまった。このまま手を引こうとも考えたが課金してもう少し学んでいくことにしました。
課金のことを調べるとOpenAIの言語エンジンモデルには3種類あり、それぞれ特徴と使用料が違うことが分かった。このプログラムでは日英の翻訳をOpenAIのAPIで行っているのだが、その翻訳にも課金が必要になってしまう。原稿と翻訳結果は次の通りとなった。

日英翻訳なので当然英語が出力されたのだが、実際どのように翻訳されたのかを検証するためにGoogleの英日翻訳を使って日本語に戻してみました。
まずは最高峰モデルのDavinciから

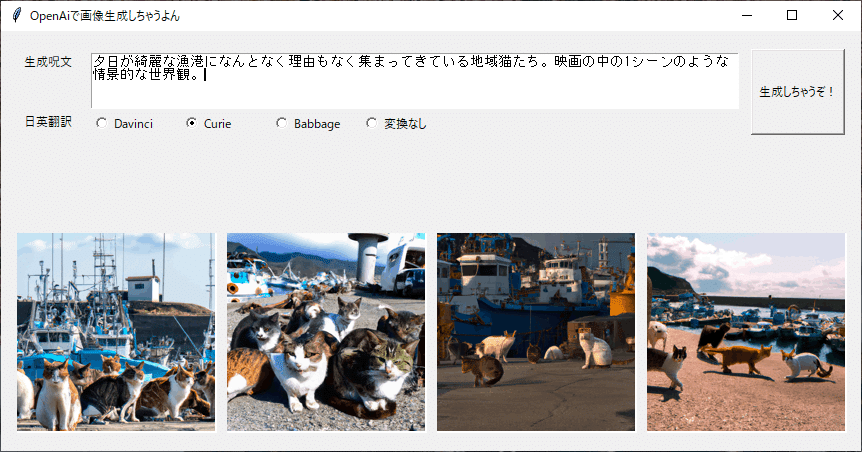
続いてCurieが出力した翻訳結果

最後にBabbage

Davinciは最高峰モデルだけあって美しい翻訳結果だが若干ポエムになっている印象。Curieは及第点でBabbegeはどう見ても落第だ。下馬評通りの結果と言ったところか。
翻訳結果はともあれプログラムを修正して日英翻訳に使う言語モデルを選択可能なものにして画像生成結果を比較することにした。ついでに翻訳はせず直接英文で画像生成するモードも作成し、DeepLツールで予め英語に翻訳した指示文を入力して結果を測定した。
それぞれの結果は次の通り



私の願ったイメージに一番近い出力が得られたのはDeepLでの翻訳結果によるものだった。これを利用しない手はないということで調べたところなんと月間5万文字まで無料で利用できるという誠に太っ腹なAPIがあるではないか!ということでそちらも実装して動かしてみた。

結果はやはり上々でDeepLすげーという感想しかない。OpenAIの言語モデルは有料なのにDeepLは月5万文字まで無料だからこちらを常用したい。
続いてOpenAIの画像生成のオプション機能で指定した画像のバリエーションを作成する機能がある。それを実装してみたところ、これも期待通りの動きとなった。次の2枚の画像で確認してください。


それ以外に画像の一部をマスキングしてAIに生成させた画像を重ね合わせるような機能もあるが画像のマスキング機能とかを実装するのは面倒なので今回は見送ることにした。これで基本機能は完成したと思うので次回以降はもう少し画像生成のアシストになるような機能を追加して行きたい。
今回は新しくDeepLの翻訳機能にアクセスするクラスを追加しました。
# dlcont.py
import deepl
class DeepLController:
api_key = ""
def __init__(self, apiKey):
self.api_key = apiKey
def Translate(self, word):
translator = deepl.Translator(self.api_key)
result = translator.translate_text(word, target_lang="EN-US")
return result.textよく出来たAPIなのでたったこれだけで良いのである。
続いてOpenAIControllerは翻訳メソッドをモデル選択式にして外部から利用できるように公開メソッドに昇格させた。前回まではGenerateImagesメソッドから呼び出されていたが、今回の変更ではその部分は削除した。
# oacont.py
import openai
import base64
class OpenAIController:
model = {}
def __init__(self, apiKey):
openai.api_key = apiKey
self.model[0] = "text-davinci-003"
self.model[1] = "text-curie-001"
self.model[2] = "text-babbage-001"
def TranslateRequestWord(self, word, model):
try:
source_lang = "ja"
target_lang = "en"
prompt = f"Translate from {source_lang} to {target_lang}: {word}"
completion = openai.Completion.create(
engine=self.model[model],
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0
)
return completion.choices[0].text.strip()
except openai.error.RateLimitError as e: raise OpenAIError(f"OpenAI API request exceeded rate limit: {e}")
def GenerateImages(self, word, numberOfImages):
results = {}
try:
response = openai.Image.create(
prompt = word,
n = numberOfImages,
size = "1024x1024",
response_format = "b64_json",
)
for data, n in zip(response["data"], range(numberOfImages)):
img_data = base64.b64decode(data["b64_json"])
results[n] = img_data
return results
except openai.error.RateLimitError as e: raise OpenAIError(f"OpenAI API request exceeded rate limit: {e}")
def GenerateVariations(self, img_data, numberOfImages):
results = {}
try:
response = openai.Image.create_variation(
image = img_data,
n = numberOfImages,
size = "1024x1024",
response_format = "b64_json",
)
for data, n in zip(response["data"], range(numberOfImages)):
img_data = base64.b64decode(data["b64_json"])
results[n] = img_data
return results
except openai.error.RateLimitError as e: raise OpenAIError(f"OpenAI API request exceeded rate limit: {e}")
class OpenAIError(Exception):
pass
コードの通りGenerateVariationsメソッドを追加した。画像データをアップロードしてバリエーション作成を依頼するものです。
最後にメインのoagui.pyだがコントロールが増えたことと機能が増えたことによってコード量が増えています。私がPythonもですがtkinterを使い始めて始めて間もないので公開もためらう程の残念なコードですが次回以降にリファクタリングを進めて行きたいと思います。
※oagui_imagedialog.pyへの前回からの変更はありません
# oagui.py
import tkinter as tk
from tkinter import messagebox
from PIL import Image, ImageTk
from oacont import OpenAIController, OpenAIError
from dlcont import DeepLController
from io import BytesIO
from oagui_imagedialog import ImageDialog
OPENAI_API_KEY = "あなたのOpenAIのAPIキーどすえ"
DEEPL_API_KEY = "あなたのDeepLのAPIキーどすえ"
MODEL_DAVINCI = 0
MODEL_CURIE = 1
MODEL_BABBAGE = 2
MODEL_DEEPL = 3
MODEL_NONE = 4
class Application(tk.Frame):
NUMBER_OF_IMAGES = 4
CANVAS_BASE_X = 14
CANVAS_BASE_Y = 200
cans = {}
variationButtons = {}
originImages = {}
def __init__(self,master = None):
super().__init__(master)
self.pack()
self.model = tk.IntVar()
self.model.set(MODEL_DEEPL)
master.geometry("860x450")
master.title("OpenAiで画像生成しちゃうよん")
self.oac = OpenAIController(OPENAI_API_KEY)
self.dlc = DeepLController(DEEPL_API_KEY)
self.__create_controls()
def __create_canvases(self):
i = 0
while i < self.NUMBER_OF_IMAGES:
can = tk.Canvas(self.master, bg="white", width=200, height=200)
vbtn = tk.Button(self.master, text="バリエーション")
if i == 0:
can.place(x=self.CANVAS_BASE_X, y=self.CANVAS_BASE_Y)
vbtn.place(x=self.CANVAS_BASE_X, y=self.CANVAS_BASE_Y + 204)
elif i == 1:
can.place(x=self.CANVAS_BASE_X + 210, y=self.CANVAS_BASE_Y)
vbtn.place(x=self.CANVAS_BASE_X + 210, y=self.CANVAS_BASE_Y + 204)
elif i == 2:
can.place(x=self.CANVAS_BASE_X + 420, y=self.CANVAS_BASE_Y)
vbtn.place(x=self.CANVAS_BASE_X + 420, y=self.CANVAS_BASE_Y + 204)
else:
can.place(x=self.CANVAS_BASE_X + 630, y=self.CANVAS_BASE_Y)
vbtn.place(x=self.CANVAS_BASE_X + 630, y=self.CANVAS_BASE_Y + 204)
can.bind("<ButtonRelease-1>", self.__canvas_Click)
vbtn.bind("<ButtonRelease-1>", self.__variation_button_Click)
self.cans[i] = can
self.variationButtons[vbtn] = i
i += 1
def __create_controls(self):
tk.Label(text="生成呪文").place(x=20, y=20)
tk.Label(text="日英翻訳").place(x=20, y=82)
self.tbKeyword = tk.Text(width=92, height=4)
self.tbKeyword.place(x=90, y=22)
self.rbModel0 = tk.Radiobutton(self.master, value=0, variable=self.model, text="Davinci")
self.rbModel0.place(x=90, y=80)
self.rbModel1 = tk.Radiobutton(self.master, value=1, variable=self.model, text="Curie")
self.rbModel1.place(x=180, y=80)
self.rbModel2 = tk.Radiobutton(self.master, value=2, variable=self.model, text="Babbage")
self.rbModel2.place(x=270, y=80)
self.rbModel3 = tk.Radiobutton(self.master, value=3, variable=self.model, text="DeepL")
self.rbModel3.place(x=360, y=80)
self.rbModel4 = tk.Radiobutton(self.master, value=4, variable=self.model, text="翻訳なし(英文直接入力)")
self.rbModel4.place(x=450, y=80)
btnA = tk.Button(self.master, text="生成しちゃうぞ!",
command=self.__btnCreate_Click, width=12, height=5)
btnA.place(x=750, y=18)
btnB = tk.Button(self.master, text="結果を全クリア", command=self.__all_clear)
btnB.place(x=16, y=176)
self.__create_canvases()
def __all_clear(self):
for i in range(0, 4):
self.cans[i].delete("photo")
self.originImages.clear()
self.master.update()
def __canvas_Click(self, event):
if(len(self.originImages) == 0): return
can = event.widget
image = self.originImages[can]
ImageDialog.show(self, image)
def __variation_button_Click(self, event):
if(len(self.originImages) == 0): return
index = self.variationButtons[event.widget]
can = self.cans[index]
image = self.originImages[can]
try:
images = self.oac.GenerateVariations(image, self.NUMBER_OF_IMAGES)
except OpenAIError as e:
messagebox.showerror("エラーっす", e)
return
self.__showGeneratedImages(images)
def __btnCreate_Click(self):
images = {}
wd = self.tbKeyword.get("1.0", "end")
if (len(wd) == 1): return
try:
model = self.model.get()
if model == 3:
wd = self.dlc.Translate(wd)
print(wd)
elif model != 4:
wd = self.oac.TranslateRequestWord(wd, model)
images = self.oac.GenerateImages(wd, self.NUMBER_OF_IMAGES)
except OpenAIError as e:
messagebox.showerror("エラーっす", e)
return
self.__showGeneratedImages(images)
def __showGeneratedImages(self, images):
self.originImages.clear()
i = 0
while i < self.NUMBER_OF_IMAGES:
origin = images[i]
self.originImages[self.cans[i]] = origin
img = Image.open(BytesIO(origin)).resize((200, 200))
self.cans[i].delete("photo")
self.cans[i].photo = ImageTk.PhotoImage(img)
self.cans[i].create_image(0, 0, image=self.cans[i].photo, anchor=tk.NW, tag="photo")
i += 1
def main():
win = tk.Tk()
app = Application(master=win)
app.mainloop()
if __name__ == "__main__":
main()