
🧠Haar特徴量 顔認識

Haar-like特徴量は、物体認識に使用されるデジタル画像特徴量である。その名前は、Haarウェーブレットと直感的に似ていることに由来し、最初のリアルタイム顔検出器で使用されました。
歴史的に、画像強度(すなわち、画像の各ピクセルのRGBピクセル値)のみを使用して作業することは、特徴計算のタスクを計算コストの高いものにしていました。
Papageorgiouらは、通常の画像強度の代わりに、Haarウェーブレットに基づく別の特徴セットでの作業について論じています。Paul ViolaとMichael Jonesは、Haarウェーブレットを使用するというアイデアを採用し、いわゆるHaar-like特徴量を開発しました。Haar-like特徴量は、検出窓の特定の位置で隣接する矩形領域を考慮し、各領域の画素強度を合計し、これらの合計の差を計算する。この差分を用いて画像のサブセクションを分類します。例えば、人間の顔の場合、すべての顔の中で、目の領域が頬の領域よりも暗いというのが一般的な観察です。したがって、顔検出のための一般的なHaar特徴は、目と頬の領域の上に位置する2つの隣接する矩形のセットです。これらの矩形の位置は、ターゲットオブジェクト(この場合は顔)のバウンディングボックスのように機能する検出ウィンドウに対して定義される。
Viola-Jones物体検出フレームワークの検出フェーズでは、ターゲットサイズのウィンドウが入力画像上を移動され、画像の各サブセクションについてHaar様特徴が計算される。この差を、非物体と物体を分離する学習された閾値と比較する。このようなHaar-like特徴量は弱い学習器や分類器でしかないため(その検出品質はランダムな推測よりもわずかに優れている)、物体を十分な精度で記述するには多数のHaar-like特徴量が必要です。そのため、Viola-Jonesの物体検出フレームワークでは、Haar-like特徴量を分類器カスケードと呼ばれる方法で整理し、強力な学習器または分類器を形成します。
Haar-like特徴の他の特徴に対する主な利点は、その計算速度です。積分画像を使用するため、どのようなサイズのHaar-like特徴量も一定時間で計算することができます(2角形の特徴量の場合、約60マイクロプロセッサ命令)。
単純な矩形Haar様特徴は、矩形内の領域のピクセルの和の差として定義することができる。この修正された特徴セットは2-矩形特徴と呼ばれる。ViolaとJonesは、3-矩形特徴と4-矩形特徴も定義している。これらの値は、画像の特定領域の特定の特徴を示す。各特徴タイプは、エッジやテクスチャの変化など、画像内の特定の特徴の存在(または非存在)を示すことができる。例えば、2角形の特徴は、暗い領域と明るい領域の間の境界を示すことができます。
ViolaとJonesの貢献の一つは、積分画像と呼ばれる面積和表[3]を使用することであった。積分画像は、元画像と同じ大きさの行列形式の2次元ルックアップテーブルとして定義することができる。積分画像の各要素は、元画像の左上領域(要素の位置に対して)に位置するすべてのピクセルの和を含みます。これにより,4回のルックアップだけで,任意の位置や縮尺における画像内の矩形領域の総和を計算することができます.
各Haar-like特徴は、その定義方法によっては4回以上のルックアップを必要とする場合がある。ViolaとJonesの2-rectangle特徴量では6回、3-rectangle特徴量では8回、4-rectangle特徴量では9回のルックアップが必要である。
Haar特徴ベースのカスケード分類器を用いた物体検出は、2001年の論文「Rapid Object Detection using a Boosted Cascade of Simple Features」でPaul ViolaとMichael Jonesによって提案された効果的な手法である。これは機械学習ベースのアプローチで、多数の正負画像からカスケード関数を学習する。そして、そのカスケード関数を用いて、他の画像内のオブジェクトを検出する。
ここでは顔検出を扱う。まず、このアルゴリズムでは、分類器を学習するために、多くのポジティブ画像(顔の画像)とネガティブ画像(顔のない画像)が必要です。次に、そこから特徴を抽出する必要があります。そのために、下の画像に示すHaar特徴が使われます。これはちょうど畳み込みカーネルのようなものです。各特徴は、黒い四角形の下のピクセルの合計から白い四角形の下のピクセルの合計を引くことで得られる単一の値です。
研究への最初の貢献は、上に示したハール特徴量の導入である。画像上のこれらの特徴により、画像内のエッジや線を簡単に見つけることができ、また、ピクセルの強度が急激に変化している部分を選ぶことができる。
Harr特徴量は積分の応用ですか?
はい、Haar特徴量は積分の一種である積分画像の概念を用いています。Haar特徴量は、画像内の特定の領域の画素値の和を高速に計算するために積分画像を利用します。この手法は主に顔検出などのコンピュータビジョンの応用で使われており、特定のパターンやテクスチャを効率的に識別するのに役立ちます。
カスケード分類器は数式がありますか?
カスケード分類器には、特に一連の弱い分類器を段階的に適用して最終的な判断を行うアプローチに基づく、特定の数式が存在します。一般的には、Viola-Jones アルゴリズムがカスケード分類器の一例であり、特に顔認識タスクでよく使われます。
このアルゴリズムでは、各段階で使用される弱い分類器は、特徴と呼ばれる入力画像の単純な属性に基づいています。各弱い分類器は、その特徴が対象物(例えば顔)を含むかどうかを判断します。これらの分類器は「カスケード」されており、入力画像が各段階を通過するたびにより厳しい判定が行われます。
カスケード分類器の数式の基本は、各弱い分類器の重み付けされた和を取り、その和がある閾値を超えた場合にのみ、次の段階へと進むことです。このプロセスは、すべての段階を通過するか、あるいは途中の段階で画像が対象物を含まないと判断された場合に終了します。
具体的には、カスケード分類器の数式は以下のように表されることがあります。
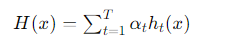
ここで、H(x) は最終的な強い分類器の出力、ht(x) は各弱い分類器の出力、αt は各弱い分類器の重み、T は弱い分類器の総数です。各弱い分類器は、単純な二値判断(例えば、特徴が存在するか否か)を行います。
さて、各カーネルのすべての可能なサイズと位置が、たくさんの特徴を計算するために使われる。(どれだけの計算が必要か想像してみてほしい。24x24のウィンドウでも160000以上の特徴量になる)。各特徴の計算には、白と黒の長方形の下のピクセルの合計を求める必要がある。これを解決するために、彼らは積分画像を導入した。どんなに大きな画像でも、与えられたピクセルの計算をわずか4ピクセルの演算に減らすことができる。いいでしょ?超高速になる。
しかし、私たちが計算したこれらの機能のうち、ほとんどは無関係です。例えば、下の画像を見てみよう。上段は2つの良い特徴を示している。最初に選択された特徴は、目の領域が鼻や頬の領域よりも暗いことが多いという性質に着目しているようです。2つ目の特徴は、目が鼻筋よりも暗いという性質に着目しています。しかし、同じ窓を頬や他の場所に適用しても意味がない。では、どのようにして160000以上の特徴から最良の特徴を選択するのだろうか?それはAdaboostによって達成される。

数学では、Haarウェーブレットは、ウェーブレット族または基底を形成する、再スケーリングされた "方形 "関数のシーケンスである。ウェーブレット解析はフーリエ解析に似ており、区間上の対象関数を正規直交基底で表現することができる。Haar数列は、現在では最初に知られたウェーブレット基底として認識されており、教育の例として広く使われている。
Haar(ハール)は、機械学習に関連しているものの、それ自体が機械学習アルゴリズムではありません。Haarは主に画像処理とコンピュータビジョンにおいて使用される「Haar-like features(ハール様特徴)」や「Haar wavelets(ハールウェーブレット)」を指します。
Haar-like features(ハール様特徴)
Haar-like featuresは、特に顔検出などのタスクに使用される画像特徴量です。これらの特徴量は、ピクセルの輝度値の差を計算することで画像内のエッジ、ライン、四角形などの構造をキャプチャします。例えば、顔の目と周囲の皮膚の違いなどが捉えられます。
Viola-Jones顔検出アルゴリズムは、Haar-like featuresを使用した有名な例です。このアルゴリズムは、多数のHaar-like featuresを用いて画像内の顔を検出します。具体的には、以下のようなプロセスが含まれます:
特徴量抽出:画像からHaar-like featuresを計算します。
積分画像:特徴量計算を高速化するために積分画像を使用します。
Adaboost:重要な特徴量を選択し、重みを調整するためにAdaboostアルゴリズムを使用します。
カスケード分類器:効率的に顔を検出するために、複数の分類器をカスケード状に配置します。
Haar wavelets(ハールウェーブレット)
Haar waveletsは、信号処理や画像圧縮などで使用される数学的手法です。ハールウェーブレット変換は、信号や画像を異なるスケールや位置で分解し、周波数情報を取得するために使用されます。これにより、元の信号をより効率的に圧縮したり、特定の特徴を抽出したりすることが可能になります。
まとめ
Haar自体は機械学習アルゴリズムではありませんが、Haar-like featuresは機械学習アルゴリズム(例えば、AdaboostやSVMなど)と組み合わせて画像処理タスクに使用されることが多いです。また、Haar waveletsは信号処理やデータ圧縮において重要な役割を果たします。
お願い致します