
ElevenLabsで自分の声を学習させて音声スピーチを作成する

[読了目安: 3分]
こんにちは、ロボシンクの矢野哲平(@robothitnk_jp)です。この記事ではTTS(Text to Speech)について解説します。音声で聞きたい方はこちら👇
👨💻対象読者
AIを使って自分の声色に似せた音声を作成したい人
ElevenLabsを触ってみたい人
🎉記事を読むとできること
テキストからスピーチを作成できる(TTS)
自分のAI音声を作成できる
自分のAI音声を作成する場合はクレジットカードと学習用の音声が必要な点にご注意ください。
なお、基本的な利用は無料です。
ElevenLabs
音声系のAIスタートアップです。テキストからスピーチを作成したり、自分の声でAI音声を作成できます。
最近では録音した音声から環境音を除去する技術も発表しました。
Introducing Voice Isolator.
— ElevenLabs (@elevenlabsio) July 3, 2024
Remove unwanted background noise and extract crystal clear dialogue from any audio to make your next podcast, interview, or film sound like it was recorded in the studio.
Try it free: https://t.co/lF4RTkhIxJ pic.twitter.com/GrJHuunLq4
(こんなに環境音が除去されるんか..)
ログイン
会員登録は無料で出来ます。Googleと連携も可能。サクッとログインしましょう。
料金

自分の声を使った音声の作成は$5からできます。$5のスタータープランではインスタントボイスという簡易な学習を試せます。
無料で試す
ElevenLabsは無料でも利用できます。無料の場合は用意されている声を利用します。
メニュー > Speechに移動。発話させたいテキストを入力して音声を選択します。
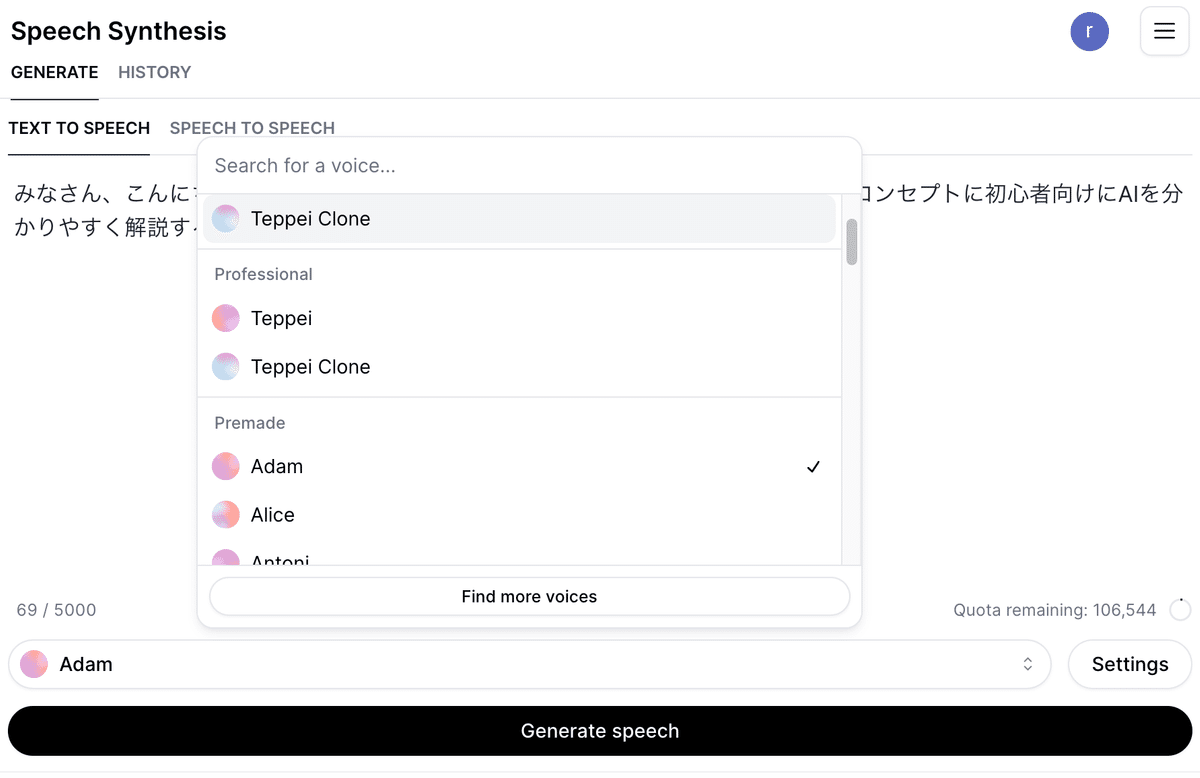
下部にあるGenerate Speechを押すと音声が生成されます。生成したスピーチはダウンロード可能です。
作成した音声👇
Instant Voice
(以降は課金後を想定しています)
メニュー > Voices > Add a new voice > Instant Voice Cloningを選択。

マイクに向かって話すか音声ファイルをアップロードします。環境音を含まないクリアな音声が好ましいとされています。

Record Audioを押すとマイクが起動します。30秒画面に向かって話しかけます。30秒分の台本がない方はこの記事を読み上げに活用してください。
(ポッドキャストでは1分と説明していました。謹んで訂正いたします。)
ちなみにサンプルは25本分アップロードできます。サンプルが多い方が音声の精度も上がります。
出来上がった音声がこちら👇
サンプル1本だと声質はあまり似ていませんね。
上位プランの学習
同じ手順で上位プラン($22)を試してみます。(初月は半額)
メニュー > Voices > Add a new voice > Professional Voice Cloningを選択。

以降の流れはほぼ同じです。異なる点は以下👇
アップロードする音声ファイルは3時間分が目安
テキスト読み上げによる本人確認がある
音声ファイルをアップロードして学習完了まで4時間くらい時間がかかりました。
そうして出来上がった音声がこちら👇
イントネーションが気になるものの声質はほぼ私です。
TTSは長い文章をスピーチ化すると、イントネーションがおかしくなったり破綻が多くなります。
破綻が多い場合はテキストを分割する
漢字の読み間違いがある場合は平仮名にする
色々と工夫していくとより精度が上がります。ぜひ参考にしてください✌️
【note読者限定】生成AIのおすすめツールの資料を配布中
生成AIツールは何を使えばいいか分からない
もっと業務効率化に貢献するツールを知りたい
ChatGPT以外のAIツールを知りたい
こういった声に応えておすすめの生成AIツールを解説する資料を制作しました。もっとAIの情報をキャッチアップしたい人はぜひご覧ください。
👉資料を受け取る
noteでも月に20本ほどAI関連の記事を投稿しています。フォローよろしくお願いします😼