PEZY の実用アプリケーション(小脳シミュレーション)は2009年の研究より小規模で粗く更に遅い

追記(3月18日)
「PEZY の実用アプリケーションは2009年の研究より小規模で粗く更に遅い」に対するコメントへの返答
[Y+17] の筆頭著者(以下著者)から「この記事の内容が不正確で誤っている」とのコメントをいただきました.コメントを頂いたことで,比較に関する理解が深まりました.お礼を申し上げます.
しかし,いただいたコメントはご自身が書かれた論文と整合性がなく,なぜ論文の内容に反するコメントをされたのか,理解できませんでした.
論文の内容が正しければ,コメントは誤りになります.コメントが正しければ,論文は訂正されなければなりません.
著者の論文での見解とコメントの要点
返答する前に,その理由を説明するために必要な,論文 [L+15], [Y+17] の著者(コメントをいただいた方, [Y+17] では筆頭著者)の見解を4点取り上げます.
(1) [Y+17] は実時間で脳をシミュレーションできたが,[K+14] で脳の細胞数が同じシミュレーションをすると,[Y+17] に遠く及ばない計算時間が掛かる,と記述している ([Y+17] 4. Discussion 5段落目)
つまり,[Y+17] と [K+14] の結果は比較できる.
(2) 猫小脳顆粒層シミュレーションの計算時間と猫の小脳全体のシミュレーション [YI13] の計算時間を直接比較している ([L+15] 図11) (直接比較は不適切である,といった注釈はない)
[YI13] は [Y+17] と同一の猫の小脳全体のシミュレーション.
つまり,[L+15] と [YI13] が直接比較できるなら,[L+15] と[Y+17] も直接比較できる.
(3) 顆粒細胞の数が 10^6 程度まで増加しても,猫小脳顆粒層のシミュレーションの計算時間はほぼ変わらないと推定している ([L+15] の図12)
計算時間の推定を著者は論文で行っている.
(4) プロセッサ数の増加による弱スケーリング性のための計算時間を 4, 16, 64, 256, 1024 プロセッサの値から 5, 6, 7 などの間のプロセッサ数に対する計算時間は同様であると推定した) [Y+17] 3.2. Weak scaling property
計算時間の推定を著者は論文で行っている.
そして,著者のコメントの要点は次の3点であると,私は理解しました.
(a) 招待講演の内容は,猫の小脳モデルに限定している.
(b) 猫の大脳皮質モデルのシミュレーションは,猫の小脳モデルではないので,比較対象から除外する(コメント2).
(c) 猫の小脳モデルの顆粒層のシミュレーションは,猫の小脳モデルの一部でしかなく全部ではないので,比較対象から除外する(コメント3).
筆者の招待講演資料「もちろん世界最大,最高速,最も精緻」はこれらの条件によるものです.
著者の論文における見解と著者のコメントの要点は整合しない
要点 (b) は見解 (1) と整合しません.[Y+17] は,猫の大脳皮質モデルのシミュレーションを猫の小脳モデルと比較し,非常に遅いと書いています.ニューロン数という単一の基準で,これらを比較することを著者が書いた論文が認めています.
要点 (c) は見解 (2) と整合しません.[L+15] は,猫小脳顆粒層シミュレーションの計算時間と猫の小脳全体のシミュレーション [YI13] の計算時間を直接比較しています.顆粒層と小脳全体という異なるシミュレーションの計算時間を直接比較することを,筆者が共著者になっている論文が認めています.
また,同一でないモデルのシミュレーションの比較の是非は,時系列で見ると次のように切り替わっていて,一貫性がありません.
2015 論文 [L+15] 共著 同一でない脳モデルのシミュレーションの比較は可能
2016 一般向け 招待講演 同一でない脳モデルのシミュレーションは比較からすべて除外
2017 論文 [Y+17] 筆頭著者 同一でない脳モデルのシミュレーションの比較は可能
2018 一般向け この記事へのコメント 同一でない脳モデルのシミュレーションは比較からすべて除外
一方これらの論文に書かれた見解は,論文の著者のみならず,共著者,査読者,編集者という専門家が承認したものです.よって,見解とコメントが整合しない場合,著者のコメントよりも,論文に書かれた見解の方が妥当だと考えます.
これを踏まえて,まず著者のコメント2, 3 に返答します.
コメント2への返答
同一のモデルでないと,シミュレーションの結果は比較できないというコメント2は [Y+17] における見解 (1) と整合しません.このため,見解 (1) の比較,つまり猫の大脳皮質モデルのシミュレーションと猫の小脳モデルのシミュレーションを論文のデータに基づいて比較することは,妥当と考えます.
そして,推定値を用いることは SF であり実際に実験しなければ嘘である,とコメントされました.これは,著者の見解 (3), (4) と整合しません.著者の見解 (3), (4) は SF ではないはずです.それと同じく,この記事において実験する代わりに推定値を使うことは嘘になりません.よって,著者の見解 (3), (4) に反するコメント2 に対して,変更は必要ないと考えます.
コメント3への返答
「猫の小脳モデルの顆粒層は猫の小脳モデルの一部でしかなく全部ではない」というコメントに対して,著者の見解 (2) では顆粒層 [L+15] と猫の小脳 [YI13] で直接比較しています.[YI13] と [Y+17] は同一モデルであるため,顆粒層 [L+15] と猫の小脳 [Y+17] の実験結果の比較は可能であり,コメントに対する変更は必要ないと考えます.
ただし,新たな記事(Shoubu の猫小脳シミュレーションは,スーパーコンピュータのアプリケーションの大部分には参考にならない)では,猫の小脳モデルの顆粒層に含まれるシナプス数が少ない場合を考慮した [Y+17] に有利な比較を行い,その結果 [L+15] のシミュレータを拡張することで, 0.112秒以内で実時間シミュレーションが行える可能性が十分あると予想しました.
コメント1への返答
著者のコメントへのリンクを先に示すことで,著者のコメントを読み,その内容を踏まえた上でこの記事を読むようになっているので,著者のコメントが指摘する誤解は起きないと考えます.そして,この記事では論文に示されている数字を,基準を明確に示した上で比較しています.これは [Y+17] がニューロン数を基準にした比較と同じなので,コメントに対する変更は必要ないと考えます.
シナプス数基準の妥当性
シナプス数基準よりも細かい基準で比較するために,各ニューロンで微分方程式の解を求める演算コストでの比較を,新たな記事(Shoubu の猫小脳シミュレーションは,スーパーコンピュータのアプリケーションの大部分には参考にならない)で行いました.その中で,シナプス数基準の比較は,微分方程式の解を求める演算コストの近似になっていることを示しました.スパイキングニューラルネットワークのシミュレーションでは,微分方程式の求解が計算の大半を占めるため,シナプス数基準の比較は [Y+17] で行われたニューロン数基準の比較より妥当だと考えます.
追記(2月26日)
この研究の著者からご指摘をいただきました.要約すると次の3点です.
1. 文脈を無視したミスリードをしている.
2. 嘘が書いてある.
3. [L+15] を誤読している.
これらについてこちらの意図が伝わるように,説明を修正・追加したいと思います.まずは,これからご覧になる方に対して,著者が「この記事は内容が不正確なので信用しない方がいい。」とコメントされたことを明記します.
以下,「内容が不正確なので信用しない方がいい」と著者にコメントされた記事です(ただし,論文の内容とこの記事は整合性があり,そのコメントは論文の内容に反しています)
「アプリケーションがあるから, PEZY Computing のスーパーコンピュータ(スパコン)は開発する価値がある」というときの前提「アプリケーションがある」というのは本当でしょうか.PEZY のスパコンを使った脳のシミュレーションに関する研究論文を読むと,アプリケーションの性能は,過去の研究より規模が小さく,粗く,遅くなっていることがわかります.
その研究は,2016年度理研シンポジウム『スーパーコンピュータHOKUSAIとShoubu、研究開発の最前線』での招待講演で紹介されている,PEZY Computing のスパコンの実用アプリケーションでも代表的なものです.そこでの講演『Shoubuで実現するネコ一匹分の人工小脳』(講演資料, PDF)では,「もちろん世界最大,最高速,最も精緻」(資料14ページ目)と書いています.さらに,電子情報通信学会論文誌 C に掲載された,鳥居淳らによる「グリーンスーパーコンピュータ ZettaScaler の技術と今後の展望」では次のように述べています.
これらの方策をもとに,各種アプリケーションの実装について検討が行われており,幾つかの報告事例が存在する [9] ~ [13] .特に,猫の小脳をリアルタイムで実現できたことは ZS-1 の有効性を端的に示した成果といえる.
しかし,猫の脳のシミュレーションでは,より規模が大きく,もっと速く,もっと精緻なシミュレーションがこの研究以前に行われています.PEZY スパコンのシミュレーションは過去の研究より計算性能が大幅に足りません.
過去の研究との比較
この招待講演の内容をまとめた論文 [Y+17] をそれ以前に発表された2つの論文 [A+09],[K+14] と比較します.文献情報はこの記事の最後の参考文献にまとめました.PEZY スパコンによる脳シミュレーションの比較結果を要点は次の6点です.
(1) ニューロン数の規模は,過去の研究よりやや小さい.
(2) シナプス数は極端(桁4つ分)に少ない.
(3) 時間ステップは同一か粗い.
(4) ボトルネックとなるシナプスごとに掛かる計算時間は遅い.
(5) シナプス数,時間ステップを揃えたとき,過去の研究の方が20-40倍速い.つまり,PEZY のプロセッサを使わず,過去の研究にならうだけで,[Y+17] のシミュレーションは20-40倍速くなる.
(6) 過去の研究は規模の小さい [Y+17] のシミュレーションを扱えるが,[Y+17] は規模の大きい過去の研究のシミュレーションを行えない.
[A+09] は,猫の大脳皮質のシミュレーションを猫の大脳規模で行い,Top500, Green500 の順位リストを発表する国際会議にて Gordon Bell 特別賞を受けています.
[K+14] は [A+09] をこれまでの脳シミュレーションで最大なものとして引用し,これを更新したことを報告しています.
[Y+17] は [K+14] を引用していますが,[A+09] を引用しておらず,自身のシミュレーションにおけるシナプス数を明記していません(以下では,細胞種と隣接関係から求めた推定値を用います).
3つの論文をシミュレーションの規模,速度を表す重要な数字で比較したのが次の表です.
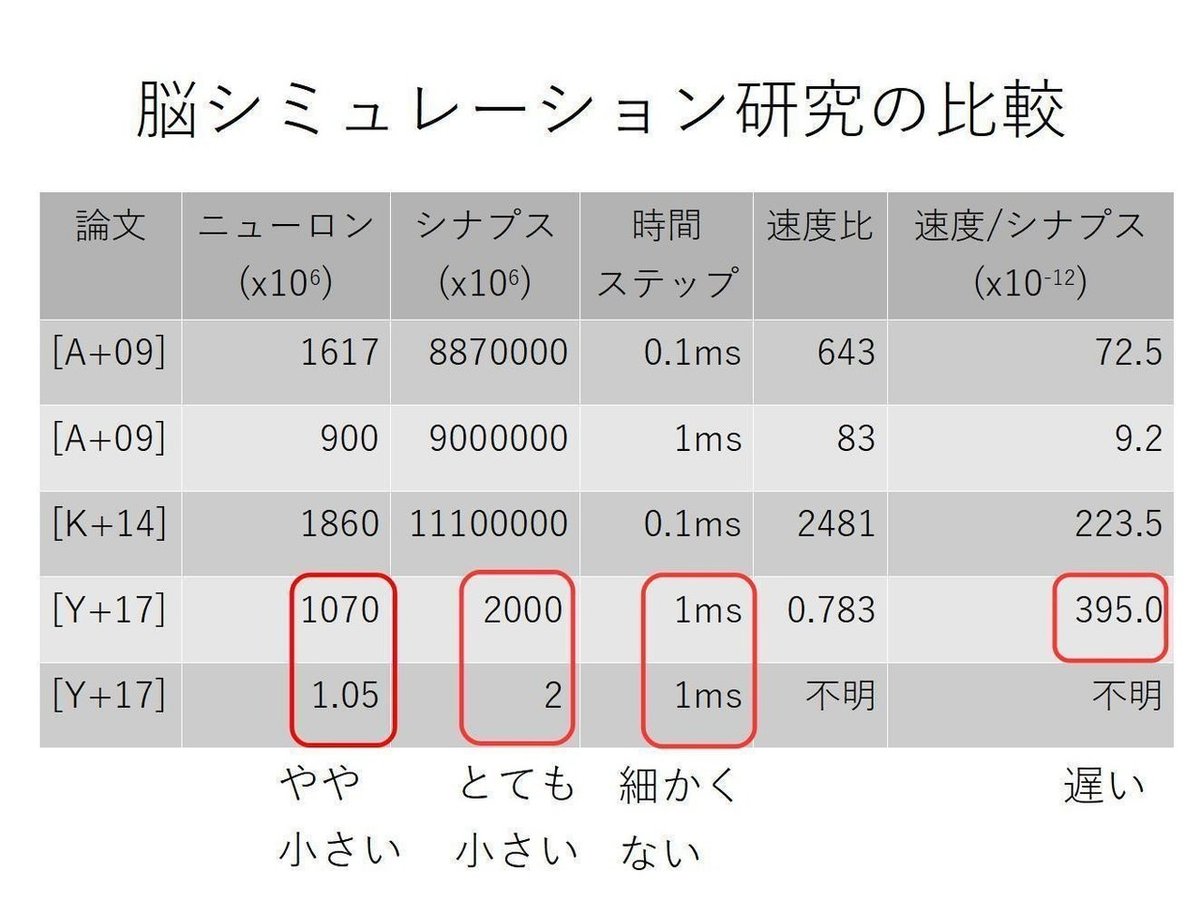
ただし,数字は有効数字(数桁)で打ち切っています.時間ステップはシミュレーションにおける最小単位の時間間隔を表し,短いほど精密になります.速度比は,1秒のシミュレーション全体に掛かる計算時間を表します.速度/シナプスは,1つのシナプスあたりの1秒のシミュレーションに掛かる計算時間を表します.[A+09] は異なる2条件でシミュレーションを行っています.[Y+17] は計算規模のためと,現実的なシナリオ (a realistic scenario) の2通りのシミュレーションを行っています.
表から,(1), (2), (3) は明らかです.
(4) について,脳のシミュレーションにおいて計算時間のボトルネックになるのは,シナプス(ニューロン間の結合)数です.ニューロン間の情報伝達を1つ1つ計算する必要があるので,シナプス数が大きいほど,シミュレーションの規模が大きく,計算が困難になります.そこで,シナプス1つあたりの計算時間で比較すると,PEZY のスパコンを用いたシミュレーションである [Y+17] が他より遅いことがわかります.シミュレーションの細かさである時間ステップも揃えると,(5) に示したように [Y+17] のシナプス1つあたりの計算時間は過去の研究結果より20-40倍遅くなります.
実時間シミュレーションが重要なら FPGA によるシミュレーションの方が高速
上の比較に対して「問題の大きさではなく,実時間でシミュレーションすることが重要なのであって,[Y+17] は最速だ」とする考えもあり得ます.しかしその場合,[L+15] では猫の小脳モデルを1秒シミュレーションするのに 25.6ms しかかかりません.さらに講演者は [L+15] の共著者なので(論文の公表は2015年,講演は2016年),講演したときにその内容を十分理解しています.
このため,「実時間でシミュレーションすることが重要」という基準をとると,講演者の主張「もちろん世界最大,最高速,最も精緻」と矛盾します.
小脳モデルは脳シミュレーションの性能を示すには不十分
Wikipedia での動物のニューロンの数を参照すると,過去の研究が扱った 10^9 のニューロン数,10^13 のシナプス数が猫の脳の規模として必要であり,[Y+17] が扱う限界の 10^9 のシナプス数では不十分なことがわかります.
[Y+17] は 4. Discussion において,
[K+14] は実時間でシミュレーションできないが,我々はできている(大意).
と主張していますが,それはシナプス数(脳のモデル)の違いによるものであり,計算能力の問題ではありません.シナプスあたりの計算時間と計算規模を見れば,[Y+17] の規模のシミュレーションは [K+14] により実時間で達成されることは確実でしょう.
[K+14] が [Y+17] の規模のモデルを同じ計算性能で扱うことは,規模を小さくするだけで可能ですが,逆に [Y+17] が [K+14] の規模のモデルを扱うのは,メモリ管理など越えなければいけない壁があるため,困難です.
生物学的観点から,小脳モデルをシミュレーションすることに意義はあるでしょう.しかし,スパコンの計算能力を示すのに小脳モデルを用いて,実時間でシミュレーションできているから,優れているというのは疑問です([Y+17] では 4. Discussion で小脳モデルがスパコンのベンチマークに適切だと主張していますが,[A+09], [K+14] がすでに達成した課題であるため,小脳モデルはベンチマークに不適切でしょう).
一般向けの情報に誤解を招く表現を含めることへの疑問
「猫の小脳のシミュレーションで世界最大,最高速,最も精緻」というのは,誤解を招く表現でしょう.論文を読んだ後では,過去の研究の方が性能が高く,猫の小脳に限定して主張することに疑問が残ります.
猫の小脳より大規模な脳のシミュレーション [A+09], [K+14] は既に達成されています.[A+09], [K+14] は直接小脳を扱っていませんが,[Y+17] は「最大規模,最高速,最も精緻」ではありません.シナプス1つあたりの計算時間で比較した結果から,[A+09], [K+14] は規模の小さい猫の小脳モデルを [Y+17] より十分高速に扱えるでしょう.
論文を直接読まない層に対する講演で,このような誤解を招く(実際とは真逆の)表現を用いることは,研究開発者全体の信頼を大きく損ねるものです.
まとめ
PEZY のスパコンを用いた猫の脳シミュレーションは「世界最大,最高速,最も精緻」という主張とは逆に,過去の研究と比べて「規模は小さく,計算速度は遅く,精緻ではない」ものでした.速度については,モデルのサイズに対するシミュレーションの相対速度,モデルのサイズに関わらないシミュレーションの絶対速度のどちらの基準でも,より高速にシミュレーションする過去の研究がありました.
さらに過去の研究に基づけば,PEZY のスパコンで行われたシミュレーションを20-40倍の速度で実現できる可能性が十分あることがわかりました.
このアプリケーションでは PEZY のスパコンによるシミュレーションは過去の研究より計算能力が及ばないため,PEZY グループ役員によって書かれた論文にある
特に,猫の小脳をリアルタイムで実現できたことは ZS-1 の有効性を端的に示した成果といえる.
という主張の正当性は疑わしく,有効性は8年前の研究成果に遥かに及びません.
参考文献
[A+09] R. Ananthanarayanan et al. (2009) The Cat is Out of the Bag: Cortical Simulations with 10^9 Neurons, 10^{13} Synapses. In Supercomputing 09: Proceedings of the ACM/IEEE SC2009 Conference on High Performance Networking and Computing (Portland, OR).
https://doi.org/10.1145/1654059.1654124
[K+14] S. Kunkel et al. (2014) Spiking network simulation code for petascale computers. Frontiers in Neuroinformatics 8: 78. https://doi.org/10.3389/fninf.2014.00078
[L+15] J. Luo et al. (2015) Real-Time Simulation of Passage-of-Time Encoding in Cerebellum Using a Scalable FPGA-Based System. IEEE Transactions on Biomedical Circuits and Systems 10(3), pp. 742-753. October 2015.13
http://dx.doi.org/10.1109/TBCAS.2015.2460232
[Y+17] T. Yamazaki et al. (2017) Real-time simulation of a cat-scale artificial cerebellum on PEZY-SC processors. The International Journal of High Performance Computing Applications. First Published June 6, 2017. http://journals.sagepub.com/doi/full/10.1177/1094342017710705