
【画像生成AI Stable Diffusionを使ってみよう#01】

『画像生成AI Stable Diffusionのセットアップをしてみよう』
※この記事は2022年11月に作成しました
~序~
私もローカル環境でAI画像生成をやってみたい
てなわけでAI画像生成ができるようになるまでの準備をまとめてみました
Stable Diffusion - AUTOMATIC1111版は使用する環境構築にはGoogle Cloudを利用してnVidia製のグラフィックボードがない環境や低スペックPCでも使えたりしますがこの記事ではnVidia製のグラフィックボード でローカル環境で使用する構成をまとめてあります
~要件~
GEDORCE EXPERIENCEをインストールしていてnVidiaドライバが最新状態であること
Windows10環境でnVidia製のグラフィックボードでGPUメモリ8GB以上
(GPUメモリ4GBでも一応できる)
~大まかな手順~
Stable Diffusionをローカル環境で運用するための下準備をします
・必要なPython、Git、CUDAの3つをインストール
・Stable Diffusionを運用したいところに配置
・学習モデルファイルckptを用意する
・人の顔を綺麗に描写するGFPGANを用意する
上記のソフトのインストールしたり必要なファイルを揃えたらStable Diffusionを起動する
~Pythonのインストール~
まずはPythonのインストールから
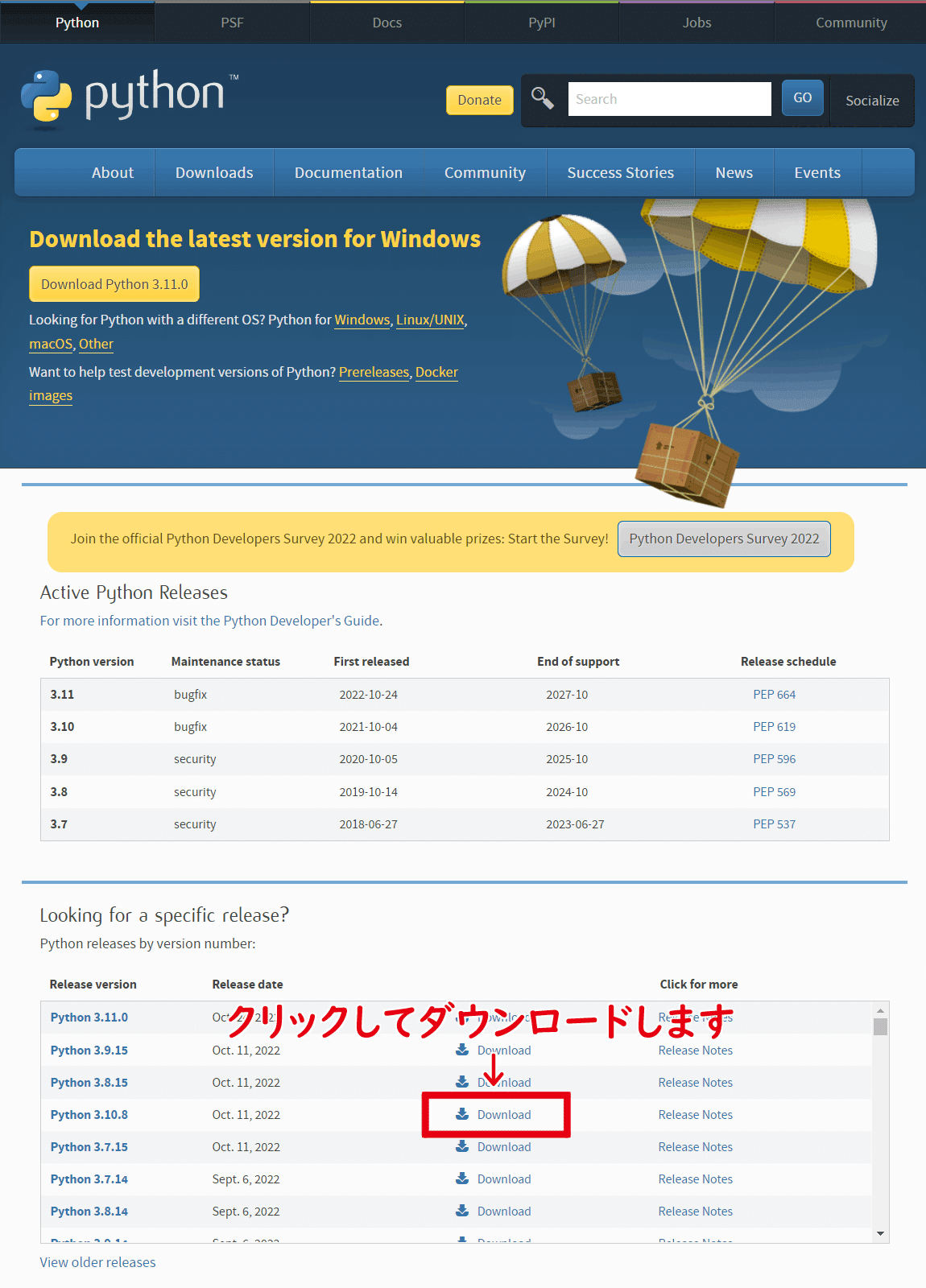
Python公式サイトでダウンロードボタンをクリックしてダウンロードします
3.11.0だと起動できないことが多発しているようです
少し下にスクロールしたところにあるバージョン3.10.8であれば起動確認できています
ダウンロードした.exeファイルを実行します

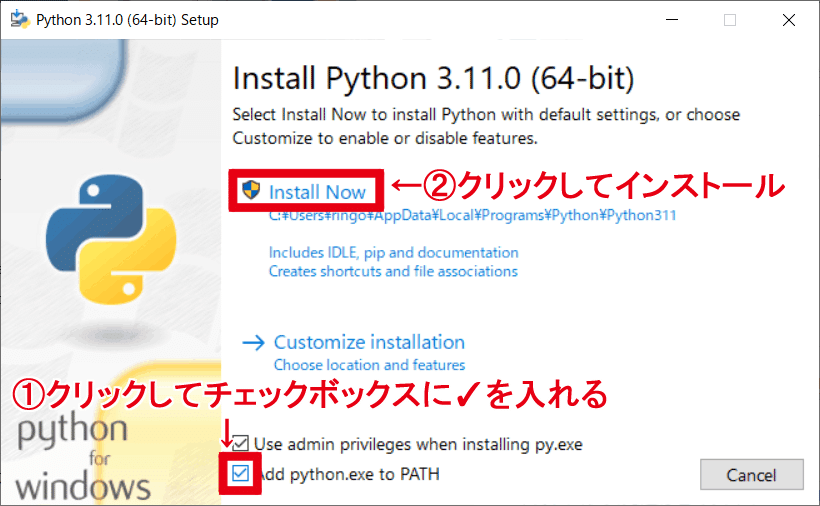
Pythonのインスロールウィンドウが開きます
下方にあるチェックボックスの『Add python.exe to PATH』にチェックを入れて『Install Now』をクリックしてインストールします
インストールが開始されます
インストールが終われば『Close』をクリックしてウィンドウを閉じます

~Gitのインストール~
次にGitのインストールをします
Git公式サイトのダウンロードページで『Click here to download』をクリックしてダウンロードします
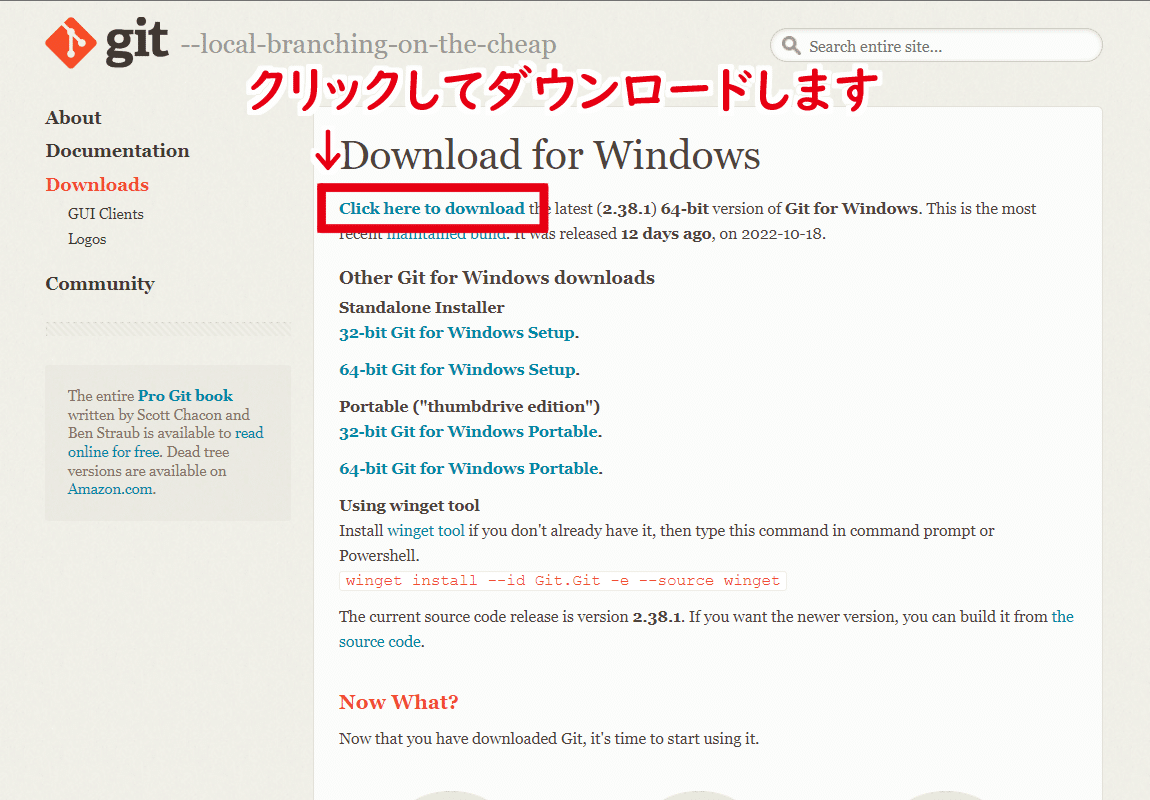
ダウンロードした.exeファイルを実行します

Gitのインスロールウィンドウが開きます選択がありますがそのまま『Next』をクリックして次へ進みます
インストール先の選択もそのままで『Next』をクリックして次へ進みます

チェックボックスがいろいろでてきますがそのままで『Next』をクリックして次へ進みます

スタートメニュー登録もそのままで『Next』をクリックして次へ進みます

利用規約です『Next』をクリックして次へ進みます

選択がありますがそのまま『Next』をクリックして次へ進みます
選択がありますがそのまま『Next』をクリックして次へ進みます
選択がありますがそのまま『Next』をクリックして次へ進みます

選択がありますがそのまま『Next』をクリックして次へ進みます
選択がありますがそのまま『Next』をクリックして次へ進みます

選択がありますがそのまま『Next』をクリックして次へ進みます

選択がありますがそのまま『Next』をクリックして次へ進みます

選択がありますがそのまま『Next』をクリックして次へ進みます

チェックボックスがありますがそのまま『Next』をクリックして次へ進みます

チェックボックスがありますがそのまま『Install』をクリックしてインストールをします

インストールが開始されます
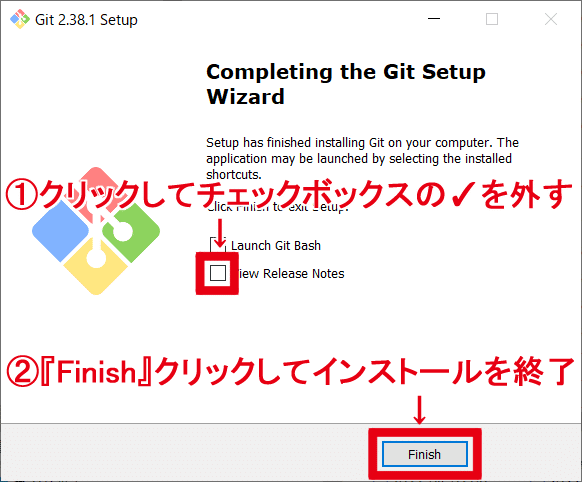
インストールができたら『View Release Notes』のチェックボックスからチェックを外して『Finish』をクリックしてウィンドウを閉じます
~CUDAのインストール~
下準備の最後にnVidiaのCUDA Toolをインストールします
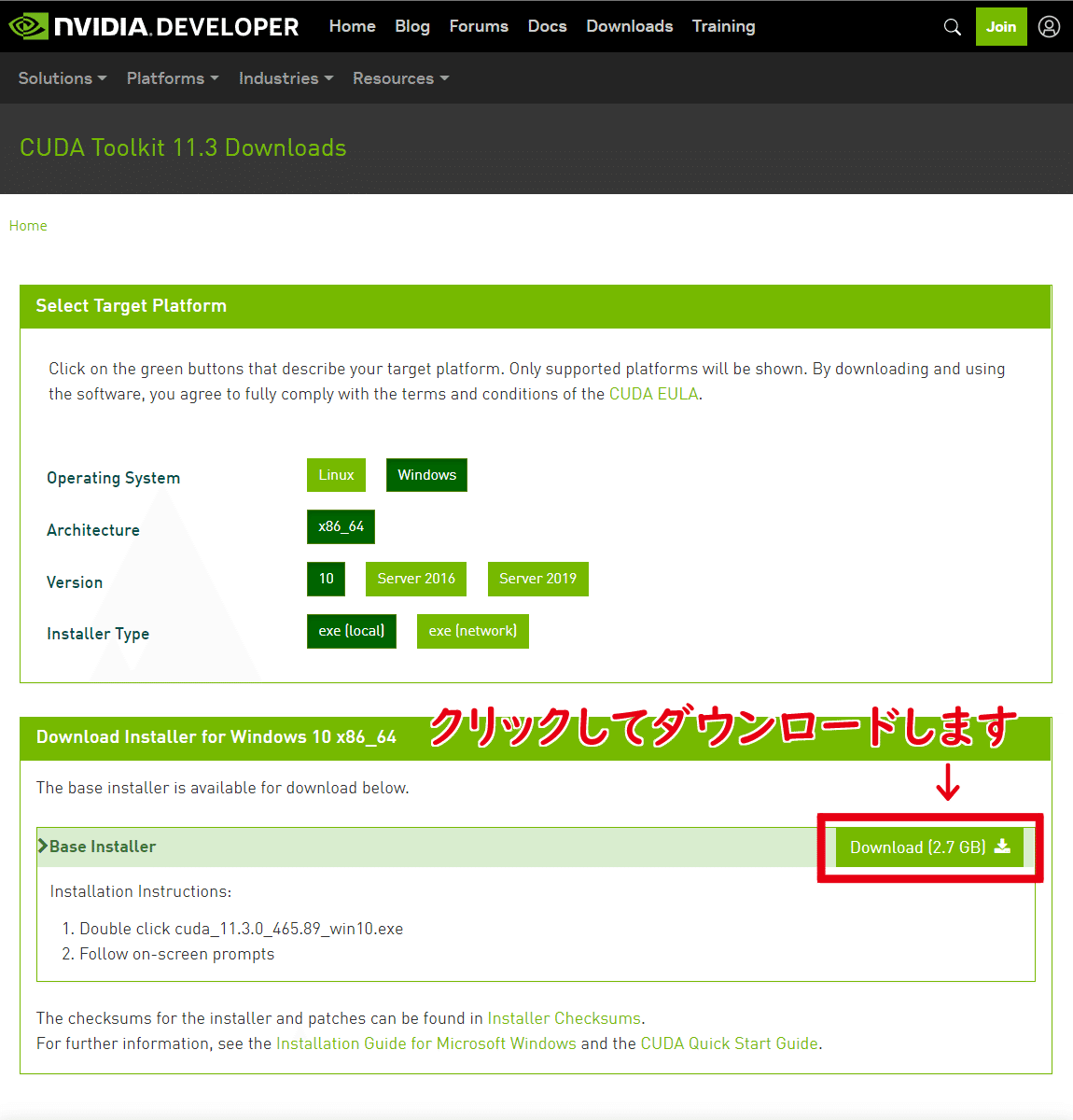
NVIDIAの開発者向けサイトで『CUDA Too』をダウンロードします
インストール時にファイルをダウンロードしながらインストールタイプではなく全ファイルが入っているタイプなのでファイルサイズが大きくて2.7GBあります
下の方にあるダウンロードボタンをクリックしてダウンロードします
ダウンロードした.exeファイルを実行します

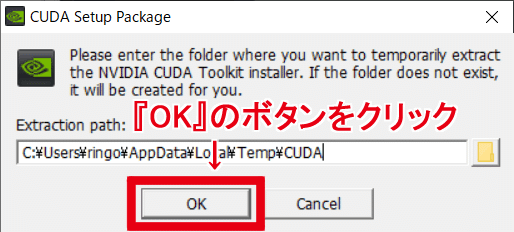
実行すると解凍先の確認ウィンドウが開での『OK』クリック
解凍が開始されます
解凍が終わればインストーラーが起動します

互換性のチェックが入ります

※nvVdiaグラフィックボードドライバのバージョンが適合していないい時は柿のような警告が出ますが適合したドライバを自動的にインストールしてくれるので『続行(O)』をクリックして次に進みます

利用規約です『同意して続行する(A)』をクリックして次に進みます
選択がありますがそのまま『次へ(N)l』をクリックしてインストールをします
インストールが開始されます
インストールができたら『閉じる(C)』をクリックしてウィンドウを閉じます
~Stable Diffusionを運用したいところに配置~
前記の3つのアプリケーションを問題なくインストールできればStable Diffusionをローカル環境で運用できる要件を満たしていると思われます
お待ちかねのStable DiffusionをGitHubに公開されているページよりダウンロードします


ダウンロードしたStable DiffusionのZipファイルを任意の運用したい場所に解凍しておきます
C:\やD:\やE:\糖の上層にしておくことをオススメします
~学習モデルファイル『ckpt』を用意する~
Stable Diffusionはckpt形式の学習モデルデータのファイルを使用して学習モデルデータに即したAI画像生成をおこないます
学習モデルデータファイルがないと何を元にして生成すれば良いのか解らないので何かしらのckpt形式の学習モデルデータファイルが必要になります
Hugging Faceのフォーラムに学習データがあるのでそれをダウンロードしましょう
ページ内の『sd-v1-4.ckpt』をクリックするとダウンロードを開始します
※Hugging Faceへのユーザー登録が必要になります
Hugging Face

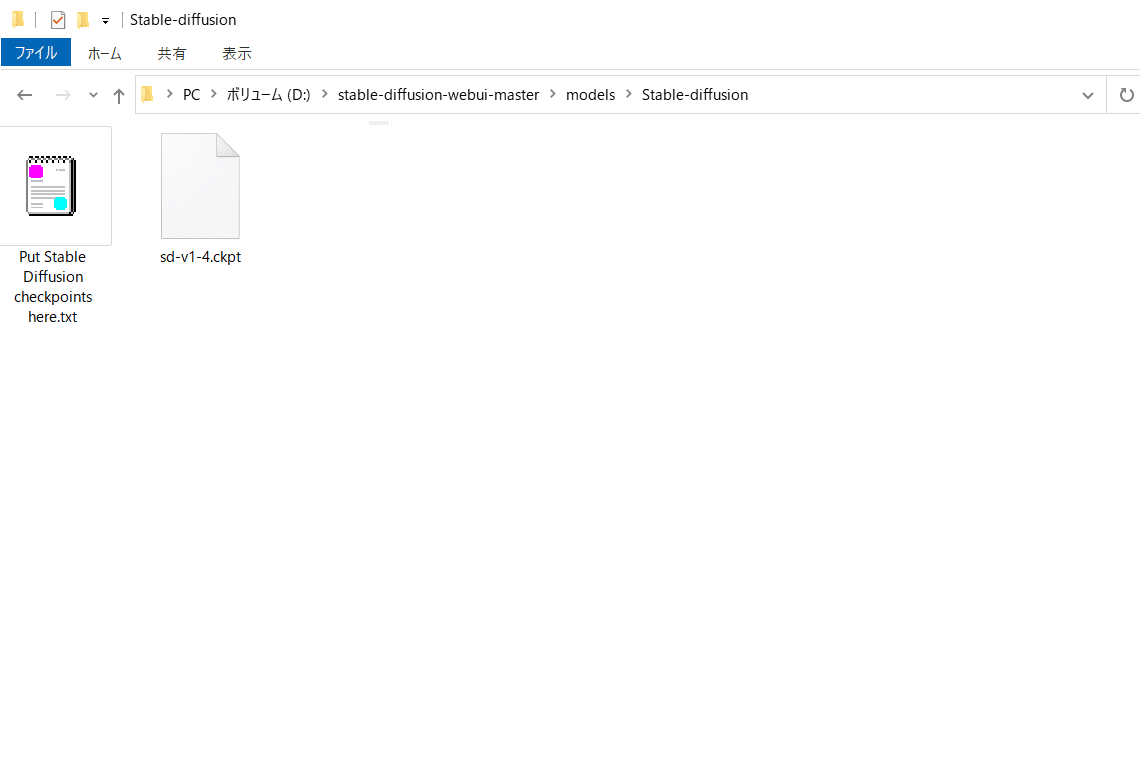
ダウンロードしたckpt学習モデルデータファイルは
○:\stable-diffusion-webui-master\models\Stable-diffusion
に配置します
~人の顔を綺麗に描写するGFPGANを用意する~
GFPGANはAI画像生成で人物の顔を綺麗に高画質に補正してくれるプラグインです
URLから直接ダウンロードできます
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.4.pth
ダウンロドしたファイルは
○:\stable-diffusion-webui-master
に配置します

~Stable Diffusionを起動する~
それでもStable Diffusionを起動させます
Stable Diffusionには起動の.exeファイルはありません
『webui-user.bat』というファイルがあるのでそのファイルをダブルクリックしましょう
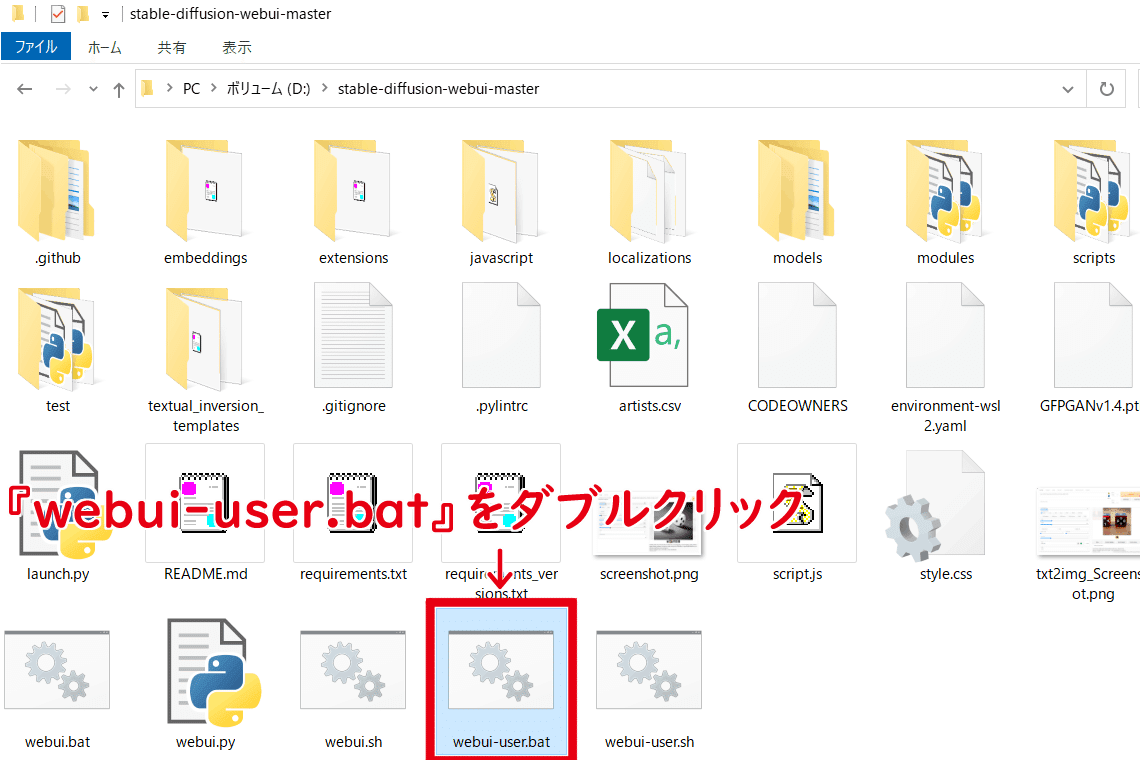
.batファイルを起動させるとWindowsのCommand Promptが起動します

初回起動はいろいろインストールしたりするので時間が少しかかります
コマンドプロンプト内に『Running on local URL: http://127.0.0.1:7860』
の文言が出るまで待ちましょう

http://127.0.0.1:7860
URLが表示されているのでブラウザにURLを入力またはコマンドプロンプトからコピーしてブラウザにペーストしてブラウザページを開きます

これでAI画像生成ができるようになりましたさっそく何かAI画像生成を試してみましょう
左上の選択ボックスの『∨』をクリックして学習モデルデータをダウンロドしてきた『sd-v1-4.ckpt』を選択します
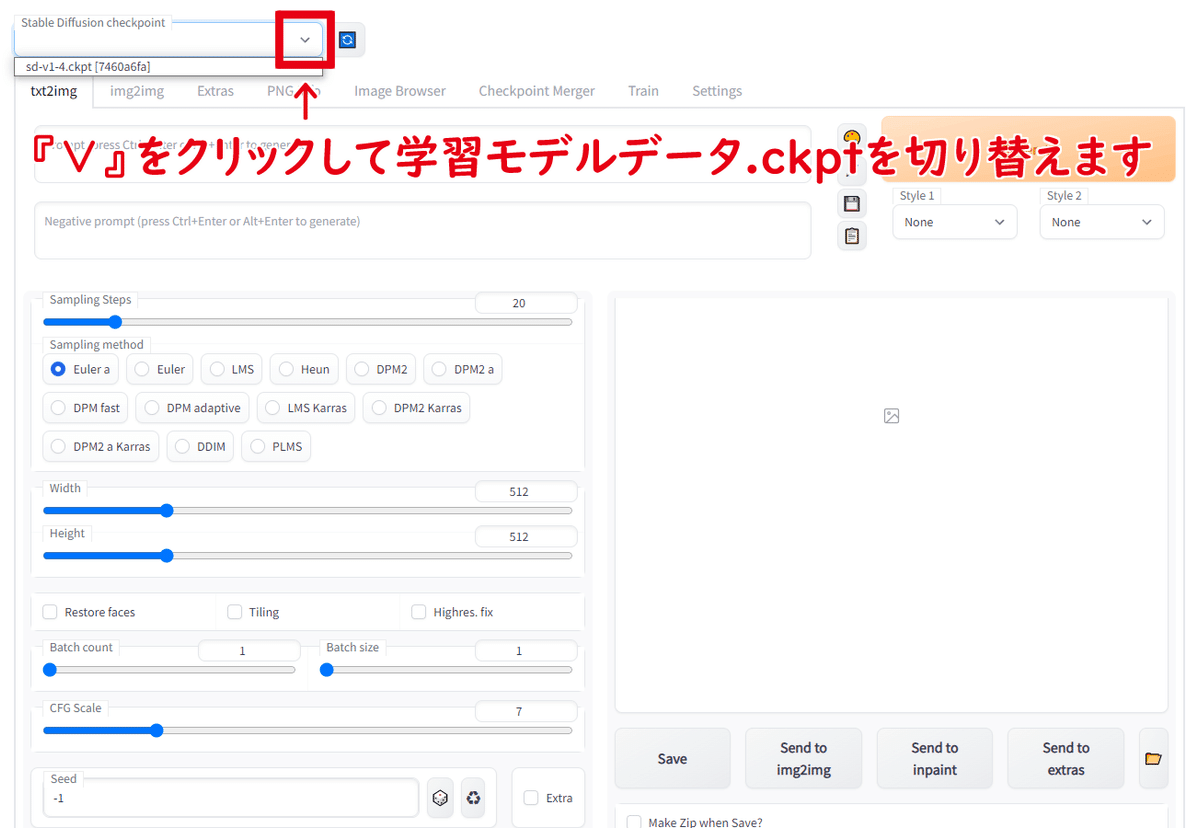
学習モデルデータの読込は少し時間がかかったりします
『sd-v1-4.ckpt』がセットされたら準備完了です
上段のプロンプトにはどのような画像を生成するかのワードを入力します
すぐ下の『ネガティブプロンプト』には画像を生成する際に生成しないようにするワードを入力します

試しに上段の『プロンプト』に『girl』と入力して『Generate』をクリックしてみます
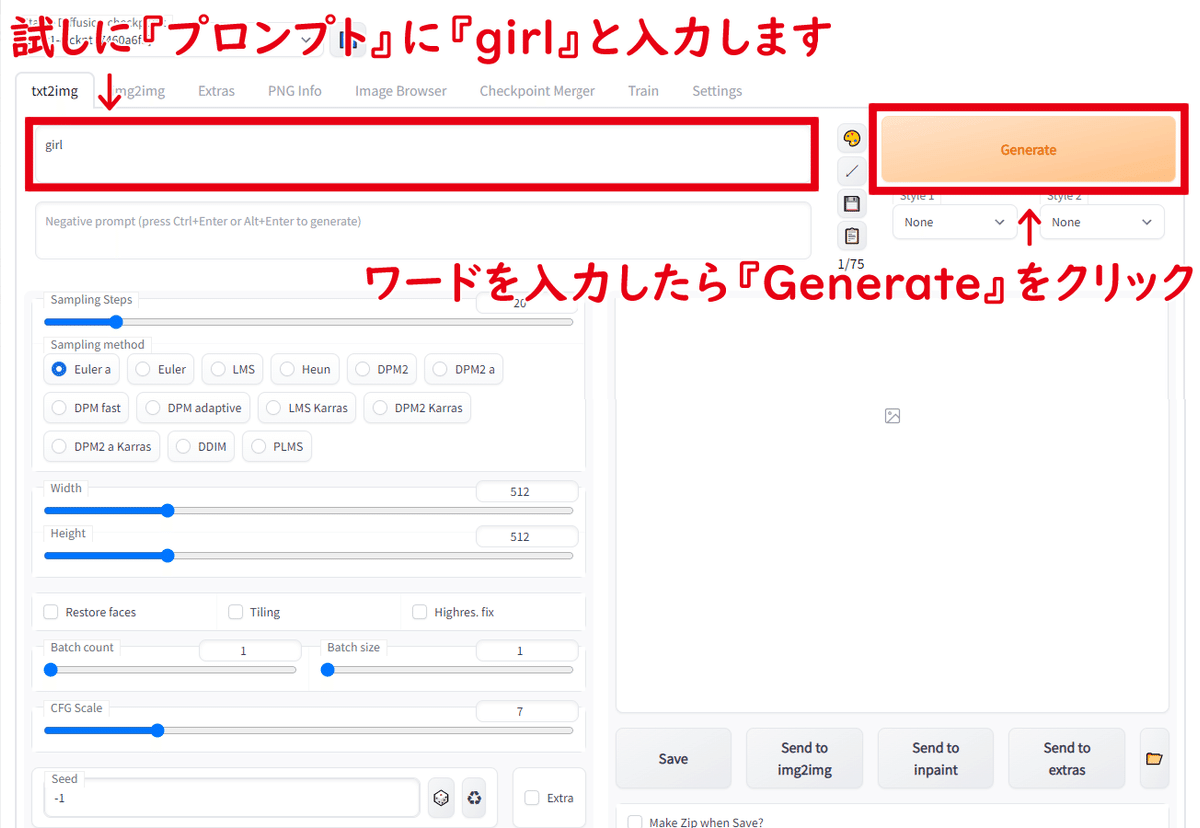
『Generate』をクリックしたら画像生成が始まります
環境により初回や時々遅いときがあります

コマンドプロンプト側で挙動の詳細を確認することもできます

画像が生成されます

サムネイル表示をクリックすると大きな画像に表示を切り替えてくれます

もう一度画像をクリックするとブラウザいっぱいまで拡大して大きな画像で確認ができます
右上の『×』をクリックすれば元の画面に戻ります

これで『Prompt』にワードを入力して『Generate』をクリックすれば画像を生成してくれるようになりました
ワードは『,』で区切ることでいくつでも指定することができます
『ワード1,ワード2,ワード3,ワード4, …』といった感じです
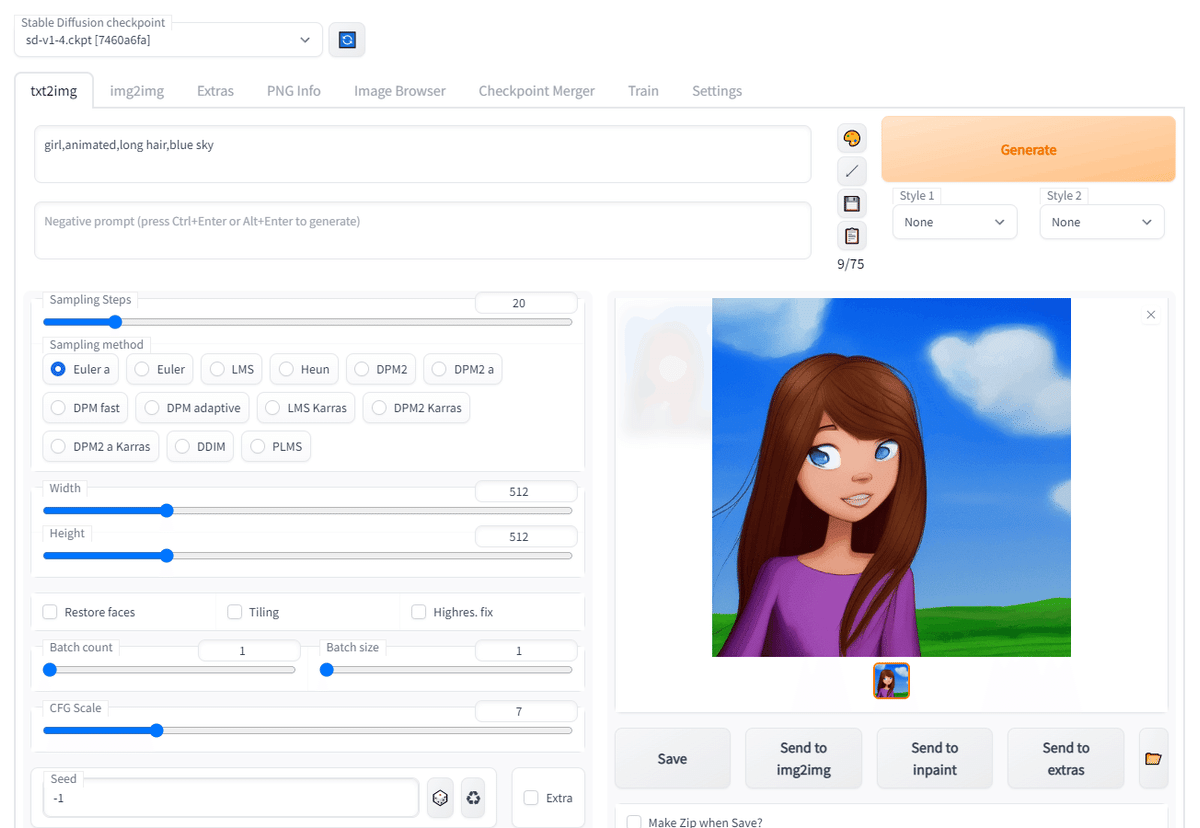
【例】
『girl,animated,long hair,blue sky』と入力
~Stable Diffusionの設定をちょっとよくしよう~
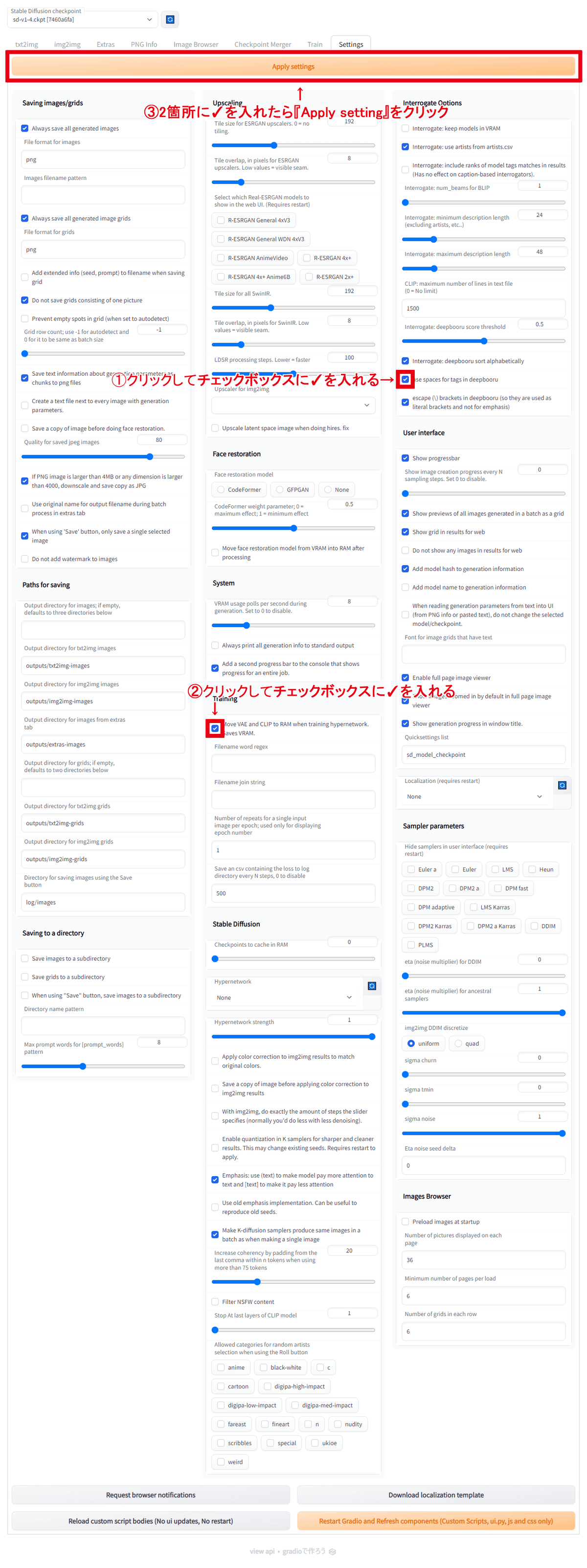
上段のタブの『setting』をクリックして設定ページに切り替えましょう
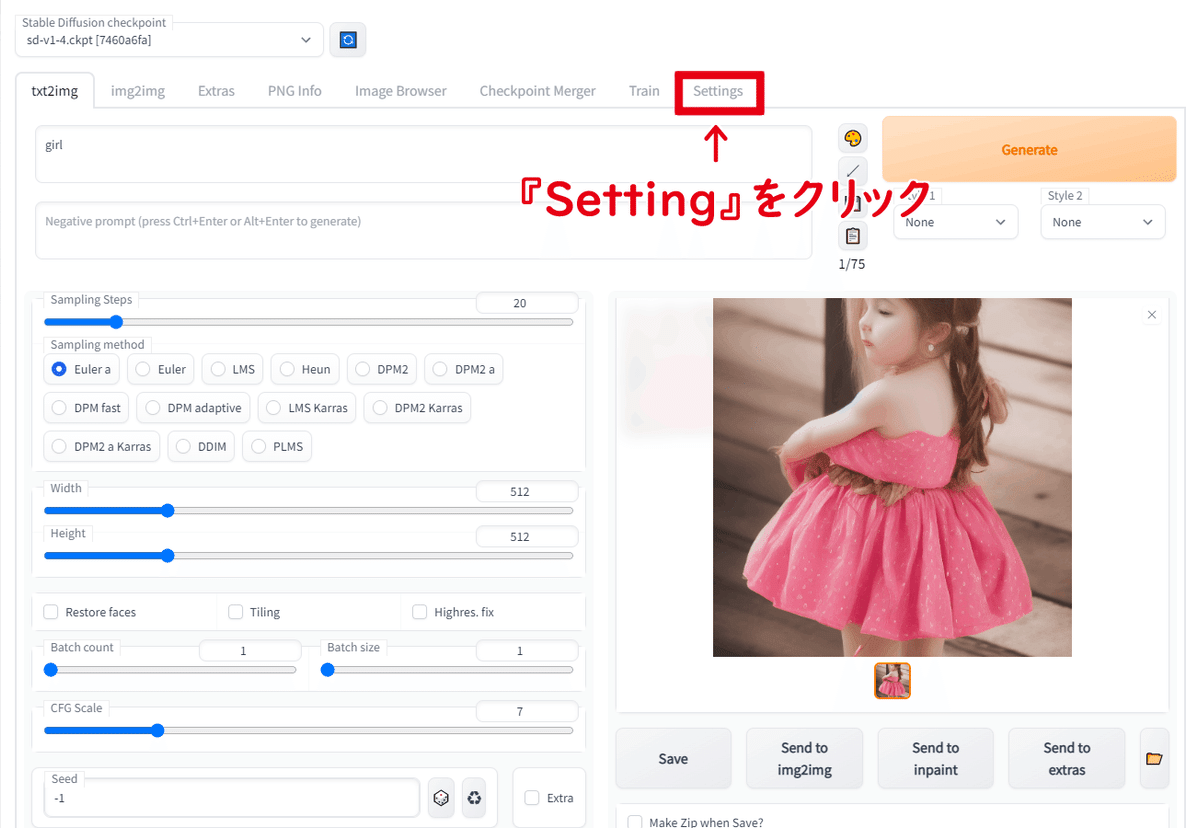
下にスクロールしていけていろいろな設定があります

やっておくことは簡単です
①『Interrogate Opthions』の項目にある『use spaces for tags in deepbooru』横のチェックボックスをクリックしてにチェックを入れる
画像生成のワードでスペース(空白)を利用可能にします
②『Training』の項目にある『Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM.』横のチェックボックスをクリックしてにチェックを入れる
後の何か学習をさせるときのための設定です
③2箇所にチェックを入れたら『Apply setting』をクリックして変更を適用させておきましょう
~了~
Stable Diffusionは思ったよりもお手軽にできてAI画像生成で欲しい機能や必要な機能は一通り揃っていたりしてとても楽しいです
今回の記事では使い方の詳細とかよりもとにかくセットアップして触ってみようってところまでで区切ることにします
次回は使い方のもうちょっと詳しいこととAI画像生成で用意した画像を学習させることをやってみたいと思います
この記事が気に入ったらサポートをしてみませんか?