
AI初めて3週間たったので重回帰分析でKaggle入門(タイタニックの生存予測)

きっかけ・勉強法
4,5月にやっていたチャットボット作成。
その過程で、自作でちゃっちい形態素解析のプログラム組んだりしてたけど、これ手でやるのめんどいなって思ったりしてる時に、人工知能とかに手を出そうかなと。
ただ、何から手をつければいいかわからない状態だったので、とりあえずネットサーフィン。
調べてると、Udemyでコース取るのが一番良さそうだったので、前にイラレの勉強してる時に使ってたこともあり探してみた。
結果、
キカガクっていうベンチャーが出してるこれが最高だった。
すでに諸々知識がある人にとっては物足りないかもしれないけど、0からの人は人工知能とはなんぞやってところから、実際にモデルの作成までの流れをざっと学べる。
現在中級編まで出ており、一通り環境構築、nampy, pandas, skleanなどが使えるようになる。
分析的な面だと、単回帰分析・重回帰分析までが一通り、簡単なところは理解できる。
(途中データのスケーリング、標準化が全く理解できなかったけど、下記の記事でなんとなくわかるようになった。)
これらが終わったら、AIやら機械学習やらの勉強法を探しているとほとんどがKaggleのKernelをひたすらやれ、とのことなのでKaggleに入門。
以下、誰しもがやるかの有名なタイタニックの生存率の予測問題を解いてみた話。
参考
まず、基本的に上記のUdemyの進め方、また下記の記事を参考に進めていく。
準備とデータの読み込み・確認
まずはとりあえずnampyとpandasのインポート。
import numpy as np
import pandas as pdそして、与えられたデータの読み込み。test.csvはtestに。train.csvはtrainに格納する。trainが訓練用データ、testをテスト用のデータとする。
読み込みにはpandasのpandas.read_csvを使用。
test = pd.read_csv("../input/test.csv")
train = pd.read_csv('../input/train.csv')そしてtest, trainの中身をそれぞれ確認する。全部は見る必要ないのでheadを使い、3行だけ見る。
train.head(3)
test.head(3)
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
とのことなので、testにだけSurvivedが抜けているのがわかる。
また、describeでデータの詳細を見てみると、
train.describe()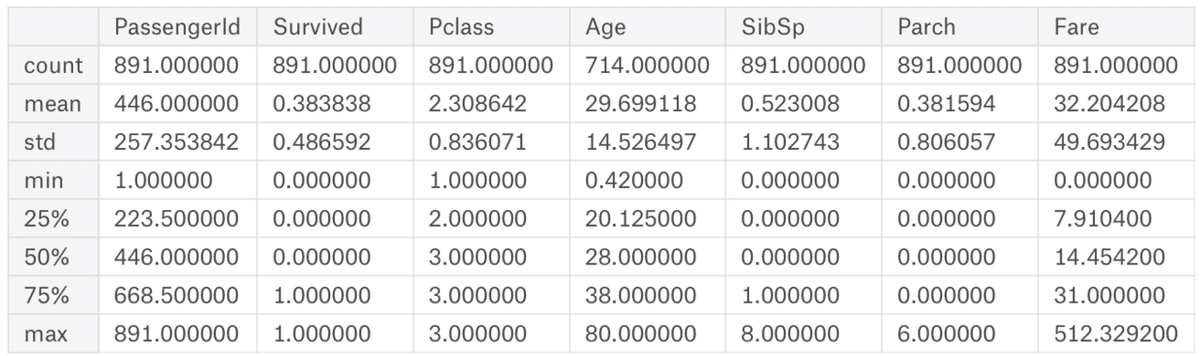
test.describe()
となる。
それぞれCountがPassengerIDとAgeで数値が違うので、欠損データがあることが分かる。
事前処理1 : 欠損データの確認・修正
詳細を知るために参考記事にあった欠損値確認の関数を作成。
def kesson_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)
kesson_table_ren_columns = kesson_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return kesson_table_ren_columns1. まずnull_valに引数に指定したデータの欠損データ(isnull)の合計数(sum)を入れる。
2. そのあとpercentに欠損データを元のデータの個数(len)で割って割合を算出。
3. 1と2で作成したnull_valとpercentをpandas.concatで結合して、kesson_tableを作成する。
4. kesson_tableの列名を変更し、returnで返す。
といった動作。
一旦これを使い確認。
kesson_table(train)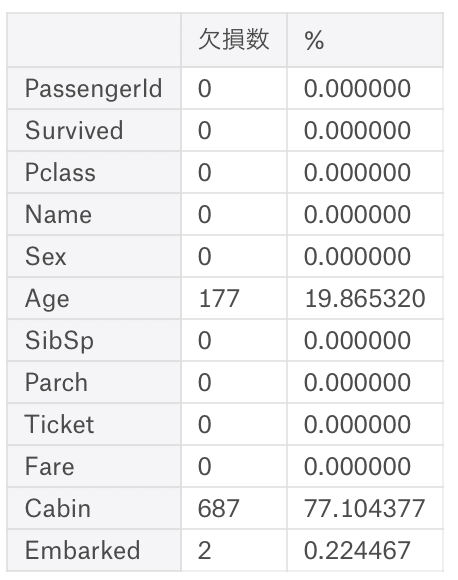
kesson_table(test)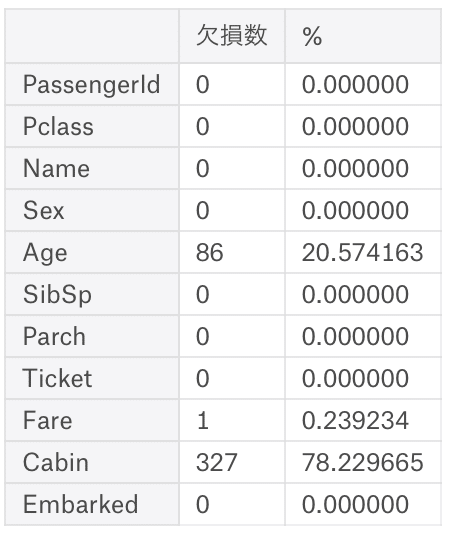
AgeとCabinとEmbarkedに欠損を確認。
今回はCabinは使わないので、AgeとEmbarkedのみ欠損データを代わりのものに置き換える。
代理のデータは、Ageは中央値、Embarkedは欠損の数も少ないため一番多かったSを使う。
まずはtrainから
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")1. train["Age".median()]で中央値を獲得、そしてfillnaを使ってtrain["Age"]の欠損データを入れ替える。
2. 1と同様に、fillnaを使ってtrain["Embarked"]の欠損データをSに置換。
特定の要素の取得方法
欠損データの除外、置換についての詳細はこちら。
trainの確認をしてみる。
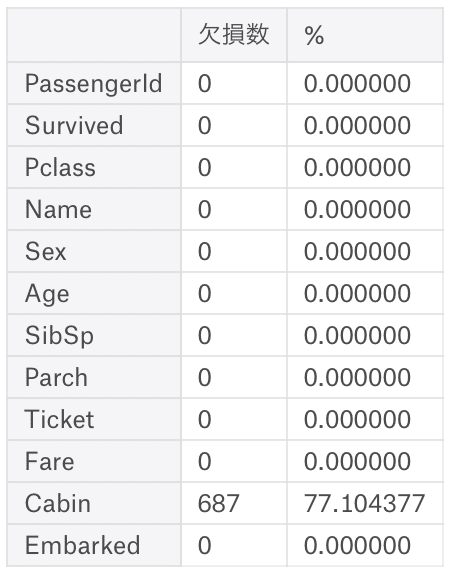
ちゃんと欠損数は0に。
testの方はAgeしか欠損がないので、
test["Age"] = test["Age"].fillna(test["Age"].median())欠損データの入れ替えは終わり。
事前処理2 : 文字データを数字に変換
モデルを作るにあたって、文字データを数値にする必要があるので、それを実行。
今回はSexとEmbarkedが該当するので、それぞれ数値に変換。
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2条件をそれぞれ指定して、数値に代入していく。
入れ替えたら確認。

testの方も同様の作業を。(省略)
予測モデルの作成
ここまでで事前準備は終わったので、予測モデルの作成をする。
今回は重回帰分析を使うので、まずはtrainをilocを使ってXとyに分ける。
また、分析には
Pclass
Sex
Age
Fare
のみを使うので、(欠損データの方でEmbarkedも使う、と書いたけれども使わなかった。)Xにはそのデータのみ入れる。
X = train.iloc[:,[2,4,5,9]]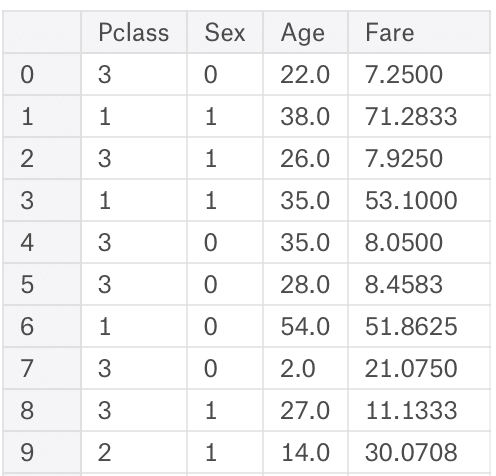
y = train.iloc[:,1]
(ilocなどについて)
これでXとyの作成が完了。
モデル作成のためLinearRegressionを引っ張ってくる。
from sklearn.linear_model import LinearRegressionそしてXとyを入れる。
model.fit(X,y)これで今回の重回帰分析のモデルが作成された。
テストデータで確認
モデルができたので、Kaggleに提出するために実際にテストデータを使って予測を出してみる。
test_features = test[["Pclass", "Sex", "Age", "Fare"]].valuesそして予測値の出力
predictions = model.predict(test_features)
答えは0か1じゃないといけないため、とりあえずは0.5未満は0(死亡)、0.5以上は1(生存)として、データを更新する。
predictions[predictions >= 0.5] = 1
predictions[predictions < 0.5] = 0
提出
最後に結果を提出する必要があるので、その対応をする。
まず、提出にはPassengerIdとSurvivedが求められているので、testからIdを引っ張り出してくる。
ids = test.loc[:,["PassengerId"]]そして、予測値と結合、列名の追加を実行
result = pd.concat([ids,predictions_pd.astype(int)], axis=1)
result_last = result.rename(columns={0: 'Survived'})*提出は0か1のため、astype(int)で整数にする必要がある。
最後に、to_csvを使ってCSVにして書き出し。
result_last.to_csv("result.csv", index=False)あとは右上ボタンのCommitを押した後に、

このOpen Versionをクリック。そして、
Out putからSubmit to Competitionを選択して、CSVを提出。

そうするとスコアが出るので確認。なぜか0.76も出た。。。

順位。
nampy,pandasの知識なりもなく、重回帰分析以外の解法もよく知らないので、知識を付けていきたい。
あとがき:つまずいた際のメモ
また、実はcsvを出力するところでtypeが違ったり、次元が違かったりでめちゃめちゃつまづいたので、以下対処法。
最初、提出用のデータを
result = pd.DataFrame(predictions_pd, ids, columns = ["Survived"])で、出そうと思ったけど、エラー。
エラー文:Buffer has wrong number of dimensions (expected 1, got 2)
要は、次元が違うよってことなので、次元の確認、
ids.ndimndimの参考。
案の定2を返した。
けどデータは一種類しか入ってないから次はデータのタイプを疑う。
type(ids)pandas.core.frame.DataFrameを返す。
ちなみに予測値の方はpandas.core.series.Seriesを返した。
Dataframeが2次元、Seriesが1次元ということらしい。
じゃあDataframeを1次元にすればいいんじゃないのって思って調べたもののなかなか見つからず、DataframeとSeriesを結合する道を探った。
結果、欠損値テーブルを作るときに使ったconcatでできることが判明。
解決。
その他series,dataframeについてあさったところ。
また、単回帰分析・重回帰分析等に当てはまる線形回帰と、ロジスティック回帰との違いがよくわかってなかった時に読んだもの。
この記事が気に入ったらサポートをしてみませんか?