
rinna/japanese-gpt-neox-3.6bをファインチューニングして小説を書いてみる。

ご無沙汰しております。
数年前に「gpt-2で太宰治っぽい文章を作ってみよう」という記事を書きました。
縁あって、今回社内のコンペで「AIで小説を生成しよう」という企画があり、久しぶりに筆を取った次第です。
GPT-3.5の台頭から目まぐるしく生成AIは進歩を続けていますが、ここらで自己ベンチマークを定める意味でも一度まとめてみることにしました。
結論から言うと、あまり芳しくない結果となりました。それを踏まえた上でご覧ください。
1. モデルの選定
大規模言語モデル(Large Language Models、LLM)が昨今のトレンドです。GPT-3.5やGPT-4のモデルが一般公開されていれば良かったのですが、現在(2023年8月)はまだ非公開なので、日本語に対応したLLMをファインチューニングすることにします。
策定時期(2023年7月)ではrinna社の「japanese-gpt-neox-3.6b(もしくは4b)」かサイバーエージェント社の「open-calm-7b」で迷いました。世に出ているドキュメントの量と学習時間を鑑みて、rinna社のjapanese-gpt-neox-3.6bから手を付けてみました。なお、この時点ではstaibility aiの「Japanese StableLM Alpha」はリリースされていいませんでした。機会があれば試してみたいですね。
2. 環境構築
例によって、Google Colaboratory上で構築します。本来であればローカルマシンでファインチューニングしたかったところですが、GPU搭載のマシンを持っていないためクラウド上の仕組みを使います。
なお、今回の開発にあたりColab Proに課金しています。従って、非課金モデルでの動作は保証しかねます。あしからず。
環境構築から推論まで、以下の文献を参考にしました。先人たちに感謝。
3. 作家・データセットの範囲の選定
青空文庫から特定の作家の小説をファインチューニングさせます。japanese-gpt-neox-3.6bは日本語のWikipediaなどを学習させているため、現代仮名遣いに近い作家を選びます。
比較的近年の作品(没後50年の作品が青空文庫には収録されている。なお、著作権法改正によって、従来の保護期間である死後50年は死後70年へと延長されましたため、新しくても1967年が最新となる。)
一冊のボリュームが少ない作品(なるべく30,000文字を目標にする)
一人の作家の作品(多くの作家の作品を混ぜると文体が安定しないため)
上記より、近年亡くなった短編小説家「山川方夫」氏の30作品を使用する。
4. データセットの準備
Google Driveの接続
Google Colabを使用するにあたり、ファイルの長期保存ができないため、Google Driveにデータセットを保存します。
# Googleドライブのマウント
from google.colab import drive
drive.mount("/content/drive")リスト作成
作家リストからzip、unzip、utf-8フォルダを作成し、それぞれを格納します。以下は夏目漱石の例です。
import urllib.request as req
import urllib
import re
from bs4 import BeautifulSoup
import time
import os
import zipfile
#青空文庫 夏目漱石(person148)リストURL
url = "https://www.aozora.gr.jp/index_pages/person148.html#sakuhin_list_1"
card_nums =[]
save_folder = ".//作品//夏目漱石//"
if not os.path.isdir(save_folder):
os.makedirs(save_folder)
def get_card_num():
print(url)
try:
res = req.urlopen(url)
except urllib.error.HTTPError as e:
print('raise HTTPError')
print(e.reason)
except urllib.error.URLError as e:
print('raise URLError')
print(e.reason)
else:
print(res.status)
soup = BeautifulSoup(res, "html.parser")
first_ol_element = soup.find('ol')
for element in first_ol_element.find_all('li'):
sakuhin = element.text
#print(sakuhin)
title_name = re.search(r'(.*)(()',sakuhin)
#print(title_name.group(1))
card_num =re.search(r'作品ID:([\d:]+)',sakuhin)
#print(card_num.group(1))
card_nums.append(card_num.group(1))
get_card_num()
file_names = []
for card_num in card_nums:
print(card_num)
card_url = "https://www.aozora.gr.jp/cards/000148/card" + str(card_num) + ".html"
print(card_url)
try:
res = req.urlopen(card_url)
except urllib.error.HTTPError as e:
print('raise HTTPError')
print(e.reason)
continue
except urllib.error.URLError as e:
print('rase URLError')
print(e.reason)
continue
else:
print(res.status)
soup = BeautifulSoup(res, "html.parser")
download_table = soup.find('table', {'class':'download'})
#print(download_table)
download_path = download_table.select_one("tr:nth-of-type(2) td:nth-of-type(3)").get_text()
#print(download_path)
file_names.append(download_path)
time.sleep(1)
save_folder = ".//作品//夏目漱石//"
download_folder = save_folder + "zip//"
if not os.path.isdir(download_folder):
os.makedirs(download_folder)
for file_name in file_names:
print(file_name)
download_file_url = "https://www.aozora.gr.jp/cards/000148/files/" + file_name
local = download_folder + file_name
if not os.path.exists(local):
print("{0}のZIPファイルをダウンロード".format(file_name))
try:
download_data = urllib.request.urlopen(download_file_url).read()
except urllib.error.HTTPError as e:
print('raise HTTPError')
print(e.reason)
continue
except urllib.error.URLError as e:
print('rase URLError')
print(e.reason)
continue
else:
print(res.status)
res.close()
with open(local, mode="wb") as f:
f.write(download_data)
time.sleep(1)
else:
print("{0}のファイルはダウンロード済みです。".format(file_name))
zip_files = os.listdir(download_folder)
unzip_folder = save_folder + "unzip//"
if not os.path.isdir(unzip_folder):
os.makedirs(unzip_folder)
unzip_filenames = []
for zip_file in zip_files:
if ".zip" in zip_file:
print("{0}のファイルを解凍します。".format(zip_file))
zip_file_path = download_folder + zip_file
with zipfile.ZipFile(zip_file_path, 'r') as z:
for info in z.infolist():
info.filename = info.filename.encode('shift_jis').decode('utf-8')
z.extract(info, path=unzip_folder)
unzip_filenames.append(info.filename)
utf8_folder = save_folder + "utf8//"
if not os.path.isdir(utf8_folder):
os.makedirs(utf8_folder)
for unzip_filename in unzip_filenames:
if os.path.isfile(unzip_folder + unzip_filename):
if not os.path.isfile(utf8_folder + unzip_filename):
sr_file = open((unzip_folder + unzip_filename), 'r',encoding='shift_jis')
dt_file = open((utf8_folder + unzip_filename), 'w',encoding='utf-8')
for row in sr_file:
dt_file.write(row)
sr_file.close
dt_file.close
print("{0}ファイルの文字コードをUTF8に変換しました。".format(unzip_filename))
else:
print("{0}ファイルは既に文字コード変換されています。".format(unzip_filename))
else:
print("{0}ファイルが存在しません。".format(unzip_filename))
画像が含まれている作品の変換
江戸川乱歩のように本文に画像が含まれている場合はutf-8化の時にエラーが発生するため、別途処理しました。
import os
# 元のフォルダと保存先フォルダの指定
src_dir = '/content/drive/MyDrive/novel/作品/江戸川乱歩/unzip'
dst_dir = '/content/drive/MyDrive/novel/作品/江戸川乱歩/utf8'
# 保存先フォルダが存在しない場合は作成する
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 元のフォルダのテキストファイルをリストアップ
file_list = [f for f in os.listdir(src_dir) if f.endswith('.txt')]
for file_name in file_list:
# ファイルを開いてエンコードを変更する
with open(os.path.join(src_dir, file_name), 'r', encoding='shift_jis') as src_file: # ここでは例として元のエンコードをshift_jisとしています。必要に応じて変更してください。
content = src_file.read()
# UTF-8で保存する
with open(os.path.join(dst_dir, file_name), 'w', encoding='utf-8') as dst_file:
dst_file.write(content)
print("エンコード変換が完了しました!")本文抽出
見出しや注釈などを除き、本文のみ抽出します。同階層の「clean」フォルダに保存されます。
import re
import os
import glob
def convert_text(target_file):
with open(target_file, 'r', encoding='utf8') as file: #抽出したいファイル名を記載
text = file.read()
text = re.sub(r'《.+?》', '', text) # ルビの削除
text = re.sub(r'[#.+?]', '', text) # 注釈の削除
text = re.split(r'-{3,}', text)[-1] # テキスト冒頭の説明部分を削除
text = re.sub(r'^\s*[一二三四五六七八九十]+\n', '\n', text, flags=re.MULTILINE) # 行頭の漢数字の見出しを削除
text = re.sub(r'\n{3,}', '\n\n', text).strip() # 不要な空白行を削除
text = re.split(r'底本:', text)[0] # '底本'の部分で区切り、見出し、本文を抽出
# 末尾の空行を削除する
lines = text.split('\n')
while lines and not lines[-1].strip():
lines.pop()
text = '\n'.join(lines)
text = ' ' + text # 文章の先頭にスペースを追加
return(text)
def save_clean_text(text, target_file, parent_dir):
clean = parent_dir + "/clean"
if not os.path.exists(clean): # ディレクトリが存在しない場合、ディレクトリを作成する
os.makedirs(clean)
path_w = clean + "/" + os.path.basename(target_file)
with open(path_w, mode='w', encoding='utf8') as f:
f.write(text)
def main():
dir_path = '/content/drive/MyDrive/novel/作品/江戸川乱歩/utf8/'
file_list = glob.glob(os.path.join(dir_path, "*.txt"))
for target_file in file_list:
print(target_file)
text = convert_text(target_file)
parent_dir = os.path.abspath(os.path.join(dir_path, os.pardir))
save_clean_text(text, target_file, parent_dir)
if __name__ == '__main__':
main()5. データセットの作成
一般公開されているデータセットを見てみると、一問一答形式で構築されています。このデータセットの内容を覗いてみると、instrucrionに「"ヴァージン・オーストラリア航空はいつから運航を開始したのですか?"」、outputに「"ヴァージン・オーストラリア航空は、2000年8月31日にヴァージン・ブルー航空として、2機の航空機で単一路線の運航を開始しました。"」と記述されているのがわかります。すなわち、instrucrionに質問、outputに答えを書いたリストをデータセットに用います。これにより、「 日本の首都は?」のinstrucrion(質問)に「東京は、日本の首都です。」というoutput(答え)を返してくれるようになります。
さて、それでは前項で用意したデータセットを一問一答形式に置き換えます。大まかな仕組みとして、最初の5行をinstrucrion、次の5行をoutputにあてがいます。これにより、最初の5行だけ提示すると次の5行の続きを書いてくれるようになります。
もちろん以下の数値を変更することで入力、出力する行数を変更できます。
instruction_num = 5 # 入力する小説の行数
output_num = 5 # 出力する小説の行数
ただし、5行より少なくすることは推奨しません。なぜなら、学習コストが膨大になるからです。試しに1行で設定しましたが、ファインチューニングに6時間以上かかり、ネットワークの不具合により途中で学習が失敗しました。
import os
import json
import glob
def convert_json(file_name):
with open(file_name, encoding='utf8') as f:
raw_text_lines = f.readlines()
# 空行を削除
text_lines = [line for line in raw_text_lines if line.strip() != ""]
result = []
instruction_text = ""
output_text = ""
instruction_num = 5 # 入力する小説の行数
output_num = 5 # 出力する小説の行数
multiline_num = instruction_num + output_num
instruction_count = 0
instruction_flg = True
for i in range(0, len(text_lines), multiline_num):
if (i + multiline_num) <= len(text_lines): # Ensure we have enough lines left
instruction_text = "".join(text_lines[i:i + instruction_num])
output_text = "".join(text_lines[i + instruction_num:i + multiline_num])
formatted = {
"input": instruction_text,
"completion": output_text
}
result.append(formatted)
return result # 修正:結果を返します
def main():
dir_path = '/content/drive/MyDrive/novel/作品/山川方夫/clean'
path = os.path.join(dir_path, '*.txt')
file_list = glob.glob(path)
all_results = [] # すべての結果を保存するためのリスト
for file_name in file_list:
results_from_file = convert_json(file_name)
all_results.extend(results_from_file) # 得られた結果を全体のリストに追加
with open('./yamakawamasao_formatted.json', 'w', encoding='utf-8') as f:
json.dump(all_results, f, indent=4, ensure_ascii=False)
if __name__ == "__main__":
main()出力されたjsonファイルは以下です。(一部省略しています。)
[
{
"input": " 「……夏が来たのね」\n 女は、天井を見上げたままでいった。\n 白い天井。白い壁。白いシーツ。女の顔も白い。\n「空を見ていると、わかるの。ついこないだまで、どんよりと空の濁った日ばかりがつづいてたわ。まるで、水に落ちたケント紙のような色の空だったわ。……それが、見てごらんなさい、あんな真青な色になって、むくむくした力こぶみたいな雲が見えるわ」\n 女は声を落し、彼に笑いかけた。\n",
"completion": "「もう、一年になるのね」\n うなずいて、彼も窓を見やった。窓の外は、一面に濃い群青の夏の空だ。――この部屋は五階だ。なるほど、ベッドに寝たきりでいるのだったら、見えるのは空しかない。\n「学校の話をしようか?」\n 二人は、大学のクラス・メートだった。が、女はちがう返事をした。\n「お願い。窓のカーテンを閉めて」\n"
},
{
"input": " 彼はカーテンを引いた。女は、大きな呼吸をした。ふざけたような声でいった。\n「……私には、もう、夏も冬もないの。私はもう、なにも感じないわ。暑くも寒くもなく、いつも気密室に入っているみたいなのよ。みんな、他人の夏、他人の冬でしかないの」\n 何万人、いや、何百万人に一人という奇病だった。去年の夏、突然高熱を発した二十歳の彼女は、そのまま全身が動かなくなった。\n 意識は明瞭だが、五官の感覚がほとんどなく、あとは死を待つほかはないのだ。医者は、最大限一年しかもたないと明言した。その一年の期限が、もはや目の前に来ている。\n 部屋がむしむしする。彼はハンカチで汗をふいた。わざと明るい声でいった。\n",
"completion": "「うらやましいよ。暑さ知らずだなんて」\n 女は、目のすみでちらりと彼に笑った。\n「そうね。いまに文化が進歩して、人間たちが気温を一定に調節して、この世から夏や冬を追放することになるのかもしれない。……私、そんな未来の国に住んでいるみたいね」\n「そうさ」と、彼もいった。\n「そうしたら、夏や冬は、季節の名前じゃなく、土地の名前になっちまうさ。金持ちだけがそれを味わいに出かけて行く、遠い土地の名前に」\n"
},
{
"input": "「夏や冬は、つまりぜいたく品になるのね」\n 笑って、女は目をつぶった。\n「……でも、夏は、もう私にははっきりとは思い出せない。夏、夏っていくら考えても、なにか子供のころに聞いた海岸の物音みたいな遠いぼやけた思い出しか、私にはもう浮かばないの。……ねえ、夏って、どんなものだったの? 暑いって、どんなことなの?」\n 青く血管の透けるような白い頬で、女は、でも、固く目を閉ざしていた。ふいに、涙がその目じりからあふれた。頬に光の筋を引いた。\n ……やがて、彼は立ち上がった。涙の線をのこしたまま、女は眠っていた。彼は、いつもと同じように、その女の顔を、これが最後かもしれぬという気持でしばらくみつめてから、病室のドアを押した。病院の表へ出た。\n",
"completion": " 女の声が、まだ耳に聞えていた。――ねえ、夏って、どんなものだったの? 暑いって、どんなことなの?\n 突然、彼は足をとめた。夏の街を歩きながら、彼はひとつも暑くないのだ。むしろ、はだ寒ささえ感じられる。\n あわてて、彼はあたりを見た。戦慄に似たものが、彼を走りすぎた。いつのまにか、まぶしかった夏の充実した日射しは消え、どこにも夏がないのだ。――彼にも、夏がないのだ。\n 空は暗く、季節の消えた街を、不気味な冷えた風が動いている。\n「暑くなったり、急に寒くなったり、ほんとにへんな陽気ですわね」\n"
},
・・・ライブラリのインストール
各ライブラリをインストールします。
「PEFT」(Parameter-Efficient Fine-Tuning)は、モデルの全体のファインチューニングなしに、事前学習済みの言語モデルをさまざまな下流タスクに適応させることができるパッケージです。
!pip install bitsandbytes transformers
# PEFTのインストール
!pip install -Uqq git+https://github.com/huggingface/peft.git
!pip install -Uqq transformers datasets accelerate bitsandbytes
!pip install sentencepiece6. ファインチューニング
取得したjsonファイルを使って、japanese-gpt-neox-3.6bにファインチューニングします。datasetに作成したjsonファイルを設定してください。
なお、 rやlora_alphaといったハイパーパラメータは参考にした設定値から変更していません。また、回転数も変更せず、モニタリングもしていません。
import os
import torch
import torch.nn as nn
import bitsandbytes as bnb
import transformers
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
model_name = "rinna/japanese-gpt-neox-3.6b"
dataset = "./yamakawamasao_formatted_5.json"
peft_name = "lora-rinna-3.6b"
output_dir = "lora-rinna-3.6b-results"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
CUTOFF_LEN = 256
def tokenize(prompt, tokenizer):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
)
return {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}
# データセット
import json
with open(dataset, "r", encoding='utf-8') as f:
data = json.load(f)
def generate_prompt(data_point):
result = f"""### 指示:
{data_point["input"]}
### 回答:
{data_point["completion"]}
"""
# 改行→<NL>
result = result.replace('\n', '<NL>')
return result
train_dataset = []
val_dataset = []
for i in range(len(data)):
if i % 10 == 0:
x = tokenize(generate_prompt(data[i]), tokenizer)
val_dataset.append(x)
else:
x = tokenize(generate_prompt(data[i]), tokenizer)
train_dataset.append(x)
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
lora_config = LoraConfig(
r= 8,
lora_alpha=16,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
eval_steps = 200
save_steps = 200
logging_steps = 20
trainer = transformers.Trainer(
model=model,
train_dataset=train_dataset,
eval_dataset=val_dataset,
args=transformers.TrainingArguments(
num_train_epochs=30,
learning_rate=3e-4,
logging_steps=logging_steps,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
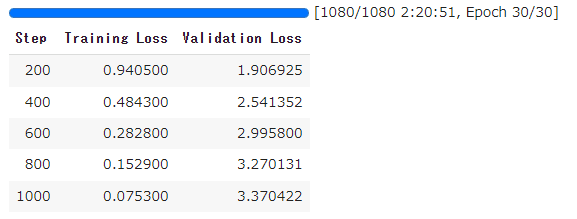
trainer.model.save_pretrained(peft_name)1080回転で2時間20分かかりました。Validation Lossが上昇しつづけているので、過学習しているようです。もしかしたら、japanese-gpt-neox-3.6b内で既に青空文庫の文章を学習させていたのかもしれません。
7. 推論・生成
入力プロンプトは以下の通りです。今回のテーマは「情報」と「図書館」なので、そのワードを含めています。
「どんな情報でも手に入る図書館って知ってる?」
恵津子は視線を動かさずに武雄に聞いた。真っ赤な口唇がかすかに笑っている。
恵津子と知り合ったのはつい一ヶ月前のことだが、その幼い顔立ちとは不釣り合いなほどミステリアスな雰囲気に、武雄はいまだに慣れないでいる。
「へえ。どんな情報でも?それって、国家機密や個人情報も含まれるのかい。
「まさか。でもそれ以外なら大抵のことはわかるわ。」import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "rinna/japanese-gpt-neox-3.6b"
peft_name = "lora-rinna-3.6b"
output_dir = "lora-rinna-3.6b-results"
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = PeftModel.from_pretrained(
model,
peft_name,
# device_map="auto"
)
model.eval()
def generate_prompt(data_point):
if data_point["input"]:
result = f"""### 指示:
{data_point["instruction"]}
### 入力:
{data_point["input"]}
### 回答:
"""
else:
result = f"""### 指示:
{data_point["instruction"]}
### 回答:
"""
# 改行→<NL>
result = result.replace('\n', '<NL>')
return result
def generate(instruction, input=None, maxTokens=256) -> str:
prompt = generate_prompt({'instruction': instruction, 'input': input})
input_ids = tokenizer(prompt,
return_tensors="pt",
truncation=True,
add_special_tokens=False).input_ids.cuda()
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=maxTokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
# 最後のEOSトークンまでデコード
if tokenizer.eos_token_id in outputs:
eos_list = [i for i, x in enumerate(outputs) if x == tokenizer.eos_token_id]
decoded = tokenizer.decode(outputs[:eos_list[len(eos_list) - 1]])
sentinel = "### 回答:"
sentinelLoc = decoded.find(sentinel)
if sentinelLoc >= 0:
result = decoded[sentinelLoc + len(sentinel):]
return result.replace("<NL>", "\n") # <NL>→改行
else:
return 'Warning: Expected prompt template to be emitted. Ignoring output.'
else:
return 'Warning: no <eos> detected ignoring output'
query = """「どんな情報でも手に入る図書館って知ってる?」\n恵津子は視線を動かさずに武雄に聞いた。真っ赤な口唇がかすかに笑っている。\n恵津子と知り合ったのはつい一ヶ月前のことだが、その幼い顔立ちとは不釣り合いなほどミステリアスな雰囲気に、武雄はいまだに慣れないでいる。\n「へえ。どんな情報でも?それって、国家機密や個人情報も含まれるのかい。」\n「まさか。でもそれ以外なら大抵のことはわかるわ。」"""
print(query)
for i in range(3):
print("**********")
print(generate(query))
print("**********")出力数を3に設定しているため、3種類の出力が得られます。
そんな会話をしながら、図書館についたときも、まさかな、という疑問はあったのだ、と彼は思った。
彼女と話すようになって、一週間たしかに時間はたったのだから。
だが図書館の彼女のデスクを前にすると、謎はたちどころに解けた。
これほどまでに彼女を知りながら、まだ彼女のことを教えてもらえない理由を、彼は背後に発生しているつめたくのしかかる重いものに気づいて、ぎくりとした。
まあ、どうだか。そこまではわからないわ」と、しばらく沈黙で武雄を時折りとらえたのち、冗舌な調子で小声で彼女はいった。
「でも、手がかりは探し出せるわ。お金はそのためよ」 そんな会話をしながら、図書館についた恵一を彼は見た。蝋細工のように整った顔だちをしていた。
唇の右端がちょっぴり切れている。おもむろに帽子を脱いだ彼は、黒いロングヘアを風になびかせ、堂々と歩いてくる。
まるで巨大な像が動いているかのような、不思議な印象の顔だつた。
こんな顔に生まれたらどんな人生を辿るのだろう。彼はふと、ジュリアン・テンプルと同じことを考えた。 そんな会話をしながら、図書館についた恵一を彼は見た。
蝋細工のように整った顔だちをしていた。唇だけが不気味に赤かった。 2つ目、3つ目の出力結果は登場人物が変わってますね。
1つ目の結果は一見よさそうですが、4行目の開きカギかっこが欠落しています。
8.結論
本来であれば、出力結果を入力プロンプトに置き換えて再度推論し、これを繰り返して文章を生成していく予定でしたが、4回試してみたところちぐはぐは文章しか生成されなかったため、中止します。
難しいものですね。後日、データセットを見直して再挑戦します。念のため、ここまでの結果を下記に記します。
プロンプト
「どんな情報でも手に入る図書館って知ってる?」\n恵津子は視線を動かさずに武雄に聞いた。真っ赤な口唇がかすかに笑っている。\n恵津子と知り合ったのはつい一ヶ月前のことだが、その幼い顔立ちとは不釣り合いなほどミステリアスな雰囲気に、武雄はいまだに慣れないでいる。\n「へえ。どんな情報でも?それって、国家機密や個人情報も含まれるのかい。」\n冗談めかしたその武雄の言い回しに、恵津子は表情を変えずに答えた。
生成された文章
「まあ、どうだか。そこまではわからないわ」と、しばらく沈黙で武雄を時折りとらえたのち、冗舌な調子で小声で彼女はいった。「でも、手がかりは探し出せるわ。お金はそのためよ」〈N〉「君は、すると泥棒の情報なら何でも持ってるというわけかい?」とやがて探るような調子の彼の質問にも、彼女は冗弄をこめて首を振った。
小麦色の顔に、少年のように柔軟な肩を波打たせて武雄はうなずいた。そして、カバンを持った。
小春日の午後は人の顔も見えず、ひっそりと静かだった。武雄はその初冬の陽をすかしてうつむき、爪先きでリズムをとっているほか、なにも考えていないようだった、もっぱらそのことは、熱心に彼女はやっていなかった。睡ることと食べることで、その全身の力をことごとく傾けていたのだ。
ところが、ある午後、道の上をよくきしるバスの音が流れて、あとは雨になった春の夕暮近く、武雄は図書館のベンチのはしに、折りたたんだベンチコートをひかけて、うとう