
【論文解説】HybridRAG:知識グラフとベクトル検索による効率的な情報抽出

要点
HybridRAGは、知識グラフ(KG)とベクトル検索(VectorRAG)を組み合わせた新手法で、財務文書からの情報抽出を大幅に改善。
実験結果では、HybridRAGがVectorRAGとGraphRAG単独使用よりも、文書検索精度と回答生成で優れた性能を示す。
この技術は金融分野以外にも適用可能で、より広範な情報抽出と分析に活用できる。
論文本文の紹介
論文のタイトル:HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
論文タイトル(日本語訳):HybridRAG: 知識グラフとベクトル検索を統合した効率的な情報抽出技術
論文解説
1. はじめに
金融業界では、非構造化データからの価値ある情報抽出が極めて重要です。大規模言語モデル(LLMs)は強力なツールですが、金融文書特有の課題に直面します:
専門用語の理解:金融特有の用語や概念の適切な処理
複雑なデータ形式:多様な形式の財務データの解釈
文脈の把握:企業間や市場全体の関連性の理解
これらの課題は、不正確な分析や見落とされた洞察につながる可能性があります。
2. 提案手法:HybridRAG
HybridRAGは、VectorRAGとGraphRAG技術を組み合わせた革新的なアプローチです。
2.1 VectorRAGの概要
VectorRAGは文書をベクトル化し、効率的に関連情報を検索します。
主な特徴:
大規模テキストコーパスからの効率的な情報検索
意味的類似性に基づく柔軟な検索
文書全体の文脈を考慮した検索
2.2 GraphRAGの概要
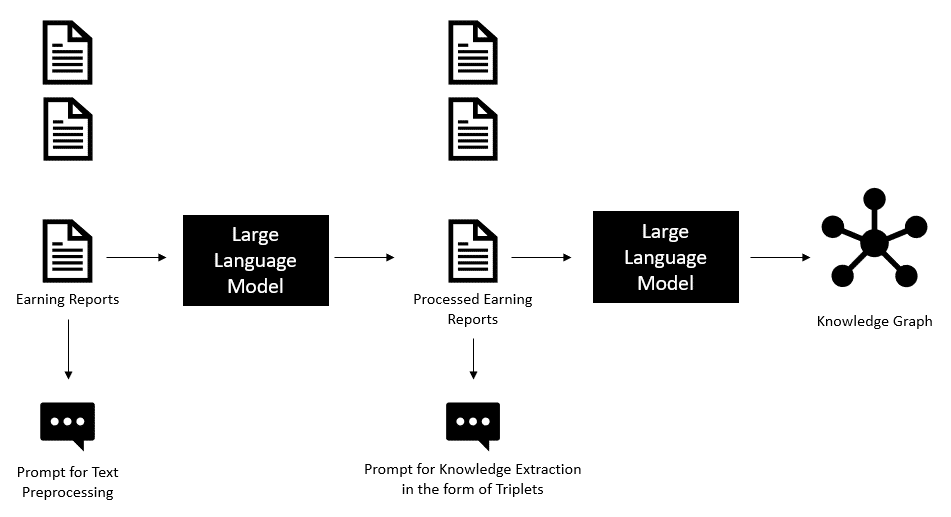
GraphRAGは知識グラフ(KG)を用いて構造化情報を検索し、文脈に基づいた回答を生成します。
主な特徴:
実体間の関係性の明示的表現
複雑なクエリや推論タスクへの適応性
文書間の関連性の把握
2.3 HybridRAGの統合プロセス
文書の前処理:金融文書を適切なサイズのチャンクに分割
ベクトル化:各チャンクをベクトル表現に変換し、データベースに格納
知識グラフの構築:文書から実体と関係を抽出し、KGを構築
統合検索:ベクトルデータベースとKGから関連情報を検索
コンテキスト生成:検索結果を組み合わせてLLMへの入力を生成
回答生成:LLMがコンテキストを利用して回答を生成
この統合アプローチにより、テキストの意味的類似性と構造化知識の両方を活用した包括的な情報検索と回答生成が可能になります。
3. 実験と結果
3.1 実験設定
データセット:Nifty 50企業の2023年第1四半期決算報告書
サンプルサイズ:50社、合計400の質問-回答ペア
3.2 評価指標
忠実性:生成回答のコンテキストからの推論可能性
回答の関連性:生成回答の質問への適合度
コンテキストの精度:検索コンテキストと正解の一致度
コンテキストの再現率:正解情報の検索コンテキストへの含有率
主な発見:
HybridRAGは忠実性と回答の関連性で最高スコアを達成
GraphRAGはコンテキストの精度で最高スコアを示す
VectorRAGとHybridRAGはコンテキストの再現率で完璧なスコアを達成
HybridRAGのコンテキスト精度が低いのは、より多くの情報を含むためですが、これが回答の質向上につながっています。
4. 考察と応用
4.1 HybridRAGの優位性
多角的な情報検索:ベクトル検索と知識グラフの組み合わせによる包括的な情報収集
補完的な強み:VectorRAGの文脈把握とGraphRAGの関係性抽出の相乗効果
柔軟な回答生成:多様な情報源に基づく適応性の高い回答
4.2 実際の応用シナリオ
決算分析の効率化:複数企業の迅速な比較分析
リスク評価:企業間関係や市場動向を考慮した包括的評価
投資戦略の立案:データ駆動型の戦略策定
4.3 他分野への応用可能性
医療情報システム:診療記録や医学文献からの情報抽出
法律文書分析:判例や法令文書の効率的な検索と分析
学術研究支援:大量の論文からの関連研究抽出と動向把握
5. 結論と将来の方向性
HybridRAGは、非構造化データからの情報抽出において高い有効性を示しました。今後の研究課題として以下が挙げられます:
マルチモーダルデータの処理:テキストと視覚データの統合
数値データの分析能力強化:財務指標や統計データの効果的処理
リアルタイムデータへの対応:動的な情報源に適応するシステム構築
説明可能性の向上:回答の根拠を明確に示す手法の開発
LLMsの効率的利用:計算リソースを考慮した最適化
HybridRAGは情報抽出と知識獲得に新たな可能性を開きます。今後の研究と実践を通じて、より広範な分野での活用が期待されます。
この記事が気に入ったらサポートをしてみませんか?