
音声分析ソフトウェアPraatとアノテーションフォーマットTextGrid形式について

こちらの記事は、2019年11月1日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
はじめに
こんにちは、レトリバのエンジニアの岩田です。最近はリバウンドに悩みながら音声認識エンジンの製品開発をしています。
今回は、音声分析ソフトウェアのPraatと、Praatで読み込んだり保存できる音声のアノテーションフォーマットTextGrid形式について紹介したいと思います。おまけとして、TextGrid形式のファイルを読み書きするライブラリ textgrid.hpp を簡単に実装したので紹介します。
音声分析ソフトウェアPraat
Praat(プラート)は、オープンソース(GPLv2)の音声分析ソフトウェアです。 MacやWindows、LinuxやFreeBSDなど複数のプラットフォームでバイナリが配布されています。 Praatを使うことで、音声の録音や分析、アノテーションなどを行えます。 また、Praatのスクリプトを書くことで、指定したフォルダ内の全音声ファイルを順番に解析する、といったことが簡単に行えます。
音声の分析と言っても様々ですが、Praatで音声の波形データとスペクトログラムを見てみましょう。
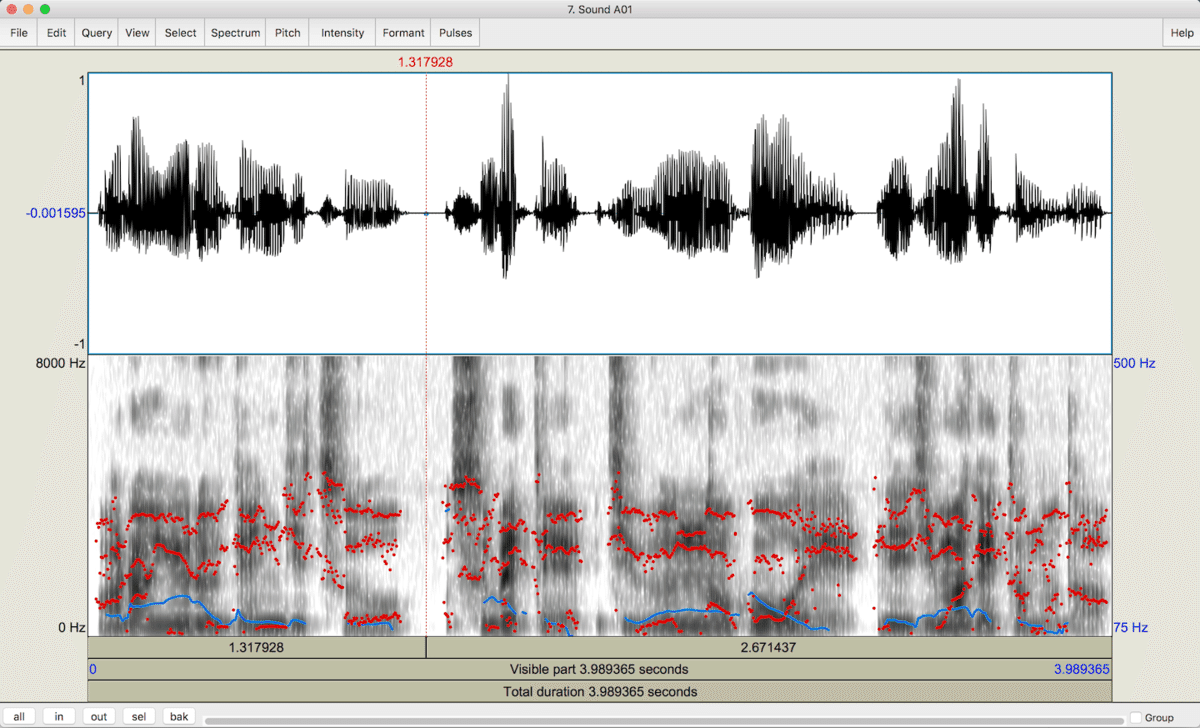
指定した区間の音声を再生したり、拡大縮小表示することもできます。他には、ピッチ解析やフォルマント分析など、音声の様々な特徴をもちいて分析することもでき、非常に便利なソフトウェアです。
Praat以外にも音声分析のフリーソフトはたくさんあり、 WaveSurfer や Audacity などが有名です。 興味のある方は フリーソフトを用いた音声処理の実際 などをご覧ください。
アノテーションフォーマットTextGrid形式
Praatを使って音声データに対してアノテーションした情報は、TextGrid形式でファイルに保存したり読み込めます。
TextGrid形式で保存できる情報は、次の2種類を押さえておけば大丈夫です。
interval tier: 区間に対するアノテーション。開始時刻と終了時刻で指定される区間に対して文字列(例: 単語、読み、音素など)を付与する。区間はオーバーラップしない。
point tier: 点に対するアノテーション。特定の時刻(点)に対して文字列を付与する。
1つのTextGrid形式のファイルには複数の層(tier)を保存することができ、各層ごとにinterval tierやpoint teirといった層の種類を決めて情報を付与することができます。 また、1つの層は複数の情報(intervalやpoint)を含んでおり、時刻の昇順に並んでいます。
実際に先ほどの例の音声データにアノテーションを付けると、次のようになります。

TextGrid形式の実際のデータを見てみましょう。
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0
xmax = 3.9893650793650792
tiers? <exists>
size = 1
item []:
item [1]:
class = "IntervalTier"
name = "単語"
xmin = 0
xmax = 3.9893650793650792
intervals: size = 23
intervals [1]:
xmin = 0
xmax = 0.04164132431058888
text = ""
intervals [2]:
xmin = 0.04164132431058888
xmax = 0.5574000052695588
text = "あらゆる"
intervals [3]:
xmin = 0.5574000052695588
xmax = 0.575465489542943
text = ""
intervals [4]:
xmin = 0.575465489542943
xmax = 0.9958441404615553
text = "現実"
intervals [5]:
xmin = 0.9958441404615553
xmax = 1.0003172632539812
text = ""
intervals [6]:
xmin = 1.0003172632539812
xmax = 1.2113897371395872
text = "を"
intervals [7]:
xmin = 1.2113897371395872
xmax = 1.4156967091301467
text = ""
intervals [8]:
xmin = 1.4156967091301467
xmax = 1.9208576089735214
text = "すべて"
intervals [9]:
xmin = 1.9208576089735214
xmax = 2.025607136616711
text = ""
intervals [10]:
xmin = 2.025607136616711
xmax = 2.4053609599255426
text = "自分"
intervals [11]:
xmin = 2.4053609599255426
xmax = 2.406244108351842
text = ""
intervals [12]:
xmin = 2.406244108351842
xmax = 2.5272354427548884
text = "の"
intervals [13]:
xmin = 2.5272354427548884
xmax = 2.571852760478189
text = ""
intervals [14]:
xmin = 2.571852760478189
xmax = 2.7557684202550825
text = "ほう"
intervals [15]:
xmin = 2.7557684202550825
xmax = 2.7565057092069747
text = ""
intervals [16]:
xmin = 2.7565057092069747
xmax = 2.9843580031922734
text = "へ"
intervals [17]:
xmin = 2.9843580031922734
xmax = 3.0746639210234625
text = ""
intervals [18]:
xmin = 3.0746639210234625
xmax = 3.5533303680778494
text = "ねじ曲げ"
intervals [19]:
xmin = 3.5533303680778494
xmax = 3.663416635923271
text = "た"
intervals [20]:
xmin = 3.663416635923271
xmax = 3.663858210136421
text = ""
intervals [21]:
xmin = 3.663858210136421
xmax = 3.785732692965767
text = "の"
intervals [22]:
xmin = 3.785732692965767
xmax = 3.9588297845204896
text = "だ"
intervals [23]:
xmin = 3.9588297845204896
xmax = 3.9893650793650792
text = ""最初にヘッダ情報(ファイル形式や層の数など)があり、そのあとに層ごとのアノテーションの情報が続く構造になっています。 詳細な構文や制約に関しては、本家のドキュメントの TextGrid file formats を参照してください。
Praatはアノテーション(音声コーパスの構築作業)にも使われており、 日本語話し言葉コーパス(CSJ) や理研母子会話コーパス(R-JMICC)のコーパスの構築に実際に使われているそうです。 また、TextGridの利用方法で説明されているように、日本語話し言葉コーパスは複数の形式でアノテーション情報を提供しており、その中にTextGrid形式もあります。
TextGrid形式の他の活用方法としては、音声認識や発話区間検出の結果をTextGrid形式で出力して評価に利用することも考えられます。
TextGrid形式を読み書きするライブラリ
TextGrid形式をPraat以外のプログラムでも扱えると音声コーパスの活用や音声認識システムの評価に利用できるので、とても便利です。
TextGrid形式の読み込みや書き込みを行えるライブラリはいくつかあり、pythonだと textgrid.py や TextGridTools があります。
しかし、マイナーすぎるためか、いろんな言語でライブラリが実装されているわけでもなく、次のような特徴をもつ textgrid.hpp というライブラリを自分で簡単に実装してみました。
C++11
シングルヘッダーかつヘッダーオンリー
依存ライブラリなし(標準ライブラリのみ利用)
文字コードはUTF-8のみサポート
実装した機能の通りです。
データを保持するためのクラス(構造体)
TextGrid、Tier、IntervalTier、PointTier、Interval、Pointなど
入力ストリームからTextGrid形式のデータを読み込む機能
TextGrid形式のParser(+Lexer)
出力ストリームへTextGrid形式でデータを書き出す機能
TextGridオブジェクトのデータにアクセスするためのTextGridVisitor
一番面倒だったのはTextGrid形式の解析を行うParserでした。 TextGrid file formats のドキュメントに詳細なファイル形式の説明がありますが、人間が読みやすいゆるい形式と機械可読な短い形式があります。 最終的には両方読み込めるようにしたのですが、実装している最中は、ファイルフォーマットの仕様がもっと簡素だったら構文の定義と構文解析の実装がもっと楽だったよね、という気持ちと、たまには構文解析を手書きで実装するのも楽しいよね、という気持ちがせめぎ合いました。
標準入力からTextGrid形式のデータを読み込んで、そのまま標準出力に出力する簡単なサンプルプログラムは次のように簡単に書くことができます。
#include <iostream>
#include "textgrid.hpp"
int ReadAndWrite(bool in_short = false) {
try {
textgrid::Parser parser(std::cin);
textgrid::TextGrid text_grid = parser.Parse();
if (in_short) {
textgrid::ShortWriter writer(std::cout);
text_grid.Accept(writer);
} else {
textgrid::Writer writer(std::cout);
text_grid.Accept(writer);
}
return 0;
} catch (const textgrid::Exception& e) {
std::cerr << e.what() << std::endl;
return -1;
}
}
int main() {
return ReadAndWrite();
}1000行に満たないライブラリですが、発話区間検出のアルゴリズムの評価を行うコマンドを実装するのに使っていて、いまのところうまく動いています。
足りない機能は色々ありますが、次の機能は近々必要になるかもしれないと考えています。今後の課題です。
TextGridオブジェクトを構築しやすいインタフェース
アノテーション情報の編集を行うインタフェース
アノテーション情報の不変性(区間はオーバーラップしない、など)のチェック
Pitch Tierのサポート
まとめ
音声分析ソフトウェアのPraatと、アノテーションフォーマットTextGrid形式について紹介しました。
音声データを扱って何かするときに役に立つ...かもしれません。
Praatの詳しい使い方が知りたくなった方には、音声解析ソフトウェア Praat と 音声学(筑波大学 2010年度) 授業 の記事をおすすめしておきます。