
Big Birdの紹介

※こちらの記事は、2021年4月28日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
Chief Research Officer兼カスタマーサクセス部リサーチャーの西鳥羽 (Jiro Nishitoba (@jnishi) | Twitter) です。
昨年のNeurIPSで発表されたBig Birdが興味深かったので紹介します。
Big Birdの概要
Big BirdはTransformerの一種です。
Transformerは自然言語処理、音声認識等含めて系列に対するタスクに対して強力な手法です。
しかし、系列の長さの2乗の計算時間及びメモリ領域を必要としており、要約や音声認識など長い系列の処理についてはこの点が課題になります。
Big BirdはTransformerと同じような処理を系列の長さに比例する時間とメモリ領域で実現しています。
Big Birdは系列の長さに比例する時間とメモリ領域での計算をattentionに対する工夫で実現しています。
attentionにおける工夫
詳細は論文を参照していただければと思いますが、Transformerでは系列の全要素から全要素に対応するattentionを計算しているところを、以下の3つのattentionで代替しています。
(a) Random Attention: 各要素で一定数の他の要素をランダムに選び、その間のみattentionを計算する。
(b) Window Attention: 近傍のみattentionを計算する。
(c) Global Attention: 先頭と他の要素のattentionを計算する。
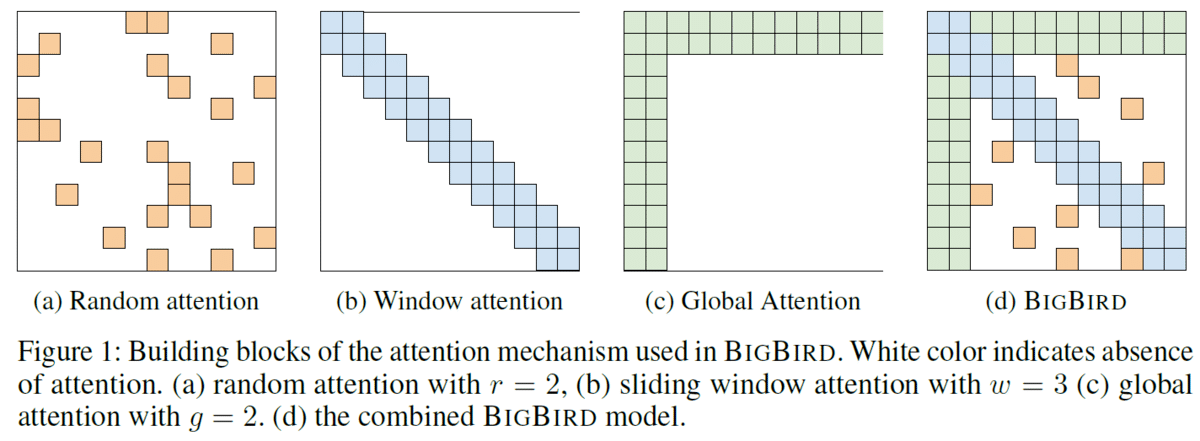
Transformerではこの図で示される全マスを計算します。そのため、系列の2乗個の計算が発生します。
Big Birdでは(d)のようにこれら3つのattentionを組合せてBig Birdのattentionとして計算します。(a), (b), (c)はそれぞれ系列長に比例する個数になるので、全体としても系列長に比例する時間とメモリ領域で計算できます。
Random Attention
Random Attentionは各要素ごとに事前に指定するr個の要素を選び、attentionの計算をする方法です。図ではr=2の例となっており、各行に2個の色がついているマスが存在します。
頂点数n、枝数がnに比例するランダムグラフでは任意の2ノードに対して log n 程度の長さの最短路が存在するというランダムグラフの性質により、このグラフ上のランダムウォークで情報が行き渡るのでTransformerの全対全のattentionのスパースな近似として用います。
Window Attention
Window Attentionは近傍のw個の要素にのみattentionを計算する方法です。図では w=3の例となっていて各要素と前後1マスをあわせた部分に色がついています。
NLPや計算生物学でのタスクの場合、要素に対して近傍に関係のある情報があることが多いため近傍の情報は特に用いるようにこのWindow Attentionを用います。
Global Attention
Global Attentionはg個の要素のみ全要素へのattentionを計算する方法です。図ではg=2の例となっていて先頭2個の要素は全要素とのattentionを計算します。
この全要素へのattentionを計算する要素の選び方は2種類あります。1つ目はinternal transformer construction(ITC)と呼ばれ、系列の要素内から選ぶ方法です。もう一つはexternal transformer construction(ETC)と呼ばれBERTのCLS tokenなど系列の外部から与える要素を選ぶ方法です。
理論的解析
Big BirdはTransformerと比べてかなりスパースなattentionのモデルとなりますが、Transformerが持つと示されている一部の計算力について同様にBigBirdも持つことが示されています。
具体的にはTuring completeness(※1)とUniversal approximation(※2)について成り立つことが示されています。上記のようなTransformerと比べて少ないattentionでも割と強力なモデルであることが示されています(※3)。
実験結果
QA、文書要約、ゲノミクスなど様々なタスクについて比較されていました。全般的に長い文書を必要とするタスクについて効果が高いようです。
QA
Natural Questions、HotpotQA、TriviaQA-wiki、WikiHopの4つのQAタスクについて、それぞれの精度上位の手法と比較しています。Big Birdは単一のタスクに特化しているモデルではなく、様々なタスクにおいて最高精度あるいはそれに近い精度を出せるモデルとなっています。

要約
Arxiv、PubMed、BigPatentデータセットにおける文書要約です。文書要約についてはタスクの性質上入力文章が長く、長い系列の学習が行えるというBig Birdの特性が活きる形になっています。そのため、全てのデータセットで最高精度を達成しています。

ゲノム
自然言語ではありませんが、ゲノムデータに対するタスクにも実験されています。A、T、G、Cの塩基を文字と解釈するとDNAは文字による系列として扱えます。この時、DNAの長さは非常に長いので、長い系列のタスクとなります。この論文ではPromoter Region PredictionとChromatin-Profile Predictionの2つに対して実験しています。ここではPromoter Region Predictionのみ紹介します。
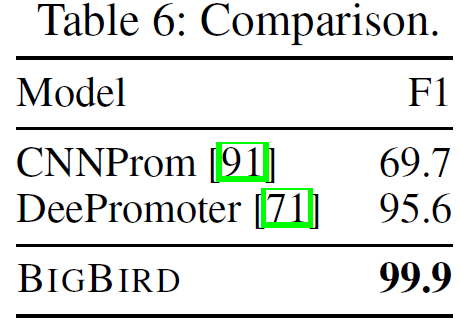
Promoter Region Predictionは与えられた塩基配列がPromoter領域かどうかを判定するタスクです。ヒトゲノムのDNAを事前学習に用い、Promoter領域を含む長さ8000塩基対のゲノムを学習データとしています。F1値で99.9とほぼ確実に判定できるようです。
まとめ
今回はTransfomerよりも長い系列に強いBig Birdの紹介をしました。
Random Attention、Window Attention、Global Attentionを用いることにより系列長に比例する計算量とメモリ使用量で学習を行うことができ、BERTでは難しかった長い系列での適用を可能にしています。
個人的には機械学習の新しいモデルの提案で、Random Graphの性質による解析や計算モデルとしての性質まで示している論文は珍しいので興味深かったです。
なお、Hugging Face Transformersに実装されているので、次回は実際に動かして試してみたいと思います。
※1:万能チューリングマシンと同等の計算能力をもつことであり、ざっくり言うとこの性質をもつものはプログラミング言語を使って実装できる計算を実現できます。
※2:いくつかの条件のもと、任意の関数を近似できるであるということです。
※3:ちなみにTransformerではUniversal Approximationはこちら、Turing Completenessはこちらで成り立つことが示されています。