
事前学習モデルBARTを使って日本語文書要約をやってみた

※こちらの記事は、2021年5月24日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
こんにちは。 カスタマーサクセス部リサーチャーの勝又です。 私はレトリバで自然言語処理、とくに要約や文法誤り訂正に関する研究の最新動向の調査・キャッチアップなどを行っております。
今回の記事では、事前学習モデルであるBARTを使って日本語文書要約を行った話を紹介します。
概要
近年、自然言語処理の分野では事前学習を利用した研究が盛んに行われています。 有名な事前学習モデルとしては、BERT(Bidirectional Encoder Representations from Transformers)1と呼ばれるモデルが盛んに研究されています。 事前学習モデルの良いところとして、アノテーションされていないテキストデータを用いて事前学習を行うことで、実際に解きたい課題の精度が向上することが挙げられます。
今回は、BERTではなく、BART(Bidirectional and Auto-Regressive Transformers)と呼ばれる事前学習モデルを用いて抽象型要約を行いました。 BERTを利用した抽象型要約は以前の記事や、言語処理学会第27回年次大会(NLP2021)の発表2をご確認ください。
BARTの簡単な説明
BARTに関しては以前の記事でも解説しているので、ここでは簡単な説明といたします。
BARTはTransformer3 Encoder-Decoderを大量のテキストデータで事前学習したモデルです。 この事前学習されたBARTに対して、英語要約タスクでfine-tuningを行うことで、高い精度となることが報告されています。
今回、日本語のテキストデータで学習されたBARTが公開されていたので、そのモデルに対して日本語要約タスクでfine-tuningを行いました。 また、実際に公開された事前学習モデルを使ってみて注意が必要と感じた箇所があったので、その際の対処についても解説します。
BARTの未知語問題への対応
基本的に、事前学習モデルは一番最初、つまり事前学習時に決めた語彙しか扱うことができません。 そのため、語彙に含まれていない単語は<unk>のように未知語トークンとして扱います。
サブワードと呼ばれる、通常の単語より小さい単位を入力単位とすることで、この未知語の数を減らすことができます。 このサブワードの作り方にもいくつか方法があり、今回使用する日本語BARTはSentencepiece4と呼ばれる手法を用いています。 しかしながら、サブワードを用いても未知語がなくなることはなく、要約タスクの場合、出力した要約文に未知語トークンが含まれることが多々あります。
今回はサブワードに追加して、Transformer内部の注意機構(attention)を用いて未知語問題に対応します。 Transformerは内部に注意機構と呼ばれる構造があります。 この注意機構は要約を出力する際に、入力文書の各単語をどのくらい見るのか計算するものです。 注意機構を利用することで、未知語トークンを出力した時にどの入力単語を見ていたのかわかるので、この情報をもとに出力された未知語トークンを入力単語に置換します5。
この未知語トークンを入力単語に置換する際に、注意機構の出力が必要になるのですが、ここで一つ注意が必要な箇所がありました。 公開されている日本語BARTはfairseqと呼ばれる、Pythonで記述されたツールを使うのですが、実装をそのまま使うと、推論時に注意機構の出力が得られません。 fairseqは推論を行う際に、SequenceGeneratorと呼ばれるクラスで推論をコントロールします。 ただし、注意機構の出力を得るためには、SequenceGeneratorではなく、SequenceGeneratorWithAlignmentと呼ばれるクラスを用います。 ここで問題になってくるのが、fairseqのBARTではこの推論をコントロールするクラスがSequenceGeneratorで固定されている点です。 そのため、以下のように、推論をコントロールするクラスを作成する関数内でSequenceGeneratorWithAlignmentを呼べるようにする必要があります。
def build_generator(self, models, args):
if getattr(args, 'score_reference', False):
from fairseq.sequence_scorer import SequenceScorer
return SequenceScorer(
self.target_dictionary,
eos=self.tgt_dict.eos() if self.args.langs is None else self.tgt_dict.index('[{}]'.format(self.args.target_lang))
)
else:
if getattr(args, 'print_alignment', False):
from fairseq.sequence_generator import SequenceGeneratorWithAlignment
seq_gen_cls = SequenceGeneratorWithAlignment
else:
from fairseq.sequence_generator import SequenceGenerator
seq_gen_cls = SequenceGenerator
return seq_gen_cls(
models,
self.target_dictionary,
beam_size=getattr(args, 'beam', 5),
max_len_a=getattr(args, 'max_len_a', 0),
max_len_b=getattr(args, 'max_len_b', 200),
min_len=getattr(args, 'min_len', 1),
normalize_scores=(not getattr(args, 'unnormalized', False)),
len_penalty=getattr(args, 'lenpen', 1),
unk_penalty=getattr(args, 'unkpen', 0),
temperature=getattr(args, 'temperature', 1.),
match_source_len=getattr(args, 'match_source_len', False),
no_repeat_ngram_size=getattr(args, 'no_repeat_ngram_size', 0),
eos=self.tgt_dict.eos() if self.args.langs is None else self.tgt_dict.index('[{}]'.format(self.args.target_lang))
)
なお、この関数はfairseqレポジトリ内のfairseq/tasks/translation_from_pretrained_bart.py内で記述されており、推論時に--print_alignmentをパラメーターとして入力することで、SequenceGeneratorWithAlignmentを使用した注意機構の出力を得ることができます。
実験
日本語BART6に対して要約タスクでfine-tuningを行い、性能評価を行います。
実験設定
日本語要約タスクについて
要約タスクとして、次の3種類を実験しました。
Livedoor News 1K
Livedoor News 10K
wikiHow
1番と2番のLivedoor Newsの1Kと10KはそれぞれLivedoor Newsから作成した3行要約データセット7に対して学習、評価を行っています。 1番と2番の違いは学習データの量で、1Kは学習データが1,000件、10Kは学習データが10,000件となっています。 1番と2番を比較することで学習データの量と要約精度の関係を調査します。 また、3番ではwikiHowデータセットに対して学習、評価を行っています。 wikiHowデータセットの学習データは3,040件なので、比較的少量サイズのデータセットであり、1番と3番の実験結果から少量データに対する要約モデルの振る舞いを確認します。
比較手法について
比較手法として、いくつかの抽出型、抽象型要約を実験しました。
LEAD-3(記事の上から3文までを要約とみなす手法)
Pointer-Generator
UniLM
JASS
mT5
1番が教師なし抽出型要約で、2~5番が教師あり抽象型要約です。 また、2番のみ事前学習を利用しないモデルで、3~5番は事前学習モデルを利用したモデルとなっております。 3番のUniLMはBERTを元にした要約モデルです。 それぞれの詳細についてはNLP2021の発表をご確認ください。
実験結果
要約の自動評価尺度であるROUGE-1, 2, Lで評価を行いました(すべてF値)。 これらの指標は大きい方が要約精度が高いことを示します。
Livedoor News
以下の表はそれぞれ、Livedoor News 1Kと10Kでの要約結果です。
Livedoor News 1K
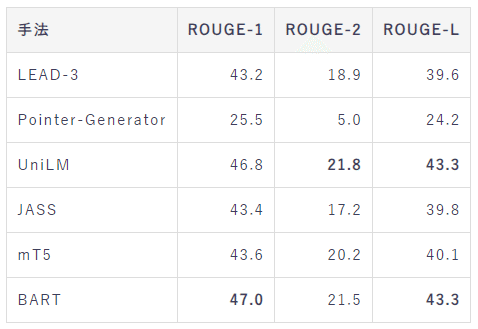
Livedoor News 10K

Livedoor News 1Kの結果から、BARTとUniLMがもっとも高いスコアであることがわかります。 また、Livedoor News 10KではBARTのみがもっとも高いスコアとなりました。 この結果から、学習データが数万件ある状況ではBARTを用いた要約が優れていますが、数千件であればBARTとUniLMに大きく差はないと考えられます。
wikiHow
以下の表はwikiHowでの要約結果です。

wikiHowでは、UniLMがもっとも高いスコアであり、その次にBARTが高い結果となりました。 ROUGE-1やROUGE-Lから、数千件の学習データではUniLMとBARTに大きく差が出ないこともわかります。 一方で、ROUGE-2ではUniLMの方がBARTより1ポイント以上高く、Livedoor News 1Kと比較すると、傾向が少し異なることもわかります。
出力例
wikiHowのHow to 勉強に対する姿勢を改善するエントリに対する出力例が次の通りです(入力文書は長いためここでは省略します)。

事前学習を利用していないPointer-Generatorと比べて、BARTは自然な要約が生成されていることがわかります。 また、事前学習を利用したmT5は同一文を繰り返してしまい、うまく要約が出力されませんでしたが、BARTはとてもうまい要約が出力されているのではないでしょうか。
この出力例以外も確認してみたところ、出力要約の単語数がかなり多かったので、平均出力単語数についても確認してみました。 事前学習を行っていないPointer-Generatorが12.6単語、UniLMが26.2単語、BARTは41.8単語と、BARTはかなり長い要約を出力することがわかりました。
まとめ
今回の記事では、事前学習モデルであるBARTを利用した要約実験を試しました。 結果としては、学習データの量によってBARTが優れた場合、BERTを元にしたUniLMが優れた場合があることがわかりました。 今後は、T5などの他の事前学習モデルを利用した場合の要約精度について確認したいと思います。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. [paper]
事前学習モデルを用いた少量データに対する日本語抽象型要約. 勝又智. [paper]
Attention Is All You Need. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. [paper]
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. Taku Kudo, John Richardson. [paper]
注意機構は明示的に入力単語と出力単語の対応を学習しているわけではないので、残念ながらこの方法では未知語トークンが正しい単語に置換される保証はありません。しかし、何もしないままだと未知語トークンが残ってしまうので、今回は簡単な手法で対応しています。
今回は日本語BARTとして、こちらのBART base v 2.0を使用します。
TL;DR 3行要約に着目したニューラル文書要約. 小平知範, 小町守. [GitHub]