
BERTを利用した日本語文書要約をやってみた

※こちらの記事は、2020年8月28日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
こんにちは。 カスタマーサクセス部リサーチャーの勝又です。 私はレトリバで自然言語処理、とくに要約や文法誤り訂正に関する研究の最新動向の調査・キャッチアップを行っております。
今回の記事では、以前作成した日本語wikiHow要約データに対して、BERTを用いて抽出型、抽象型要約を行った話をします。
概要と背景
前回の記事ではwikiHowから日本語要約データを作成しました。 その記事内では、簡単な要約実験として教師なし抽出型要約を試しました。 今回は、BERTを利用した抽出型、抽象型要約を用いて要約実験を行いたいと思います。
wikiHow要約データの特徴
前回の記事の再掲になりますが、wikiHow要約データ量は次の通りとなっています。

(ここでのサイズは要約データの(記事, 要約)の対の数を指します。)
英語の要約研究でよく使用されるCNN/Daily Mailデータは学習データだけで28万件はあります。 一方で、wikiHow要約の学習データは3千件ほどと、かなり少ないものとなっています。
BERTを用いた要約
今回、この学習データが少量である問題に対して、BERTを用いて取り組んでいきます。 具体的には、抽出型要約、抽象型要約の2種類について試しました。 抽出型要約、抽象型要約についてはこちらの記事[1]をご覧ください。
抽出型要約
抽出型要約として、今回の実験ではLiu and Lapata[2]の手法(BERTSUMEXT)を用いました。 この手法では、次の図の通りBERTに対してさらにTransformer Encoderと呼ばれる層を足して、各文ごとに、要約文書に含むか含まないかの2値分類を行います。

抽象型要約
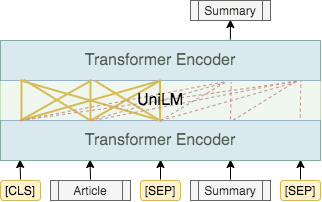
抽象型要約として、今回の実験ではDongらの手法[3](UniLM)を用いました。 従来のBERTは、内部のTransformer Encoder間を双方向に繋いでいます(図の実線部)。 UniLMは入力となる記事側は従来のBERTと同様に双方向で繋ぎますが、出力となる要約側は片方向で繋いでいます(図の点線部)。 UniLMはこのように繋ぎ方を工夫することで、BERTの構造を利用しつつ、要約の生成を可能にしています。
実験
それでは、wikiHowデータに対して、上記のBERTを用いた要約手法を試してみたいと思います。
実験設定
比較手法として、いくつかの抽出型、抽象型要約を実験しました。
1と2が教師なし抽出型要約で、3が教師あり抽象型要約です。 また、BERTSUMEXTやUniLMは公開されているこちらのBERTモデルを使用しました。
実験結果
要約の自動評価尺度であるROUGE-1, 2, Lで評価を行いました。(すべてF値) これらの指標は大きい方が要約精度が高いことを示します。

この結果からROUGE-1に関してはBERTSUMEXTが、ROUGE-2やROUGE-Lに関してはUniLMが一番良いことがわかります。 とくに、UniLMに関してはwikiHowデータが少量にもかかわらず、抽出型要約と遜色ない精度を出すことができました。
まとめ
今回の記事では、前回作成したwikiHowの要約データに対してBERTを利用した要約実験を試しました。 結果として、BERTを利用することで抽出型、抽象型要約どちらでも高い精度が確認できました。 しかしながら、BERTを用いた要約にはBERTの文長制限の問題などが存在しています。 今後はこの問題点や、もっと人が使いやすい要約モデルについて調査を行っていきます。
Text Summarization with Pretrained Encoders. Yang Liu and Mirella Lapata. [paper]↩
Unified Language Model Pre-training for Natural Language Understanding and Generation. Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. [paper]↩
LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. Gunes Erkan, Dragomir R. Radev. [paper]↩
Get To The Point: Summarization with Pointer-Generator Networks. Abigail See, Peter J. Liu, Christopher D. Manning. [paper]↩