
日本語T5モデルの公開

Chief Research Officerの西鳥羽(https://twitter.com/jnishi)です。日本語データによる学習を行ったT5モデルを公開いたしました。Huggingface hubから取得できます。今回はsmall, base, largeについてそれぞれ学習step数を変えて3種類ずつ、および XLのモデルを公開いたしました。
t5-small-short: https://huggingface.co/retrieva-jp/t5-small-short
t5-small-medium: https://huggingface.co/retrieva-jp/t5-small-medium
t5-small-long: https://huggingface.co/retrieva-jp/t5-small-long
t5-base-short: https://huggingface.co/retrieva-jp/t5-base-short
t5-base-medium: https://huggingface.co/retrieva-jp/t5-base-medium
t5-base-long: https://huggingface.co/retrieva-jp/t5-base-long
t5-large-short: https://huggingface.co/retrieva-jp/t5-large-short
t5-large-medium: https://huggingface.co/retrieva-jp/t5-large-medium
t5-large-long: https://huggingface.co/retrieva-jp/t5-large-long
T5
T5はTransformerベースのEncoder-Decoderモデルです。機械翻訳や文書要約などの生成系のタスクに用いられることが多いです。
また、今回学習したモデルはT5 v1.1で下記の点が元々のT5と比較して変更されています。
Feed forward network部分の活性化関数にGEGLUを利用
事前学習時にはdropoutを用いないように変更(ファインチューニング時にはdropoutを利用)
Embedding layerとClassifier layerでのパラメータ共有を行わないように変更
パラメータ数3Bと11Bのモデルにおいて、feed forward networkのattention head数を変更
事前学習をC4のみで行い、下流タスクでの事前学習を行わないよう変更(今回は日本語のデータで学習しているのでこちらの変更は関係ありません)
学習
今回のT5の学習においては全て日本語のデータを用いて学習しています。用途に応じて選択できるように様々なサイズや学習step数のモデルを公開いたしました。以下が学習の詳細になります。
学習データ
今回のモデルの学習には以下のデータを使いました。
Multilingual C4 / Japanese(mC4/ja)
日本語Wikipedia version 20220920
mc4/jaについては下記の処理を行っています。
ひらがなを全く含まない文書を削除
.jpや.comなどTop level Domainでのホワイトリスト形式でのURLによるフィルタリング
学習設定
学習にはT5Xを用いました。
ハイパーパラメータは言及の無いものについてはにT5Xのデフォルトに従っています。
モデルサイズは以下のようになっています。
small: 60 million程度
base: 220 million程度
long: 770 million程度
XL: 3 billion程度
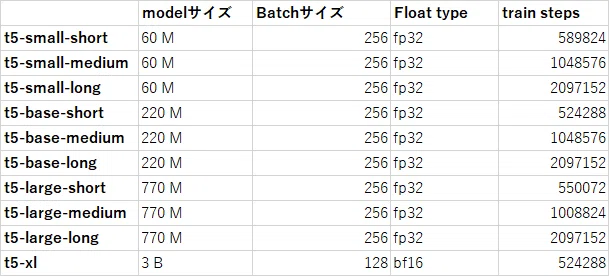
small、base、largeについては524,288steps(short)を基本として、倍の1,048,576steps(medium)、4倍の2,097,512steps(long)学習しています(但し、下記の表のとおりモデルによっては多少の増減があります)。また、T5の元論文ではbatchサイズ128でしたが今回はbatchサイズ256で学習しています。
XLについては学習の効率化のため、batchサイズ128、bfloat16による量子化、学習ステップ数524,288のみで学習を行っています。
それぞれのモデルに対応するハイパーパラメータの設定は以下の通りになります。
まとめ
日本語で学習したT5を公開いたしました。モデルサイズの違いによる比較や学習ステップ数による比較が可能になるように様々なハイパーパラメータで学習したモデルを公開しております。Huggingface hubにて公開しておりますので、Huggingface Transformerから簡単に扱うことができます。日本語における要約などの生成タスクに用いていただければと思います。
尚、この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の委託業務の結果得られたものです。