
OpenFST における N-shortest path アルゴリズムの紹介

※こちらの記事は、2020年8月7日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
こんにちは。 製品企画部リサーチャーの古谷です。
私はレトリバで音声認識に関する研究開発をしています。 今回の記事では、CTC 音声認識のデコーダで用いられる N-shortest path 探索アルゴリズムについて紹介したいと思います。
CTC 音声認識におけるデコーダ
Connectionist Temporal Classification(CTC)誤差関数 を用いた一般的な音声認識では、音響モデルとデコーダが用いられます。
音響モデルは、音声データを受け取り、各フレームでの音素確率を出力します。
デコーダは、音響モデルによって出力された音素確率列と言語モデルを組み合わせて、音声認識の結果である単語列を出力します。
デコーダは最も尤度が高い単語列を探索することが多いですが、場合によっては 2 番目に尤度が高い単語列も見つけてほしいことがあります。
例えば、カーナビの目的地を声で指定する場合に、いくつかの認識結果候補を画面に表示し、ユーザが選択する形になっていると、認識誤りによる手間が減るということが考えられます。
そこで今回は、11〜N番目に尤度が高い単語列を出力するアルゴリズムについて紹介します。
OpenFST
デコーダには重み付き有限状態トランスデューサ(WFST)が用いられることが多いです。
WFST は、有限状態オートマトンに「出力ラベル」と「遷移重み」が追加されたもので、[ラベル集合、状態集合、遷移集合、開始状態、終了状態集合、終了状態重み]の組として構成されます。
なお、初期状態は必ず 1 つであり、説明が無いかぎり 状態 0 が初期状態である ことにします。

WFST の例(終了状態重みは省略)。"x:a/3" は入力ラベルが "x" 、出力ラベルが "a" 、重みが 3 である辺を表す。この WFST に "xyyx" が入力されると受理され、出力ラベル列 "abbc" と合計重み 11 が返される。
また、デコーダの探索においては負の対数確率を使用し、確率の計算をトロピカル半環上1 で行います。そのため、最尤系列の探索が重み付き有向グラフにおける最短経路の探索と一致します。
この WFST を用いるライブラリとして OpenFST が存在します。
OpenFST には ShortestPath という機能が存在し、パラメータ nshortest を指定することで N番目に短い経路を出力させることができます。
ということで、 OpenFST の ShortestPath における N-shortest path 探索アルゴリズムを紹介します。
OpenFST における N-shortest path 探索
音声認識における WFST は入力ラベルが音素、出力ラベルが単語となりますが、音素確率と組み合わされた後の状態では入力ラベルは参照されません(重みの変更に使用されたためこれ以降の参照は不要)。
そのため、以降では辺は出力ラベルと重みだけを持つものとします。
こちらのソースコード の 327 行目にある NShortest という関数で N-shortest path 探索が行われます。
なお、この関数の処理の都合上、出力が反転する2 ため、入力である ifst(入力 WFST) があらかじめ反転されていることに注意しましょう。
例えば、以下のグラフにおける最短経路を探索したいとします。
図において、"a/3" は、出力ラベル(単語)が "a" で重みが 3 である辺を表します。 また、二重丸は終了状態の頂点を表すものとします。

このとき、辺を反転した下図のグラフが NShortest 関数の入力となります。

反転に際して頂点番号も新たに割り当てられます。反転について詳しくは OpenFST の Reverse の例をご覧ください。
N-shortest path 探索アルゴリズムでは下図のような、終了頂点を根とする木が出力されます。
(開始頂点からすべての葉への辺があるのでグラフ全体は木ではありませんが、下図の頂点 1 から頂点 7 が木を構成しています)
それぞれの葉から根へのパスが、1 つの単語列に対応します。 出力ラベル "ε" は出力が無いことを表します。

上図の場合は、単語列 "ac" が重み 7 で最尤系列、次いで単語列 "abc" と単語列 "df" が重み 9 となっている 3-shortest path を表します。
なお、終了状態の重みの扱いは本質的でないため省略しています。
では、このグラフの作り方を見ていきましょう。
ポテンシャル
まず、入力グラフについて「ポテンシャル」と呼ばれる概念を導入します3。 各頂点に対して、その頂点から終了頂点までの最短経路を、通常の Dijkstra 法などで計算します。これが頂点のポテンシャルとなります。
そして、全ての辺の重みを「元の重み ー(始点のポテンシャル ー 終点のポテンシャル)」の値に変更します。最短経路に含まれる辺の重みは 00 になり、それ以外の辺の重みは正の値になります。
この変更された重みは「その辺を使うことでどれだけ経路長が増加するか(最短と比べて損をするか)」という値を表します。
例えば、上に示した「入力グラフの例」のグラフの対して、ポテンシャルを用いて辺の重みを変更すると、下図のようになります。 各頂点の右上に書いてある赤い数がポテンシャルを表します。

このグラフにおける N-shortest path は入力グラフにおける N-shortest path と一致しますが、Dijkstra 法の都合で、この変更を入れたほうが探索が高速になります。
N-shortest path アルゴリズム
N-shortest path の探索には Dijkstra 法による最短経路探索を工夫したものが用いられています。
以下、入力グラフにはポテンシャルによる変更が適用済みとします。
まず、入力グラフの始点から任意の頂点へ移動する全てのパスについて、[行き先の頂点、そこへ至るパス]の組を考えます。
そして、その組を頂点とした新たなグラフ(以下、拡張グラフと呼びます)を考えます。
拡張グラフの頂点間には、入力グラフにおいて対応する辺を張ります。
この拡張グラフの上で、Dijkstra 法をベースとした最短経路探索を行います4 。
入力グラフにおいて有向閉路が存在する場合、拡張グラフの頂点は無数に存在するため、新たなグラフを陽に持つことはできません。
しかし、N-shortest path を得るためには "行き先の頂点" が入力グラフにおける終了状態であるような頂点が N回登場した時点で探索を終えれば良いため、必要な頂点のみを生成して探索することができます。
また、途中の頂点についても、N回より多く登場する必要は無いため、登場回数を記録しておき、N回より多くなったらその頂点を無視します。
途中の頂点にも訪問回数制限を設けることで、拡張グラフの頂点数が高々 N|V|、辺数が高々 N|E|となります(|V|,|E| はそれぞれ入力グラフの頂点数と辺数)。
具体例
具体的に N-shortest path 探索アルゴリズムの動きを見てみましょう。
例えば、下図のグラフ(再掲)が入力された場合を考えます。

このグラフにおける 3-shortest を探索する場合、拡張グラフ上での Dijkstra 法では以下のような探索が行われます。
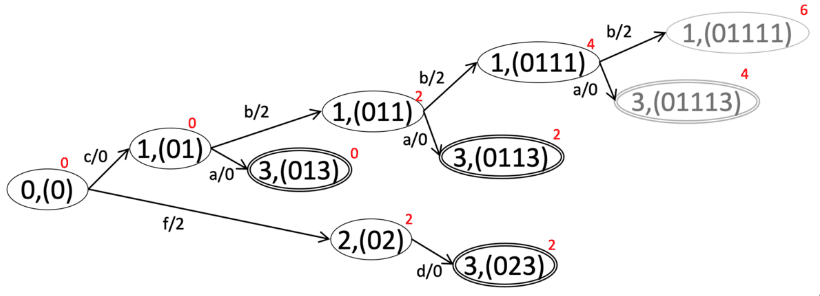
各頂点の右上の赤い数は始点からの距離を表します。
この探索において、右上の頂点 "1,(01111)" は、頂点 1 への 4 回目の訪問であるため、訪れたとしても訪問回数制限のために無視されます。
実際は、距離 22 である頂点 "3,(0113)", "3,(023)" への訪問が終わったときに終点 3 への 3 回の訪問が終了するため、探索が終了します。
このようにして構成された最短経路木から不要な頂点("1,(0111)")を取り除き、辺を逆向きにし、新たに用意した始点から各葉に辺を張ることで、出力グラフが完成します。

上の図では、辺の重みをポテンシャルによる変更の前の値に戻しています。
なお、実装においては頂点に経路を持たせるのではなく、新たに生成した頂点の番号と入力グラフにおける頂点番号との対応を記録する形となっています。
計算量
この N-shortest path 探索アルゴリズムの計算量について考えてみましょう。
まず、ポテンシャルの計算と辺の重み変更で Dijkstra 法を用いるため、この部分の時間計算量のオーダーは O(|V|log|V|+|E|)となります。
続いて、N-shortest path 探索について考えます。
ポテンシャルを用いているため、全ての頂点から終了頂点へ重み 00 の辺のみを使って移動することができます。
したがって、k本の経路を探索する過程で、重みが正の辺を使用する回数は k回となり、それ以外では重み 00 の辺を使用することになります。
また、辺の重みは全て 0以上であるため、重み 00 の辺による遷移についてはヒープを用いる必要がありません。
そのため、ヒープからの取得は N−1 回で済み、それ以外の遷移では全ての頂点と辺をチェックすることを合計 N回行うことになります5 。
ヒープの要素数は最大で N|V|となるため、ヒープからの取得の部分で O(NlogN|V|)、それ以外の遷移で O(N(|V|+|E|)) となります。
これにより、N-shortest path 探索部分の計算量が O(NlogN|V|+N|V|+N|E|)=O(N|V|+N|E|+NlogN)となります。(O(log|V|+|V|)=O(|V|)を利用しています)
以上より、ポテンシャル計算と合わせた全体の時間計算量は O(|V|log|V|+N|V|+N|E|+NlogN)となります。
空間計算量は O(N|V|)となります。
その他の N-shortest path 探索アルゴリズム
OpenFST では Dijkstra 法をベースとした手法が採用されていますが、N-shortest path 探索アルゴリズムは他にも存在します。
ループを許容しない、つまり単純パスに限定した場合のアルゴリズムとして Yen's algorithm が存在し、時間計算量は O(N|V|(|V|log|V|+|E|))です。
ループを許容する場合、つまり今回の問題設定と同じ場合では、Eppstein's algorithm が存在し、時間計算量は O(|V|log|V|+|E|+N) です。
Eppstein's algorithm は理論的な時間計算量のオーダー改善を達成していますが、グラフの大きさや Nの値によっては単純な幅優先探索を用いた場合よりも実行時間が長くなるということが報告されています6。
まとめ
今回は OpenFST における N-shortest path の探索アルゴリズムについて紹介しました。
ポテンシャルを使用し、Dijkstra 法を工夫することで N-shortest path を時間計算量 O(|V|log|V|+N|V|+N|E|+NlogN)で得られることを示しました。
ちなみに、 ICPC 2006 アジア地区横浜大会の I 問題「Enjoyable Commutation」が有向グラフから k番目に短いパスを出力する問題です。同じ頂点を複数回通るパスが禁止されているなど相違点はありますが、今回紹介した手法を応用することでも解けるようです。ただしループ禁止なので想定解法は Yen's algorithm でしょうか。Aizu Online Judge に登録されているので、興味のある方はぜひ挑戦してみてください。
私は趣味で競技プログラミングをやっているのですが、しっかりとアルゴリズムを分析して計算量解析をするのは久しぶりだったため、難しかったですが楽しかったです。
トロピカル半環における和は通常の計算における min となり、積は通常の計算における和となります↩
この関数で用いる Dijkstra 法では始点を根とする木が構成されますが、出力するグラフは後述するように終了状態を根とする木です。そのため、あらかじめグラフを反転して、終了状態から Dijkstra 法を開始するようになっています。↩
OpenFST の実装ではポテンシャルを陽に導入せず、Dijkstra 法で用いるヒープの比較関数で終了頂点までの距離を考慮しています。↩
このように、入力グラフの頂点を増やした拡張グラフで Dijkstra 法による最短経路探索をする手法は競技プログラミングにおいて頻出し、俗に「拡張 Dijkstra 法」と呼ばれることがあります。↩
辺の重みが 00 か 11 だけである場合に 01BFS と呼ばれる手法で計算量を改善できますが、それと似たような発想です↩
秋葉 拓哉, 林 孝紀, 則 のぞみ, 岩田 陽一, 𠮷田 悠一, ネットワーク上の頂点間特徴量としてのTop-k 距離とその高速なクエリ応答, 人工知能学会論文誌, 2016, 31 巻, 2 号, p. B-F71_1-12↩