
第2回生成系AI勉強会を開催いたしました!

こんにちは!株式会社レトリバ広報担当の辻です!今回は、7月26日(水)に社内で行われた第2回 生成系AI勉強会についてご紹介します。(第1回 勉強会のご紹介はこちら)
勉強会の概要
レトリバは自然言語処理に取り組んでおり、昨今は生成系AIについて質問される機会が多くなっています。そこで、今回の勉強会は、顧客対応を行う社員が、お客様から生成系AIについて質問されたときにしっかり説明できる知識を学ぶということをテーマに開催しました。
講師は、「日本語T5モデルの公開」を執筆した西鳥羽(@jnishi)が務めました。
講義内容の概要
講義の内容を決める際には、顧客対応を行う社員に事前に「お客様からのどんな質問に回答できるようになりたいか」等を尋ねるアンケートをとって、関心が高いテーマを選定しました。その結果、以下のような内容となりました。
生成系AIを実現しているキーテクノロジーはLLM
LLMの仕組み
LLMを実現するための3つの学習段階
LLMにお客様固有の知識を含める方法
順にご紹介していきます。
生成系AIを実現しているキーテクノロジーはLLM
文章を生成する処理は以前から存在していましたが、人間が入力した文章に含まれている情報を用いる形でしか、うまく生成することができませんでした。そのため、人間が応答するような自然な文章を生成することは困難でした。
しかし、最近では有名なChatGPT(https://chat.openai.com/)等のサービスが登場し、自由に入力された文章に対して、違和感のない品質の回答が返ってくる時代になりました。
これを実現しているキーテクノロジーが、LLM(大規模言語モデル)です。
言語モデルとは、文章らしさを表すモデルです。以前から研究・応用されていましたが、自然な文章を生成するのが難しいという課題がありました。しかし、言語モデルの大規模化により、自然な文章生成が可能になりました。この大規模化された言語モデルがLLMです。
LLMの仕組み
LLMは、どのようにして自然な回答文章を生成するのでしょうか?
LLMに文章が入力されると、以下の図のように、「次に続く単語」が何かを予測し、最もふさわしいものを選出してくれます。繰り返し「次に続く単語」を生成していくことで、文章を生成することができます。
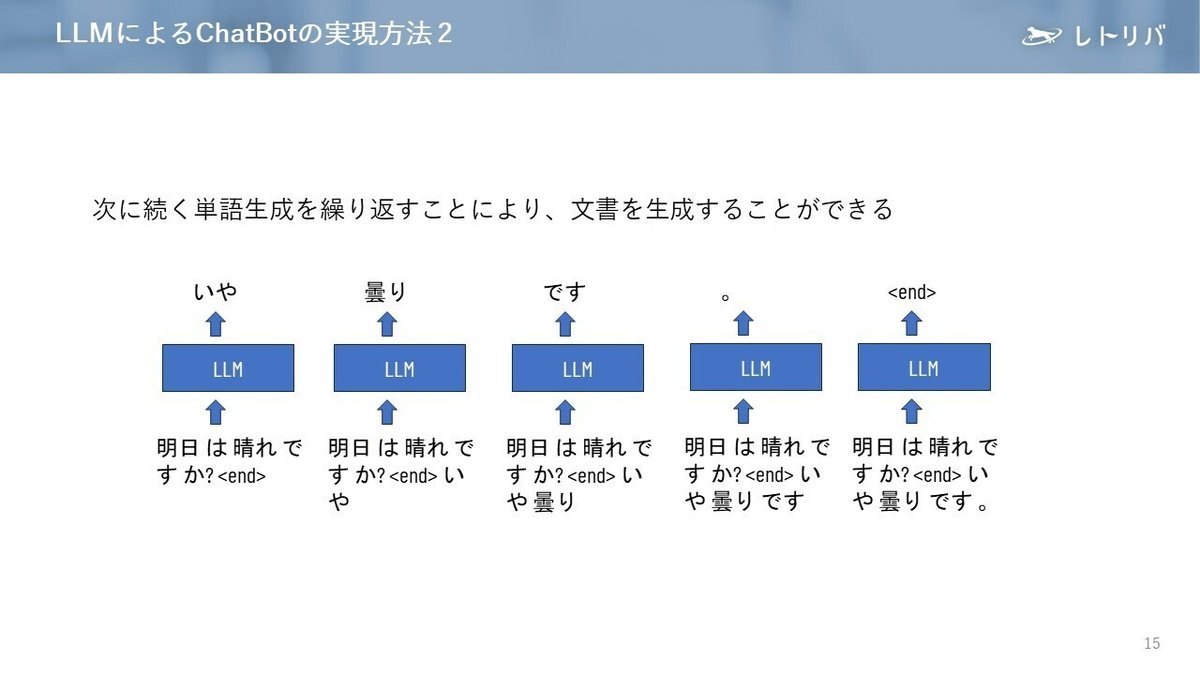
ただし、言語モデルはあくまで「文章らしさ」に基づく文章を生成するものなので、文章は成立しているけれど内容に誤りがあるような文章を生成してしまうことがあります。これをハルシネーション(Hallucination、幻覚)といいます。
このハルシネーションは、入力された文章を受け付けて回答文章を生成するまでの処理の流れ(対話フロー)に手を加えることで軽減できます。
具体的には、下図のように入力文章を受け付けた後で検索エンジンに正しい情報を問い合わせて、入力文章に適切な情報を追加してLLMに渡します。こうすることで、ハルシネーションをある程度防ぐことができます。

LLMを実現するための3つの学習段階
次に、LLMをどのように実現するかについての話題です。一般的に、モデルを作るためには学習が必要です。LLMの学習は次の三段階で行います。
事前学習
文章中の単語の順に単語が出てくるように学習を行います。この学習を行うには、1TB~十数TB分程度の分量が必要なためWeb 上の文書をメインで用います。
Supervised Fine Tuning(SFT)
人手で記述した理想的な対話例を用いて学習を行います。この学習では、学習データが実際にユーザーが入力しそうなクエリに近い方が、求めている結果を得やすくなります。
Reinforcement Learning with Human Feedback(RLHF)
対話の回答に対して評価を行ったデータを用いて学習を行います。ChatGPTは、Reward Model(※)用に33,000文、LLM用に33,000文のデータを使用しています。
※会話文を入力するとどの程度会話らしいかの数値を算出するモデル
LLMにお客様固有の知識を含める方法
LLMの3つの学習段階の話は、LLMにどのようにお客様固有の知識を含めるか話題につながっていきます。
生成系AIを業務に活用するようなシーンでは、その業務分野や会社固有の知識が織り込まれた回答文章が返ってくることが期待されます。これを実現するためには、一般的な言語モデルとは別の固有知識をLLMに反映する必要があります。この反映を、学習のどの段階で行うかについて、下図で示すように、2つの作戦が考えられます。

パターン1
事前学習の段階で、事前学習に用いるテキストに独自のデータを加える
パターン2
Supervised Fine Tuningの段階で、SFT及びRLHFに用いるデータを独自で用意する。数万会話例の作成及びアノテーションをつける
パターン1はパターン2に比べて精度が高い利点がありますが、「数TBのテキストを用意する」ことが現実的に非常に困難なことがネックです。その点、パターン2はパターン1よりも精度が劣りますが、現実的なコスト(※)で正解を作成できます。
※とはいえ、人手で正解を作るのに数千万円規模のコストがかかると予想されます
また、LLMにお客様固有のデータを含めるのであれば、LLM自体のセキュリティにも気を配る必要があります。LLMを物理的にどこに置くのか、どのような利用制限をかけるのかなどをあわせて検討することになります。
勉強会の反響
この勉強会は、私がとりまとめを担当していたのですが、「顧客対応を行う社員の方以外でも興味があれば参加してほしい」と募集したところ、たくさんの社員の方が参加してくださり、嬉しい限りでした!
また、アンケートでも、
「自身で調べて曖昧だった認識がクリアになる素晴らしい勉強会なので、今後も参加して理解を深めていきたいです。」
「LLMの学習方法など非常に参考になった。」
「半期に1回くらい、今のトレンド的な勉強会があると嬉しいです。」
などの嬉しい声をいただきました!
これからも社員の皆さんの力になれるようなコンテンツを考えていきたいと思います。
今後も、社内の様子やイベントの様子などをレポートしていきますので、ぜひご覧ください!
採用情報
レトリバでは、一緒に働く仲間を募集しています。
詳細は下のリンクから見られますので、ぜひご覧ください!
▼採用職種一覧
株式会社レトリバ の全ての求人一覧 (herp.careers)