機械学習3〜KNN〜

教師あり学習
ある入力に対して特定の出力を予測したい場合で、 入力出力のペアの例が入手できる際に用いられる。 入力出力のペアが訓練セットとなり、それから機械学習モデルを構築する。目的は、新しい見たことのないデータに対して正確な予測を行うことである。
“教師あり機械学習問題は2つに大別することができる。
クラス分類(classification)と回帰(regression)だ。
クラス分類問題と回帰問題を区別するには、出力に何らかの連続性があるかを考えてみればよい。出力に連続性があるなら回帰問題である。”
#過学習 :
“持っている情報の量に比べて過度に複雑なモデルを作ってしまうことを過剰適合(overfitting)という”
y=ax+by+Cz....など多いとき。モデルは簡単な方が良い
# モデルが複雑になることを許せば許すほど、訓練データに対する予測精度は向上する。
#しかし 、モデルが複雑になりすぎると、訓練セットの個々のデータポイントに重きを置きすぎるようになり、新しいデータに対してうまく汎化できなくなる。”
下記のスイートスポットを狙う。

#KNN (K Nearest Neighbor)。K近傍法
# 学習データをベクトル空間上にプロットしておき、未知のデータが得られたら、
#そこから距離が近い順に任意のK個を取得し 、多数決でデータが属するクラスを推定する。
# 例えば下図の場合、クラス判別の流れは以下となる。
# 1 既知のデータ(学習データ)を黄色と紫の丸としてプロットしておく。
# 2 Kの数を決めておく。K=3とか。
# 3 未知のデータとして赤い星が得られたら、近い点から3つ取得する。
# 4 その3つのクラスの多数決で、属するクラスを推定。
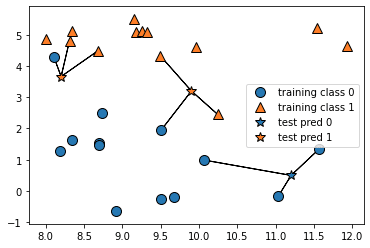
#テストデータと訓練データ作成
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
#k−最近傍法召喚(n=3)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
#分類器訓練させる
clf.fit(X_train, y_train)
#実際に予測させる
print("Test set predictions: {}".format(clf.predict(X_test)))
Test set predictions: [1 0 1 0 1 0 0] テストセットに対する予測
#評価
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test)))
Test set accuracy: 0.86 テストセットに対する精度
#分類機の解析
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend(loc=3)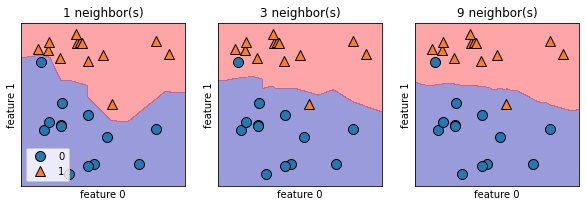
# #“なめらかな境界は、単純なモデルに対応する。つまり、最近傍点が少ない場合は複雑度の高いモデルに対応し、最近傍点が多い場合は複雑度の低いモデルに対応する”
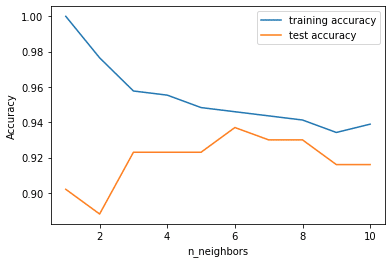
別データで行う
実世界のcancerデータセットを用いる。まずデータセットを訓練セットとテストセットに分割し、訓練セットに対する性能とテストセットに対する性能を近傍点の数に対して評価する。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
#stratifyはstratify に、割合を揃えたい列を指定してあげると、訓練データとテストデータ
で同じ割合になるように分けてくれます。
training_accuracy = []
test_accuracy = []
# n_neighborsを1から10まで試す
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# モデルを構築
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# 訓練セット精度を記録
training_accuracy.append(clf.score(X_train, y_train))
# 汎化精度を記録
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()n=6が一番予測できている事がわかる。