
【やってみた】AITuberKit + Style-Bert-VITS2

AITuberKit 使って判った。
TTSの応答速度って重要よな。
って事でTTSをローカルで持ちたい
とは言え、我が家の余剰GPUはノート搭載の「GTX1050 Ti 4GB」のみ
悩んでもしょうがないので、とりまブッこんでみる!
Style-Bert-VITS2
最近話題のやつ。日本語表現がエグいと。
Style-Bert-VITS2 初回インストール
batファイルでインストール!簡単。
私は「Install-Style-Bert-VITS2.bat」使いました。
その前に
Python環境ゴリゴリ使うので、conda で環境つくっとこ
まず、minicondaのセットアップ
PowerShell用の設定
conda init powershellCreate
conda create --name Vits2Env python=3.10.6Activate
conda activate Vits2Envインストール
Install-Style-Bert-VITS2.bat以下のエディターが立ち上がったらインストール成功
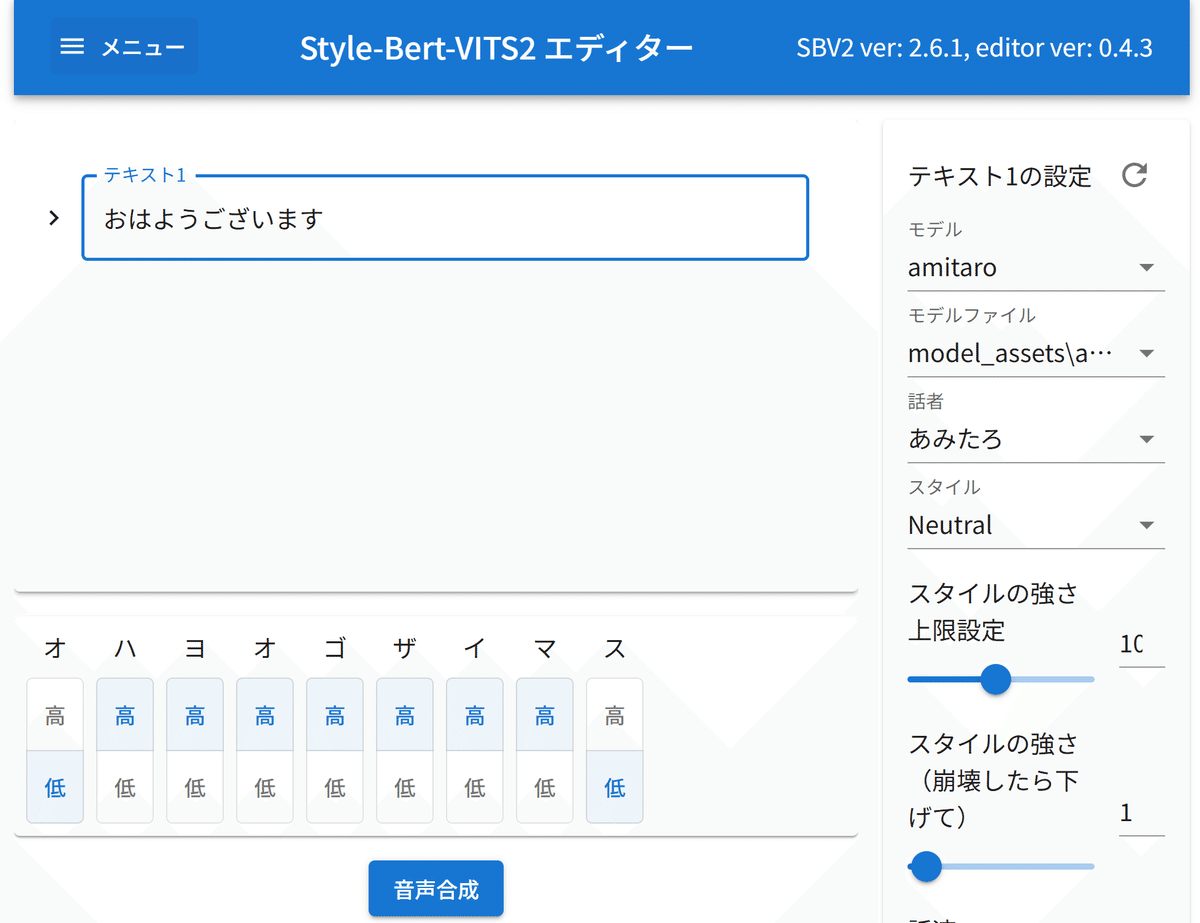
初回はロード時間がかかるのか少し間がありましたが、2回目からは0.5秒程度で応答もらえました。
Style-Bert-VITS2 本番インストール
で、ここからが本番インストール
pip install -r requirements.txt足りないライブラリの追加とCUDAの調整
自分のGPUと利用可能なCUDAを組み合わせてね
pip install gputil psutil torch uvicorn fastapi scipy pyyaml loguru transformers numba
pip install numpy==1.23.5
pip uninstall pyworld
pip install pyworld --no-cache-dir
pip uninstall torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121私の環境で必要だった修正
私の環境では FastAPI を以下の形で立ち上げる必要があった
(server_fastapi.pyに追記)
from contextlib import asynccontextmanager
# FastAPIアプリケーション作成
@asynccontextmanager
async def lifespan(app: FastAPI):
logger.debug("Debug: lifespan start")
if torch.cuda.is_available():
current_device = torch.cuda.current_device()
device_name = torch.cuda.get_device_name(current_device)
logger.info(f"Using device: cuda:0")
logger.info(f"Device Name: {device_name}")
else:
logger.info("Using device: CPU")
logger.info("Starting model loading during startup...")
model_holder = TTSModelHolder(Path("model_assets"), device)
load_models(model_holder)
logger.info("Models successfully loaded during startup.")
yield
app = FastAPI(lifespan=lifespan)
GPUを自動で選択してくれない場合は、import os のタイミングで以下の設定("0"はデバイス番号)を行う。
import os
# GPU設定
os.environ["CUDA_VISIBLE_DEVICES"] = "0"さらに
from contextlib import asynccontextmanager より後
@asynccontextmanager より前
のタイミングで明示的に「device」を設定する
# GPUデバイスの初期化
device = "cuda:0"
if not torch.cuda.is_available():
logger.error("CUDA is not available. Falling back to CPU.")
device = "cpu"
else:
device = "cuda:0"
logger.info(f"CUDA is available. Using device: {torch.cuda.get_device_name(0)}")日本語、英語、中国語のBERTモデルとトークナイザーが存在するが、私は基本的に日本語のみ生成させたいので、最低限のモデルのみロードしています。
# 事前に BERT モデル/トークナイザーをロードしておく
## ここでロードしなくても必要になった際に自動ロードされるが、時間がかかるため事前にロードしておいた方が体験が良い
bert_models.load_model(Languages.JP)
bert_models.load_tokenizer(Languages.JP)
# bert_models.load_model(Languages.EN)
# bert_models.load_tokenizer(Languages.EN)
# bert_models.load_model(Languages.ZH)
# bert_models.load_tokenizer(Languages.ZH)音声モデルも利用するもの1つを明示的にロード
loaded_models: list[TTSModel] = []
def load_models(model_holder: TTSModelHolder):
global loaded_models
loaded_models = []
# 明示的に1モデルだけ読み込む
model = TTSModel(
model_path=model_holder.root_dir / "amitaro/amitaro.safetensors",
config_path=model_holder.root_dir / "amitaro/config.json",
style_vec_path=model_holder.root_dir / "amitaro/style_vectors.npy",
device=model_holder.device,
)
loaded_models.append(model)ライブラリが揃ったら音声合成サーバの起動
python.exe .\server_fastapi.pyエラーが出たら、起動するまでAI君と悩む
一度、「FFMPEGが必要だったり不要だったり」「モデルはJP-ExtraだったりJPだったり」で、悩んだが、再度クリーンな状態から構築しなおしたら、うまく動いたので、ワケわかんなくなったら、今までの知識を持って、クリーンインストールから、が早いかもしれない
以下が修正ファイルです
Gitに上げた方がいいのかな?
AITuberKit 起動
まだインストールしてない人いるかな?
インストール方法はコチラ
では起動しましょう
npm run devブラウザ http://localhost:3000/ にアクセス
音声設定で、「Style-Bert-VITS2」を設定

以下のUIでAITuberと会話できるよ

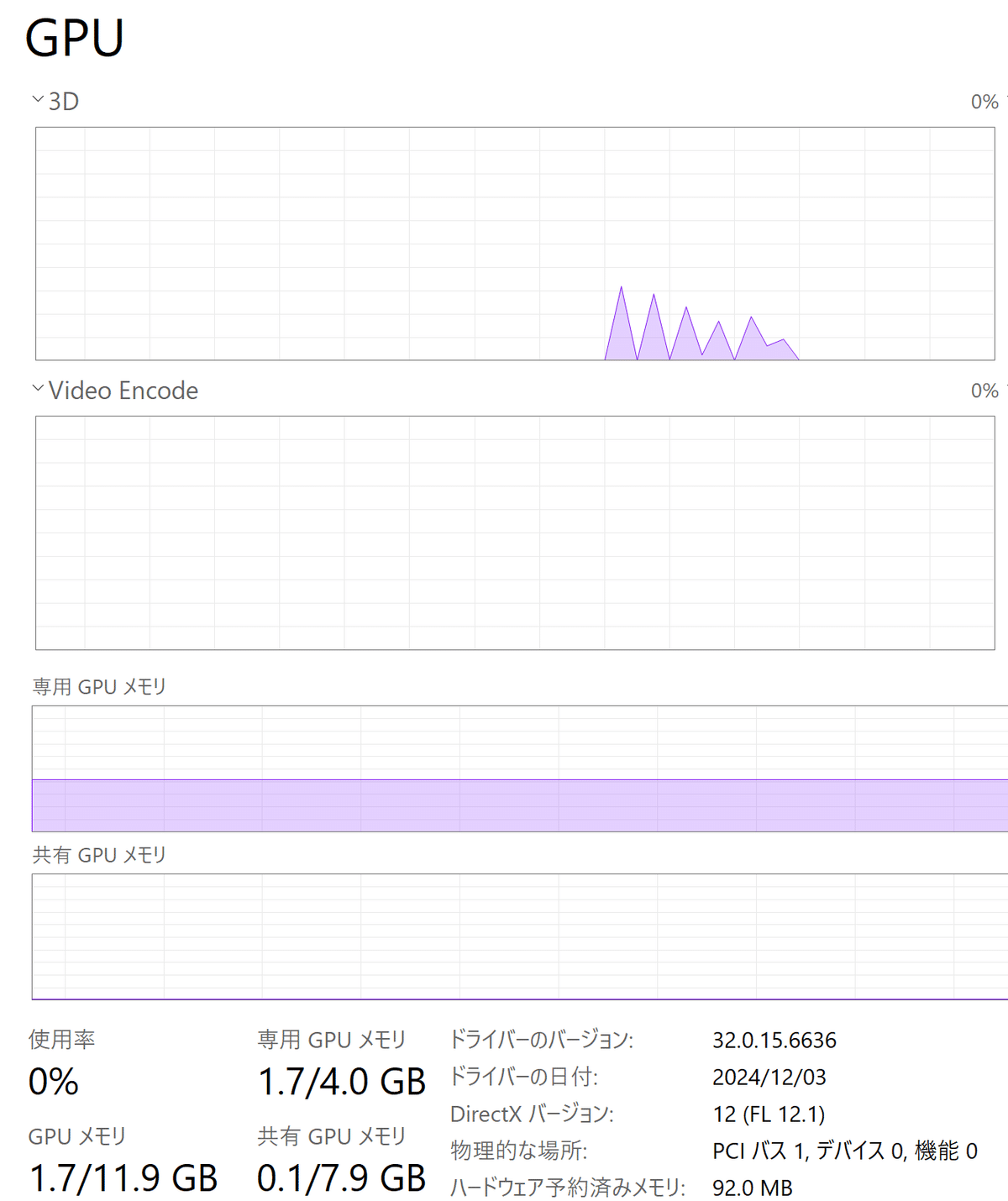
GTX1080Tiを1.7GB消費して音声生成成功
APIの使い方
APIエンドポイント: TTSリクエストはhttp://127.0.0.1:5000/voiceエンドポイントに対して行います。
リクエストパラメータ: 以下のパラメータを含めてGETリクエストを送信します。
text: 合成したいテキスト
speaker_id: 使用する話者のID(デフォルトは0)
model_name: 使用するモデルの名前
length: 音声の長さの調整(1.0が標準)
sdp_ratio, noise, noisew: 音声の品質やスタイルに関するパラメータ
auto_split: 長いテキストを自動で分割するかどうか(trueまたはfalse)
split_interval: 自動分割時の間隔
language: 言語コード(例: JP)
style: 音声のスタイル(例: Neutral)
style_weight: スタイルの強度
サンプルコード: 以下は、Pythonでのリクエスト例です。
import requests
def synthesize_speech(text):
url = "http://127.0.0.1:5000/voice"
params = {
"text": text,
"speaker_id": 0,
"model_name": "your_model_name",
"length": 1.0,
"sdp_ratio": 0.2,
"noise": 0.6,
"noisew": 0.8,
"auto_split": True,
"split_interval": 1,
"language": "JP",
"style": "Neutral",
"style_weight": 5
}
headers = {"accept": "audio/wav"}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
with open("output.wav", "wb") as f:
f.write(response.content)
print("音声ファイル 'output.wav' が生成されました。")
else:
print(f"エラー: {response.status_code}")
# 使用例
synthesize_speech("こんにちは、世界!")このコードを実行すると、指定したテキストの音声がoutput.wavとして保存されます。
注意事項
モデルの準備: 使用するモデルファイルをmodel_assetsディレクトリに配置し、model_nameで指定してください。
文字数制限の変更: デフォルトでは、1回のリクエストで処理できるテキストの長さが制限されています。必要に応じて、config.yml内のserver: limitの値を調整してください。
エラーハンドリング: リクエストが失敗した場合、ステータスコードを確認し、適切なエラーハンドリングを実装してください。
ドキュメントはサーバ起動後に以下のポイントにアクセスすることで確認
http://127.0.0.1:5000/docs
最後に
次のステップに進むための大切な情報
以下のページは音声モデルのマージ、2音声マージなどの説明がある
超有益