
stable Diffusion WebUI拡張機能 個人的セレクション

更新履歴
24/08/04
「Segment Anything V2」「PaintsUNDO」を追加
24/06/02
「sdweb-easy-prompt-selector」と「sdweb-easy-prompt-text-bigger」「PBRemTools」「Omost」「starline」「aesthetic-predictor-v2-5」を追加
コントロールネット(Controlnet)
コントロールネットモデル
SDXL用フルサイズ
SDXL用LoRAタイプ
SDXL用LLLiteタイプ
LLliteの比較
Tabs-extention
コントロールネットなどが並ぶWebUI標準のアコーディオンタブは縦に長くなり面倒という欠点があるためこれをタブ形式にまとめてくれる機能
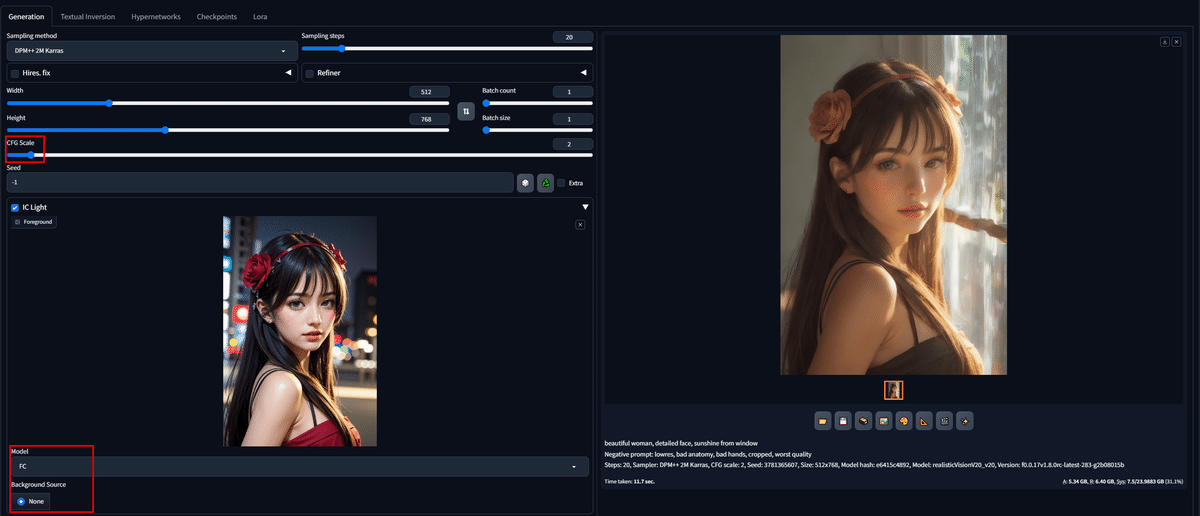
IC-Light
画像をもとに背景をいったん切り抜きライティングの方向性などを加味して光の当たる方向と背景と人物を馴染ませる機能
layerdiffusion
透過背景の画像をWebUI上で生成できる拡張機能。
モデル(動作はこれがなくてもする模様)
画像を加工する拡張機能
コントラストやブラーなどをペイントソフトで編集しなくても出せるようにする機能
画像をメタデータで分類
Outputフォルダーに保存されている画像のメタデータを読み込んで日付やモデル別に分類して表示することが可能な拡張機能
regional-prompter
垂直/平行方向に分割された領域ごとに異なるプロンプトを指定できるようになる拡張機能
Regional Prompter + ControlNet
tagcomplete
入力するプロンプトの予測変換を表示する。多くのモデルはdanbooruタグという特殊な形式で学習されているため自然な文章では適切ではない可能性がある。英語のスペルを正確に覚えていなくても最初の数文字を入れるだけで目的のプロンプトを入力できる
sdweb-easy-prompt-selector
様々なプロンプトの一覧を出してボタンでプロンプトを入力できるようになる。
sdweb-easy-prompt-text-bigger
WebUI上の文字を大きくするだけの拡張機能
使い方
history-slider
プロンプトを一文字ずつ保存し巻き戻せる。プロンプトを書いたり消したりしていると特定のところまで巻き戻したいと思うことがあるのでそのような時に便利
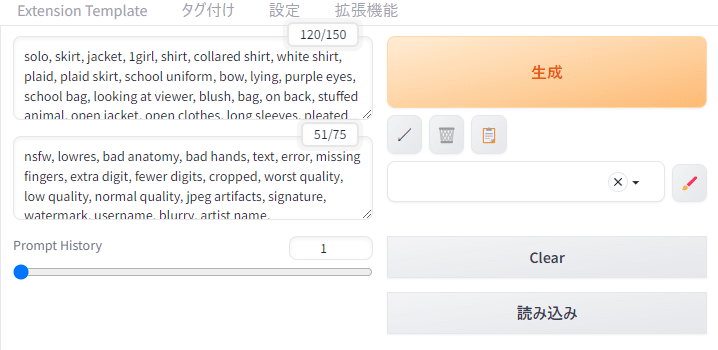
ar-plus
生成する画像のサイズをボタンで変えられるようにできる。よく使う画像の縦横比を登録しておけばスライダーを動かさずに設定できる
confirmation-dialogue
WebUIを閉じるときに確認ダイアログが出て設定がリセットされないようにする機能

Config-Presets
WebUIを起動する度に設定を初期値から変更するのは面倒です。よく使う設定を登録しておくことで次回起動時にすぐ呼び出すことができます。
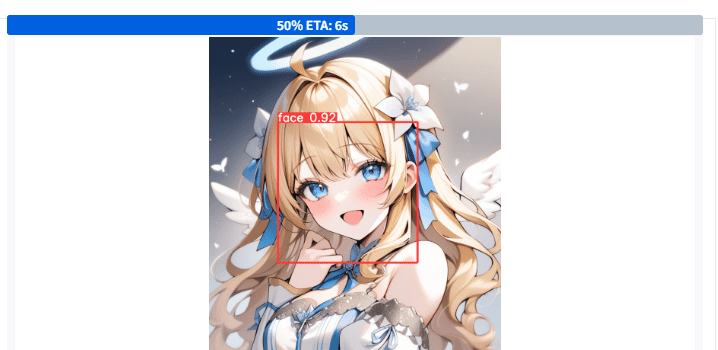
ADetailer
生成した画像の顔の部分などを自動で検出しよりきれいにする。また、画像を生成してから表情を変えたり眼鏡をかけさせるなど表情差分を作ることもできる
lama_cleaner
生成した画像から不要なものを消すのに使いえる。不必要な小物やロゴマーク、テキスト等を消去できる

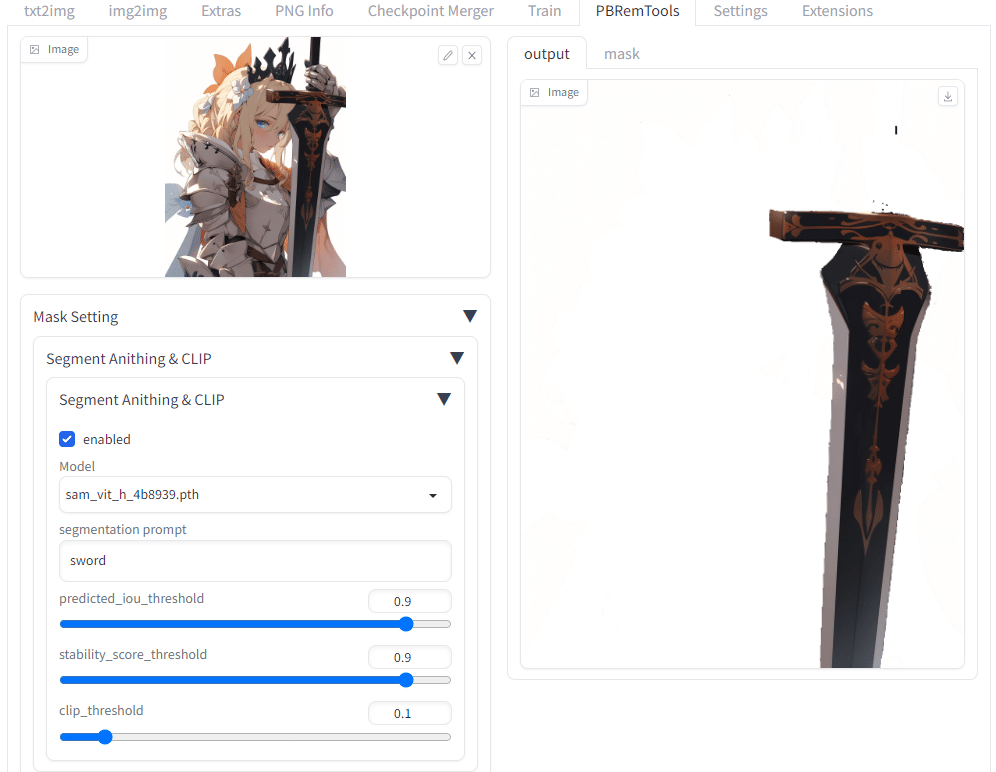
PBRemTools
指定した部分または背景などを切り抜いてくれるツール。「Segment Anything Model」を手動でインストールし「extensions/PBRemTools/models」に配置しなければならない。
また、切り抜く個所はプロンプトで指定する。
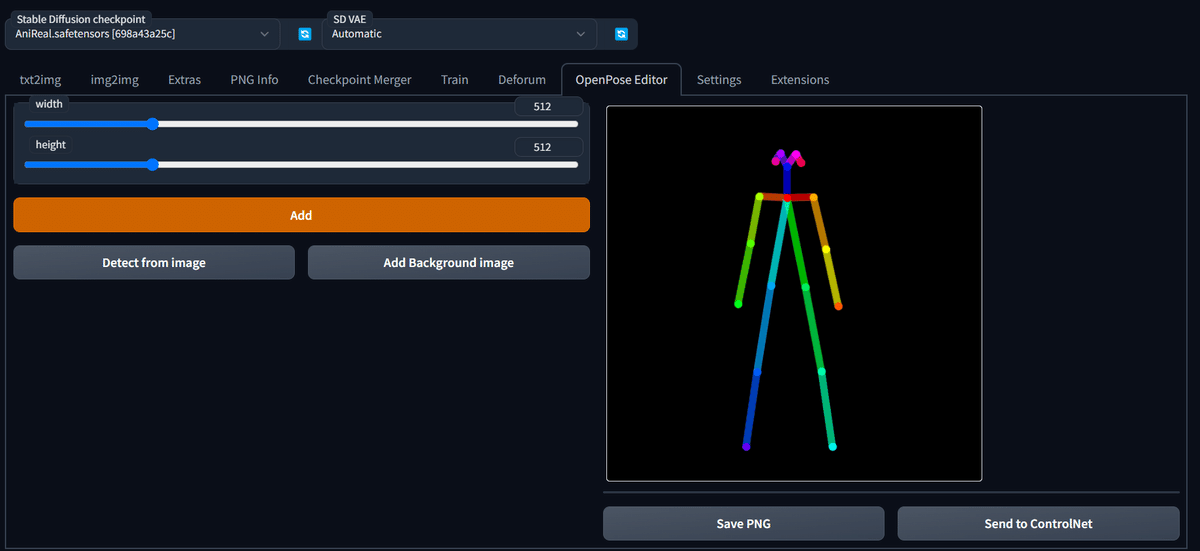
openpose-editor
コントロールネットのopenposeで使えるカラフルな棒人間を編集できる。コントロールネットの本体でも編集はできますが、一から手軽にポーズ指定ができる
dynamic-prompts
プロンプトに{ short hair | long hair }と記述すると1/2の確率で長い髪か短い髪が選ばれる。ランダムにプロンプトを選び、変化を持たせたいときに使用できる
webui-lora-block-weight
LoRAを階層と呼ばれるブロックから適用量を指定して使用する拡張機能。プリセットで使用できる。
supermerger
モデルを合成する機能の拡張機能
stable-diffusion-webui-wd14-tagger
画像からタグを抽出できるツール。元の作者の制作したものは使えなくなってしまったためフォーク版が公開されている。
captioning_helper
LoRAを学習する際にタグを一括で編集できる
depth hand refiner
コントロールネットで手を修正する専用機能
TensorRT
専用のエンジンを作成し、WebUIでの生成を高速化する方法。
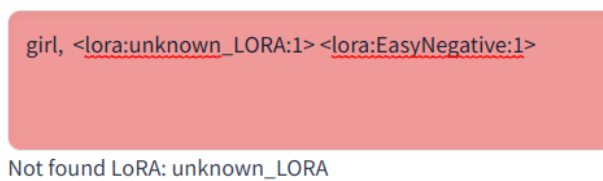
enable-checker
存在しないLoRAを指定したら警告する機能
ComfyUI
EasyUse