
Pythonで競馬予測モデルの作成1(有馬記念ですね)

こんにちは。
12月22日(日曜日)は中山競馬場で有馬記念の競馬レースが開催されましたね。武豊騎手がご病気でドゥデュースが欠場ということになってしまいました。残念でした。ただ、データ分析した感じでは、ドゥデュースは勝ちづらいかな、ルメール騎手のアーバンシックが強いかな、と思っていましたが。。。
結果は戸崎圭騎手のレガレイラが1着でしたね。これは予想していませんでした。競馬って面白いなあ。
ところで、競馬AIというものを作るのが一部の人たちの間で流行っていますね。流行っているというか、作ることができる人もいる、というくらいだと思います。結構データ分析のスキルがいりますし、しつこく長期間にわたって分析して本当に勝てるかテストする必要もあります。
自己紹介を少しします。私は外資系コンサルティングファーム、シンクタンク、フリーランスで合計25年ほどデータ解析の仕事をしてきました。現在はほぼ引退しております。
競馬データが買えるということが分かり、久しぶりに面白いことができるかな、と思って取り組もうかと思った次第です。おそらく取り組めば、競馬の予測モデルはたぶんそれなりに作ることはできると思います。それが損益プラスになる価値のある予測モデルになるかどうかは、競馬というものについて、そもそもデータに意味があるか、ということに依存するのですが、ネットを検索すると、100%を超える回収率が得られる?という噂も。。。
噂ベースで踊らされてもいけないのですが、私はデータ分析が大好きなので、まず競馬データが購入できる、と言うことを調べて分かって、燃えてきました。それで、統計モデルを作って馬券を少額買ってみて、損益がプラスになる投資モデルがつくれないか?ということを夢に思って、取り組んでみることにしました。
少しずつ改善を繰り返していく過程をお見せしようかと思っています。
AI、という言葉はほとんど意味はありません。多項式などを使った数理モデルです。予測モデルと投資パターンのモデルを作成できるかな、と思ったりしています。
競馬データはWebからスクレイピングする人もいるようですね。私はだいたい購入してしまうほうが多いです。
JRA-VANのアプリケーションの使用料金2000円くらいをカードで支払い、target frontier JVというソフトウェアをインストールしました。そこからCSVでデータを抽出できるということが分かりました。
まずはレースのデータをCSVで取得しました。30年分ほどデータがあるようです。それをPythonで読み込んで、まずはプログラムの骨子を作るために、予測モデルをあまりこだわらずに作って、損益を簡単に計算してみることにしました。プログラムとデータの形ができると、パイプラインというのでしょうか、作業がすごくしやすくなります。それを目指しました。
今回はPythonで、Scikit-Learnライブラリをつかって、ロジスティック回帰モデルで着順が1着になる場合のみをターゲットとして予測するモデルをファーストカット、セカンドカットとして2つ作りました。目的変数を、着順が1着の馬・レースであれば1、それ以外であれば0にセットしました。
1993年から2019年までを学習データとし、2020年から2024年までをテストデータとして計算しました。
ファーストカットで作ったモデルの勝率は単勝で35%くらい。。。地方も中央も、朝から晩まで全レース勝負に行った場合です。
これは
・人気
・ログ_オッズ
・馬体重
・馬番
・馬年齢
・体重差
の説明変数をつかって、馬券を買ったときの勝率です。あくまでファーストカットです。
2000年1月から2024年12月15日までの全レースで単勝の馬券を100円購入したとしました。次のような結果になりました。

まずは統計モデルと評価関数、損益の計算ができただけでもかなりの前進です。プログラムのひな型ができたことになります。
これに、データ項目として説明変数を加えていく関数を付け加えたりして改良してきます。
セカンドカットのモデルを作るために、説明変数の案として以下のものを作成しました。
・騎手の勝ち数
・父馬の勝ち数
・母馬の勝ち数
・母馬の父親馬の勝ち数
騎手の勝ち数は、2種類つくりました。単に1着だけを年ごとにカウントするもの、そして、3着までを、1着10点-2着5点-3着2点として点数をサマリするものをつくりました。3着まで点数で評価するのは、複勝の評価を想定しています。
母馬の父馬の変数は作ってみたのですが、目的変数との関係性をグラフで見たところあまり良くなく、統計モデルに投入してもあまり有効ではないと判断しました。
結果は、勝率が下がってしまいました。追加変数はうまくくわえないといけませんね。レースの、その年までの勝ち数としてしまったかな?こういう説明変数をリークと言います。せめて、レースの前年までの勝ち数とか、レース直前までの勝ち数、としなければいけなかったところですね。そういう説明変数にするためには、じっくりと追加変数を作る関数の仕様を考える必要があります。もう少し時間をかけようかと思います。
ファーストカットとセカンドカットでは、データの母集団に若干の差があります。一度データをダウンロードしてみたから2,024年の直近のレースの情報が追加されたのだと思います。
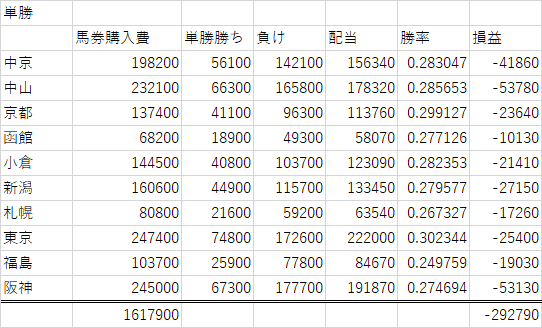
セカンドカットのモデルで、単勝の投資損益を見ると、ファーストカットよりほんのすこし改善していますね。これは、配当のよいレースが予想しやすくなった、ということなのでしょう。
また、単勝にこだわらず、馬券の買い方はいろいろあるので、そういう戦略を考えるのも楽しいですね。馬券の払い戻しの計算をする関数が必要です。また、何らかの評価関数を作らなければいけないかもしれません。
こんな感じで、少しずつ調整して作っていきたいと思います!
ロジスティック回帰は、0-1の2値を予測する基本的な統計モデルとして使えるすごくありがたい線形モデルです。これを知らずにいきなり勾配ブースティングツリーを使ってしまう人もいるかもしれませんが、あまりよろしくありません。データに構造がある場合には、ロジスティック回帰モデルを使うことを想定して説明変数のグラフを書くことや、相関係数を計算すること、などを含めてフィッティングを一旦目指してみるのが良いかとおもいます。ロジスティック回帰モデルでは各変数の係数が作成されるので、それを読解する知識もとても重要です。
説明変数の構造が難しい場合や、交互作用がありそうな場合など、それ以上にモデルのトライが必要な場合には単純なデシジョンツリーや、勾配ブースティングツリーを使うのが良いかと思います。
勾配ブースティングツリーについては、世の中では、LightGBMを使っている人が多いようですね。XGBoostというライブラリもあります。どちらか使えれば、それで問題ないとおもいます。これらも将来的には試してみようと思っています。
以下にここまで作業したプログラムを有料で掲載します。
・JRA-Van target frontier JVから取得した競馬データの読込み
・Scikit-Learnライブラリのロジスティック回帰モデルの使い方
・出来上がったロジスティック回帰モデルの評価方法
・全レースについて単勝馬券を100円だけ買った場合の損益の計算方法
がわかるプログラムとなっています。
プログラムは見てしまえばそれでおしまいなので、返金対応はしないことにいたしました。よろしくお願い申し上げます。
また、Pythonの開発環境は、私はPycharmをつかっています。Pycharmは難しい設定が必要なく、動きがシンプルで、MS Visual Studio Codeよりも分かりやすい気がします。お使いになる場合には、検索エンジンでPycharmと検索し、インストールパッケージをダウンロードしてインストールしてください。Pycharmは、私はずっと無料版を使っています。それで問題ないです。
でも一応私もMS Visual Studio Codeもインストールしてあります(笑)。
Pythonのパッケージは、Anacondaが良いと思います。Anacondaは一通り動くライブラリが同梱されているので、使いやすいです。
将来的なブログでは、変数加工や、グラフの書き方、説明変数の予測モデルへの寄与の分析のしかた、などをお伝えしていければと思っています。
データ分析って面白いですね!
お読みいただいてありがとうございました。
これからデータサイエンティストになりたい!と言う方は、データがあればいろいろ実験できるので、競馬データを購入して頑張ってみる良いチャンスだと思います。そういう方を応援しています!
わからないことがあったらコメント欄にコメントをいただければ、お返事やブログ記事にて解答したいと思います。出来る範囲で、と言うことになってしまうかもしれませんが、よろしくお願いします。
有料部分にお進みになる場合は、よろしくお願いいたします。
ここから先は
¥ 1,000
この記事が気に入ったらチップで応援してみませんか?