
VOICEVOX 中間APIサーバー作った ~自作アプリから簡単にVOICEVOXと連携~

こんにちはRcatです。
前回、Linux版VOICEVOXをSSHからシェルだけで使用する方法を紹介しました。
今回はその延長で、LinuxにVOICEVOX音声合成サーバーを建てようと思います。
これによりより簡単にAPIにアクセスして様々な自作アプリなどから利用が可能になります。
はじめに
利用規約
情報や作品の活用時は事前に利用規約をご確認ください。
コメントについて
利用規約のガイドラインを確認の上コメントしてください
概要
経緯
少し前にこちらの記事で全自動地声吹き替えツールを作りました。
ここで少し説明していますが、VOICEVOX本体のAPIは送信する内容が複雑で、利用するには専用のプログラムを組む必要があります。
当時はPythonモジュールを作りましたので、Python空であればそれをインポートすればよいですが、他の言語の場合や自作モジュールをいろんなところにコピーするのは管理が煩雑になりかねません。
だったら…簡単に使えるWEB API作ればいいんです。
中間サーバーってどういうこと?
上で少し話していますが、要はもともとWebのAPIがあるが、使うのが難しいので、代わりにもっと簡単に使えるAPIを作るという感じです。
どれくらい難しいかというとこんな感じです。

最初は誰に読ませるかと読み上げるテキストだけ渡せばいいんですが、2つ目はすごい量のパラメーターを要求されます。
まぁ、このパラメーターはほぼ全て1つ目のAPIから返される内容なのですが、結局、このAPI間を橋渡しするプログラムが必要になってくるんですよね。
というわけで、今回考えたシステムを図にしたものがこちら
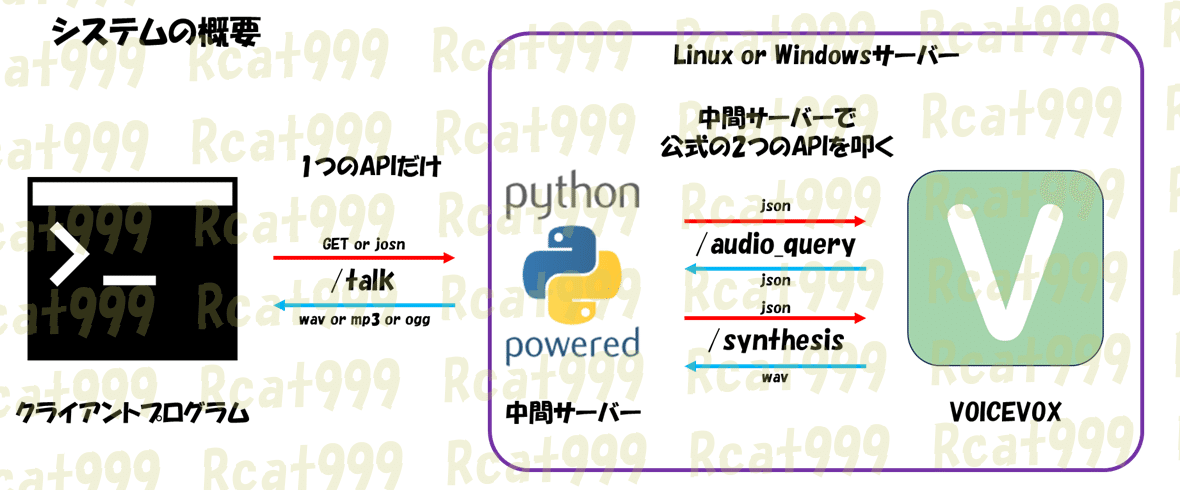
クライアントからは中間サーバーの1つのAPIだけを叩きます。
すると、中間サーバーは公式の2つのAPIを叩き音声を生成します。
また、中間サーバーはGETのパラメーターによるリクエストも受け付けており、より利用が簡単になっています。
さらにVOICEVOXの出力はwavですが、中間サーバーの中でFFMPEGを利用してMP3やoggなどに変換することで、データサイズを抑えて返すこともできます。
機能及び使い方
使い道
基本的に他のプログラムから呼び出すために使い、直接Webサーバーに接続するような使い道は想定していません。
例えばDifyを使う例だと、AIを使って何らかのテキストを生成したものを、ワークフロー内のhttpリクエストで読み上げなんてことも想定できますね。
音声データを取り扱えるのかまでは確認していませんが…。
こうしたある程度は自分で手を入れられるけれども、深くまで手を入れられないものに関してはこういったWebAPIを用意しておくのが非常に便利です。
他にもスマホのアプリを作って読み上げ、機能を搭載したいなと思った時に、ネットワーク経由で読み上げを行えるようにするなどといった使い道も想定されます。
Pythonのインストール
本作はPythonでできています。
そのため、まずはPythonのインストールが必要です。
インストール方法については以下の記事で解説していますので、参考にしてください。
また、FFMPEGを使う機能を利用する場合はFFMPEGのインストールとPATHの設定が必要です。
機能
本サーバーには次の機能があります
VOICEVOXを使った読み上げ機能
任意のテキストを読み上げ
入力したテキストを読み上げられます。キャラクターの任意選択
IDを指定してキャラクターを選ぶことができます。読み上げ速度調整
次のどちらが片方から読み上げ速度を選択できます。スピード設定機能
長さ設定機能
読み上げにかかる時間を秒で指定できます。厳密にはその秒数になるようにスピードを調整します。完全一致には絶対にならないので、ある程度の濃さはあります。
圧縮ファイル形式への変換(FFMPEGが必要)
MP3
OGG
GETまたはPOSTにて実行可能
簡単なGETで実行するか、長いテキストの場合はPOSTが利用可能です
VOICEVOXキャラクターID検索機能
公式APIのID情報を見やすく表示する機能です。VOICEVOX起動機能
サーバーが立ち上がっているパソコンで起動スクリプトを実行する機能
プログラム起動時に自動的に実行されるほか、特定のURLを叩くことでも実行できる読み上げのテスト実行
cgiのテスト利用ができます
トップページ
本サーバーにアクセスすると以下のような画面が現れます。
この画面ではcgiの説明とキャラクターID検索機能が利用できます。
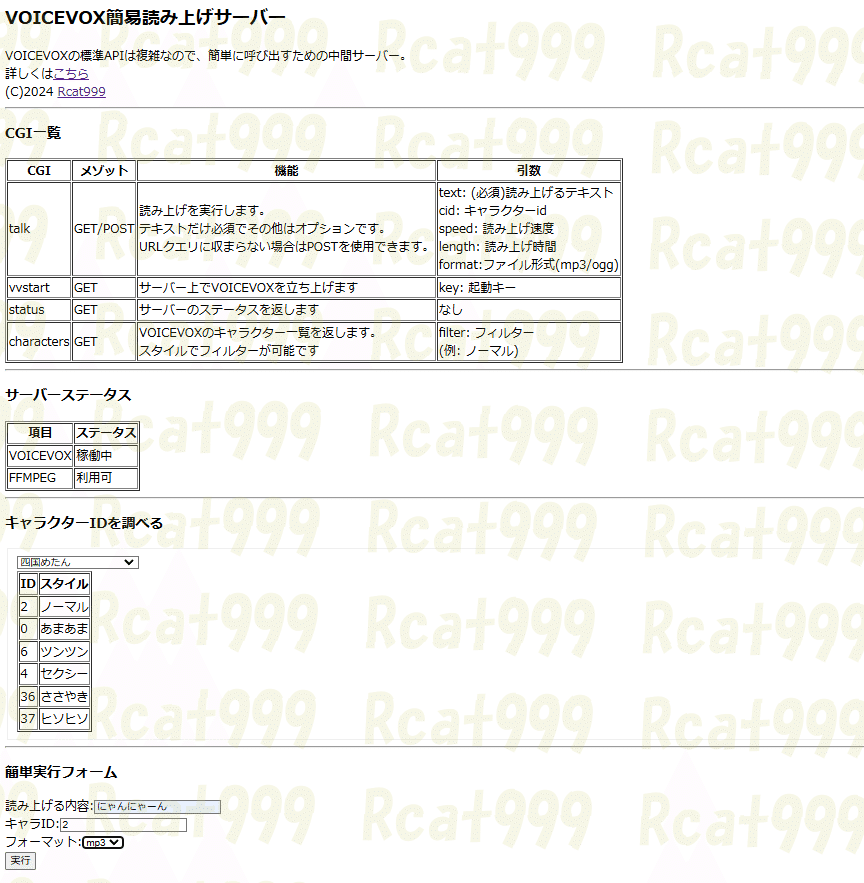
キャラクターID検索機能
トップページの"キャラクターIDを調べるの"ところのドロップダウンボックスで選択することで、各キャラクターのIDとスタイルを確認することができます。
キャラクターを選択することで、その下にIDとスタイルの表が表示されます。

サーバーのステータス表示
本作が依存している2つのソフトウェアの状況を確認できます。
読み上げを行うにはボイスボックスが稼働している必要があります。
出力時にwav以外のフォーマットを指定する場合はFFMPEGが利用可能である必要があります。

※FFMPEGのインストール状況によっては、利用可でも依存ライブラリが無く変換できない場合もあるので、事前にmp3とoggに変換できるか手動で試しておいてください。Ubuntuに標準で入っているものでは変換ができませんでした。
読み上げ機能の使い方
読み上げAPIの使用方法は以下の通りです。
サーバーアドレス/talk?text=読み上げたいテキスト絶対に必要な引数はtextになります。
それ以外は全てオプションでデフォルトでは四国めたんで読み上げを行います。
追加のパラメーターを指定する場合は以下のようになります。
サーバーアドレス/talk?text=読み上げたいテキスト&cid=キャラID&format=mp3/ogg&length=長さパラメーターは&記号で結合できます。
例えば以下の例では、春日つむぎで、出力フォーマットはMP3、ファイルの長さを2秒になるように調整した速度で読み上げを行っています。
速度調整と長さ調整はどちらが片方しか使えませんので、そこはご注意ください。

こちらの例ではフォーマットをoggにして1.5倍速で読み上げという指示にしています。

Pythonからのアクセス方法
Pythonを使ってAPIにアクセスして音声を保存する方法は以下の通りです。
R:\tmp>py
Python 3.11.6 (tags/v3.11.6:8b6ee5b, Oct 2 2023, 14:57:12) [MSC v.1935 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> r = requests.get("http://localhost:25607/talk?text=ねこきゃっとにゃん&cid=3")
>>> f = open("vv.wav","wb")
>>> f.write(r.content)
53804
>>> f.close()このAPIは音声のバイナリをそのまま返してくるので、レスポンスのコンテンツをファイルないし、バイトIOに書き込んで使います。
この場合はファイルに保存しているので、再生してみることで正常に生成できたのかどうかを確認することができます。
POSTで実行する場合
次にPOSTを使ったリクエストの方法を紹介します。
リクエストに必要なキーワードはGETの時と同じです。またURLも同じです。
POSTの場合はリクエストボディをJSON形式にして、その中にパラメーターを入れることで読み上げを行います。
Pythonで行う場合はパラメータを辞書に入れてrequestsでPOSTするのが一番簡単です。
R:\tmp>py
Python 3.11.6 (tags/v3.11.6:8b6ee5b, Oct 2 2023, 14:57:12) [MSC v.1935 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> data = {
... "text":"ねこきゃっとにゃん",
... "cid":14, #冥鳴ひまり
... "format":"ogg"
... }
>>> r = requests.post("http://localhost:25607/talk",json=data)
>>> f = open("vv2.ogg","wb")
>>> f.write
f.write( f.writelines(
>>> f.write(r.content)
10516
>>> f.close()VOICEVOX起動機能の使い方
Windowsであればあまり気にならないと思いますが、Linuxのサーバーで使う場合はVOICEVOXをsystemdに入れておかなければ自動起動はできません。
しかし、2つのプログラムを入れておくのはめんどくさいですよね。
というわけで本プログラムの方からVOICEVOXを起動する機能を入れてあります。
起動スクリプトを用意する
環境によってコマンド1個で起動するのかそうでないのか異なってしまうため、専用のスクリプトを用意することで汎用的に起動できるようにします。
WindowsとLinux用でそれぞれサンプルを入れてありますので、参考に書き換えてください。

事前に手動でこのスクリプトを実行し、VOICEVOXが立ち上がることを確認してください。
本サーバー起動時に公式のAPIへのアクセスができない場合、自動的にVOICEVOXの立ち上げを行います。
起動APIへアクセスする
基本的には起動時に自動で立ち上げるので使うことはないはずですが、必要になった場合は以下のURLにアクセスすることで起動スクリプトを実行することができます。
/vvstart?key=起動キー起動キーはプログラムの中の一番上で定義しています。
好きなキーに書き換えて利用してください。
一応自分で使う前提ですが、そうでない場合があるかもしれないので、起動キーというセーフティをかけています。ログインとかは、そこまでするものでもないのでやっていません。

実際にアクセスするとこんな感じ
この時はすでに起動していたので、エラーメッセージが表示されました。

まとめ
いかがでしたでしょうか?
今回はVOICEVOXを様々なアプリケーションでより柔軟に活用するための中間サーバーを作成しました。
私は特にテキスト生成AIとの組み合わせが期待できると考えています。
今回は中間サーバーを作っただけなので、だから何?って感じですが、今後につなげていきたいと考えています。
それではまたお会いしましょう。
配布情報
配布URL
以下のURLより配布しています。
利用規約に同意の上ご利用ください。
依存モジュール
下記で紹介しているツールに含まれているvoicevox.pyが別途必要です。
いいなと思ったら応援しよう!
