
Mリーグの選手に関するポストをネガポジ分析してみた。

1.概要
1.分析に至った理由
麻雀が趣味であり、麻雀のプロリーグ戦であるMリーグを日々観戦しています。
XでMリーグ関連の投稿(ポスト)を目にする中で、ファンの評価が高い選手は誰なのかということに興味が湧き、Pythonの学習も兼ねて、Xへの投稿の解析にチャレンジしてみました。
2.分析の概要
Python用のX APIライブラリであるTweepyを用い、Mリーグ関連の投稿を収集しました。
オープンソースの形態素解析エンジンである「MeCab」を用い、収集した投稿を形態素解析しました。
東北大学の乾・鈴木研究室のウェブページで公開されている日本語評価極性辞書(名詞編)を用い、形態素解析した各ポストの極性値を算出しました。
そこから各選手に関連するポストの極性値を抜き出し、各選手ごとの極性値として出力しました。
3.分析期間
2024年12月22日から2025年1月11日までに投稿されたポストを収集し、分析を行いました。
4.開発環境
Googleが提供している無料のプログラミング実行環境である、Google Colaboratory(通称:Google Colab)を活用しました。
PCのOSはWindows11 Homeです。
2.具体的な実装の流れ
1.X Developerのアカウントを作成
先ずTweepyを活用する為、X Developerのアカウントを作成します。

アカウントの作成が完了したら、API連携に必要となる各種認証キーを取得します。

Access Token and Secretの"Generate"をクリック



これにてコードの取得は完了です。
尚、Freeプランに於いては、取得できるポストの件数が月100件に制限されています。私は当初この上限を認識しておらず、色々試している内にあっという間に上限に達してしまい、Basicプランにアップグレードしました。Basicプランに於いては月15,000件のポストを取得可能です。料金は月$200(年間契約にするとひと月あたり$175へ割引)であり、決して安い金額ではありません。とはいえ分析するのに月100件では心許ないのも事実なので、必要経費ということで飲み込みました。
2.Xの投稿を収集
事前準備が完了したところで、ようやくコードの実装です。
先ずは、Mリーグ関連のXの投稿を収集する為のコードを作成し、実行します。
########## Xの投稿の収集 ##########
import csv
import datetime
import os
import pytz
import time
import tweepy
# X Developerで取得した各種認証キー
API_Key = '取得したAPI Key'
API_Sec = '取得したAPI Key Secret'
Token = '取得したAccess Token'
Token_Sec = 'Access Token Secret'
BEARER = '取得したBearer Token'
# クライアント設定
client = tweepy.Client(
bearer_token = BEARER,
consumer_key = API_Key,
consumer_secret = API_Sec,
access_token = Token,
access_token_secret = Token_Sec
)
# 検索ワードを指定(リポスト、リプライ、引用リポスト、httpsという単語を含むポスト、日本語以外のポストは除外)
search_term = '(Mリーグ OR Mリーグ OR Mリーグ OR mリーグ OR mリーグ OR mリーグ OR エムリーグ OR エムリーグ OR えむりーぐ) -is:retweet -is:reply -is:quote -https'
# 日本時間で検索期間を指定
jst_timezone = pytz.timezone('Asia/Tokyo')
jst_start_time = datetime.datetime(2025, 1, 3, 0, 0, 0, tzinfo = jst_timezone)
jst_end_time = datetime.datetime(2025, 1, 4, 23, 59, 59, tzinfo = jst_timezone)
# 日本時間をUTCに変換
utc_start_time = jst_start_time.astimezone(pytz.utc).strftime('%Y-%m-%dT%H:%M:%SZ')
utc_end_time = jst_end_time.astimezone(pytz.utc).strftime('%Y-%m-%dT%H:%M:%SZ')
# ポストデータを格納する空のリスト
posts_list = []
# 次のページを取得する為のトークン(初回リクエスト時はNone)
next_token = None
# ポストの取得~CSVファイルへの保存の処理
try:
while True:
# APIで実行するクエリ
response = client.search_recent_tweets(
query = search_term, # 検索ワード
max_results = 100, # 1度に取得する最大件数(上限100件)
start_time = utc_start_time, # 検索開始日時
end_time = utc_end_time, # 検索終了日時
tweet_fields = ['id', 'text', 'created_at'], # 取得するフィールド(項目)
next_token = next_token # 次ページを取得する為のトークン
)
# response.dataが空でなければ(=ポストデータが存在すれば)、指定のフィールドを取得しposts_listへ格納
if response.data:
for post in response.data:
posts_list.append({'id':post.id, 'text':post.text, 'created_at':post.created_at})
# response(APIリクエストの結果)のmetaからnext_tokenを取得し、値がセットされていなければ処理終了
next_token = response.meta.get('next_token')
if not next_token:
break
# 出力先を指定
current_time = datetime.datetime.now(jst_timezone).strftime('%Y%m%d_%H%M%S') # 現在の日時を日本時間で取得、文字列へ変換し変数current_timeへ格納
output_dir = '出力先のディレクトリをフルパスで指定'
filename = os.path.join(output_dir, f'Postsdata_{current_time}.csv') # 出力先のディレクトリと動的に生成したファイル名を結合し、最終的な出力先を指定
# 収集したポストデータをCSVファイルに書き込み、保存
with open(filename, 'w', encoding = 'utf-8-sig', newline = '') as f: # CSVファイルを新たに作成し、【モード:書き込み / 文字コード:UTF-8】で開く ※newline='':ファイルで使われている改行コードを自動認識し変換
writer = csv.DictWriter(f, fieldnames = ['id', 'text', 'created_at']) # ヘッダー名(列名)を設定
writer.writeheader() # CSVファイルの最初の行にヘッダー(列名)を挿入
writer.writerows(posts_list) # posts_listに格納されたデータをCSVファイルに書き込み、保存
# 保存先と取得したポスト数を出力
print(f'保存先: {filename}')
print(f'取得したポスト数: {len(posts_list)}件')
# エラーが発生した場合の処理
except tweepy.TooManyRequests as e: # 規定のリクエスト回数を超過した場合
retry_after = int(e.response.headers.get('Retry-After', 60)) # response内のヘッダーから'Retry-After'フィールドを参照しリクエストを再試行するまでの時間を取得
print(f'レート制限に達しました。{retry_after}秒間待機します。') # エラーメッセージを出力
time.sleep(retry_after) # 指定された秒数、処理を待機
except tweepy.TweepyException as e: # Tweepyの一般的なエラーが検出された場合(例:認証エラー、接続エラー、無効なリクエスト)
print(f'エラーが発生しました: {e}') # エラーメッセージを出力
except Exception as e: # その他の予期せぬエラーが検出された場合(例:ネットワークエラー、システムエラー)
print(f'予期しないエラーが発生しました: {e}') # エラーメッセージを出力コメントで各コードの意味合いは記述していますが、概要は下記の通りです。
検索ワード【Mリーグ OR Mリーグ OR Mリーグ OR Mリーグ OR mリーグ OR mリーグ OR mリーグ OR mリーグ OR エムリーグ OR エムリーグ OR エムリーグ OR エムリーグ OR えむりーぐ】
前述の通り、取得できる投稿件数に上限がある為、無駄な件数消費を防止する目的で、リポスト、リプライ、引用リポストは取得対象から除外しました。また、番組等の告知関連のポストも取得対象から外したかったので、外部のウェブページへのリンクが掲載されているポスト(コード上はhttpsという単語が含まれているポスト)も除外対象に加えました。
取得対象期間は日本時間で指定できるようにし、それをUTC形式に自動変換される形としました。
取得するフィールドは'id'(投稿の一意の識別子)、'text'(投稿本文)、'created_at'(投稿日時)としました。(後々考えると、idは取得不要だったような気も…)
1度の処理で取得できる投稿は100件という制限があり、とはいえ何度もコードを実行するのも手間なので、'next_token'の仕組みを利用する形としました。具体的には、検索結果として表示された投稿から最初の100件を取得した後、自動で次頁に遷移し100件を取得、また次頁に遷移し更に100件を取得、といった形で、1度の実行で100件以上の投稿も自動で取得できるようなコードにしました。
取得したデータはCSV形式で指定した出力先へ保存される形としました。

1列目に'id'、2列目に'text'、3列目に'created_at'という順で、指定したワードを含むポストがちゃんと出力されています。
3.取得したXの投稿を1つのファイルに結合
Tweepyですが、Xの規定により、1週間以上前の投稿を取得することができません。その為、2日に1回程度の間隔で投稿を収集しました。
形態素解析にあたり、複数に分かれて生成されたファイルを1つのファイルに結合しました。
結合するファイルは同一のディレクトリ配下に配置しました。
########## 複数のCSVファイルを1つのファイルに結合 ##########
import os
import pandas as pd
# 結合するCSVファイルの保存先、及び結合したファイルの出力先を指定
input_folder = '結合するファイルの保存先をフルパスで指定'
output_file = '結合したファイルの出力先をフルパスで指定'
# input_folder内の.csvファイルのフルパスを取得しリスト化
csv_files = [os.path.join(input_folder, file) for file in os.listdir(input_folder) if file.endswith('.csv')] # 出力例:['path/to/folder/data.csv', 'path/to/folder/summary.csv']
# CSVファイルを結合
combined_data = pd.DataFrame() # 空のデータフレームを作成
for csv_file in csv_files:
data = pd.read_csv(csv_file, index_col = None) # CSVファイルをデータフレームとして読み込み
combined_data = pd.concat([combined_data, data], ignore_index = True) # 行方向に結合しcombined_dataに追加
# 結合したファイルを新しいCSVファイルとして保存
combined_data.to_csv(output_file, index = False, encoding='utf-8-sig')
print(f'結合されたCSVファイルが保存されました: {output_file}')4.取得したXの投稿を形態素解析し、ポストごとの極性値を算出
########## 取得したXの投稿を形態素解析し、各選手に関連するポストの極性値を算出 ##########
# 必要なモジュールをインストール
try:
import japanize_matplotlib
except ImportError:
!pip install japanize-matplotlib
try:
import MeCab
except ImportError:
!pip install mecab-python3
import japanize_matplotlib
import MeCab
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import re
# 形態素解析ツール(MeCab)を読み込み
mecab = MeCab.Tagger('-Ochasen -r /content/drive/MyDrive/Colab_Notebooks/site-packages/mecab/ipadic/dicdir/mecabrc -d /content/drive/MyDrive/Colab_Notebooks/site-packages/mecab/ipadic/dicdir')
# 収集したポストデータの読み込み
posts_df = pd.read_csv('ファイルをフルパスで指定', header = 0, index_col = 2) # CSVファイルを読み込んでデータフレームを作成(最初の行を列名、3列目をindexとして使用)
posts_df.index = pd.to_datetime(posts_df. index) # indexの値を日時型に変換
posts_df = posts_df[['text']].sort_index(ascending = True) # indexとtext列以外は削除し、indexに基づいて昇順に並び替え
# 極性辞書を読み込み
pndict_df = pd.read_csv('ファイルをフルパスで指定', sep = '\t', encoding = 'utf-8', names = ('term', 'sentiment', 'semantic_category'))
# p,e,n以外の極性値を削除
pndict_df = pndict_df[(pndict_df['sentiment'] == 'p') | (pndict_df['sentiment'] == 'e') | (pndict_df['sentiment'] == 'n')]
# 辞書内の不要な列を削除(単語と極性値だけに)した上で、極性値を数値(1,0,-1)へ変換
pndict_df = pndict_df.drop(pndict_df.columns[2], axis = 1)
pndict_df['sentiment'] = pndict_df['sentiment'].replace({'p':1, 'e':0, 'n':-1})
# 極性辞書をデータフレーム型から辞書型に変換
pndict = pndict_df.set_index('term')['sentiment'].to_dict()
# 関数1:ポストを形態素解析しリスト化
def parse_and_extract_terms(postsdata):
parsed = mecab.parse(postsdata) # 引数として指定されたポストを解析
lines = parsed.split('\n') # 解析結果を改行ごとに区切る
lines = lines[0:-2] # 最終から2行を削除
terms_list = [] # 解析結果を格納する空のリストを作成
for term in lines: # 各行ごとにtermへ格納
data = re.split('\t|,', term) # タブとカンマで区切る
data_list = {'term':data[0]} # 各行の最初の要素(表層形)を、termをkeyとし辞書型で格納
terms_list.append(data_list) # terms_listへ格納
return(terms_list) # 出力イメージ [{'term':'麻雀'}, {'term':'は'}, {'term':'面白い'}]
# 関数2:単語に極性値を付与する関数
def add_pnvalue(terms_list_old):
terms_list_new = [] # 極性値を加えたkey_valueを格納する空のリストを作成
for key_value in terms_list_old: # 関数の引数として指定されたリストからkeyとvalueを1つずつ取り出し、変数key_valueに格納(例:{'term':'麻雀'})
term = key_value['term'] # valueが変数termに格納(例:麻雀)
# 極性辞書内に変数termに格納された単語が存在する場合は対応する極性値を、存在しない場合は'non'を変数pnに格納
if term in pndict:
pn = float(pndict[term])
else:
pn = 'non'
key_value['sentiment'] = pn # key_valueに新しいkey(sentiment)を追加し、valueとして変数pnの値を格納
terms_list_new.append(key_value) # key_valueをterms_list_newへ格納
return terms_list_new # 出力イメージ [{'term':'麻雀', 'sentiment':'non'}, {'term':'は', 'sentiment':'non'}, {'term':'面白い', 'sentiment':1.0}]
# 関数3:ポストごとの平均極性値を算出する関数
def get_mean(post):
pn_list = [] # 単語ごとの極性値を格納する空のリストを作成
for term in post: # ポストの単語を1つずつ取り出し、変数termに格納(例:{'term':'麻雀', 'sentiment':'non'})
pn = term['sentiment'] # 変数pnに単語の極性値を格納
# 極性値が'non'でなければ、pn_listに値を格納
if pn != 'non':
pn_list.append(pn)
# pn_listが空でなければpn_list内の値を平均値を、空なら0を変数pnmeanに格納
if len(pn_list) > 0:
pnmean = np.mean(pn_list)
else:
pnmean = 0
return pnmean
# ポストごとの平均極性値を出力
pnmeans_list = [] # ポストごとの極性値平均を格納する空のリストを作成
for post in posts_df['text']: # ポストのtext列(投稿本文)を1つずつ変数postに格納
terms_list_old = parse_and_extract_terms(post) # 関数1を使用、ポストを形態素解析しリスト化し変数terms_list_oldに格納([{'term':'麻雀'}, {'term':'は'},{'term':'面白い'}])
terms_list_new = add_pnvalue(terms_list_old) # 関数2を使用、ポストの各単語に極性値を付与し変数terms_list_newに格納([{'term':'麻雀', 'sentiment':'non'}, {'term':'は', 'sentiment':'non'}, {'term':'面白い', 'sentiment':1,0}])
pnmean = get_mean(terms_list_new) # 関数3を使用、ポストごとの極性値平均を算出し変数pnmeanに格納(1.0)
pnmeans_list.append(pnmean) # ポストごとの平均極性値をpnmeans_listに格納([0.3333333333333333, 0.75, 0.0, 0.6666666666666666, 0.0, 0.3333333333333333, 0.4, 0.4, 1.0, 0.0])
# 平均極性値を標準化
pnmeans_array = np.array(pnmeans_list) # pnmeans_listをNumPy配列へ変換
pnmean_std = (pnmeans_array - pnmeans_array.mean()) / pnmeans_array.std() # ポストごとの平均極性値を標準化 (各ポストの平均極性値 - 全ポストの平均極性値)/ 標準偏差
posts_df['sentiment'] = pnmean_std # 最初にデータフレームとして読み込んだポストデータ(posts_df)に新しい列(sentiment)を追加し、標準化された極性値を記述概要は下記の通りです。
形態素解析ツールであるMeCab、取得したポストデータ(CSVファイル)、日本語評価極性辞書を取り込みます。
日本語評価極性辞書は、単語ごとに極性値が割り当てられています。今回は、"p""e""n"以外の極性値は削除し、且つp=1、e=0、n=-1といった形で数値に置き換えます。
取り込んだポストデータの"text"列の文章(=投稿本文)を形態素解析し、ポストごとの極性値を算出します。(ポストを形態素解析しリスト化 → 極性辞書を参照し、各単語に極性値を付与 → ポスト単位で単語の平均極性値を算出、という流れです)
算出したポストごとの極性値を標準化します。(極性辞書は"n"が割り当てられた単語が多い為、調整)
尚、日本語評価極性辞書の中に、極性値"p"として「伊達」「剛」「優」、極性値"n"として「浅見」という単語がそれぞれ記述されてました。このままだと、伊達朱里紗プロ、小林剛プロ、鈴木優プロに関するポストの多くがポジティブ判定され、逆に浅見真紀プロに関するポストの多くがネガティブ判定されてしまう恐れがあった為、この4単語は手動で削除しました。
5.各選手に関連するポストの平均値を算出し、グラフ化
# 検索ワードのリスト(選手名、及び愛称)
search_words = {
'内川 幸太郎 プロ':['内川', '幸太郎', 'うちかわ', 'こうたろう', 'ウチカワ', 'ウチカワ', 'コウタロウ', 'コウタロウ', 'うっち', 'ウッチ', 'ウッチ'],
'岡田 紗佳 プロ':['岡田', '紗佳', 'おかだ', 'オカダ', 'オカダ', 'おかぴ', 'オカピ', 'オカピ'],
'渋川 難波 プロ':['渋川', '難波', 'しぶかわ', 'なんば', 'シブカワ', 'シブカワ', 'ナンバ', 'ナンバ', '渋', 'しぶ', 'シブ', 'シブ', '魔神', '魔人'],
'堀 慎吾 プロ':['堀', '慎吾', 'ほり', 'しんご', 'ホリ', 'ホリ', 'シンゴ', 'シンゴ', 'ぽよ', 'ポヨ', 'ポヨ'],
'佐々木 寿人 プロ':['佐々木', '寿人', 'ささき', 'ひさと', 'ササキ', 'ササキ', 'ヒサト', 'ヒサト', 'ひさ', 'ヒサ', 'ヒサ', '魔王'],
'高宮 まり プロ':['高宮', 'たかみや', 'まり', 'タカミヤ', 'タカミヤ', 'マリ', 'マリ'],
'滝沢 和典 プロ':['滝沢', '和典', 'たきざわ', 'かずのり', 'タキザワ', 'タキザワ', 'カズノリ', 'カズノリ', 'たき', 'タキ', 'タキ', 'たっきー', 'タッキー', 'タッキー'],
'伊達 朱里紗 プロ':['伊達', '朱里紗', 'だて', 'ありさ', 'ダテ', 'ダテ', 'アリサ', 'アリサ', 'DATE'],
'小林 剛 プロ':['小林', '剛', 'こばやし', 'ごう', 'コバヤシ', 'コバヤシ', 'ゴウ', 'ゴウ', 'こばご', 'コバゴ', 'コバゴ', 'ろぼ', 'ロボ', 'ロボ', '船長'],
'鈴木 優 プロ':['鈴木優', '優さん', '優プロ', '優選手', '優は', '優と', '優が', '優で', '優なら', '優に', '優から', '優へ', 'ゆう', 'ユウ', 'ユウ', '戦闘民族'],
'仲林 圭 プロ':['仲林', '圭', 'なかばやし', 'けい', 'ナカバヤシ', 'ナカバヤシ', 'ケイ', 'ケイ', 'じゃが', 'ジャガ', 'ジャガ'],
'瑞原 明奈 プロ':['瑞原', '明奈', 'みずはら', 'あきな', 'ミズハラ', 'ミズハラ', 'アキナ', 'アキナ', 'あっき', 'アッキ', 'アッキ'],
'勝又 健志 プロ':['勝又', '健志', 'かつまた', 'けんじ', 'カツマタ', 'カツマタ', 'ケンジ', 'ケンジ', '軍師'],
'二階堂 亜樹 プロ':['亜樹', 'あき', 'アキ', 'アキ'],
'二階堂 瑠美 プロ':['瑠美', 'るみ', 'ルミ', 'ルミ'],
'松ヶ瀬 隆弥 プロ':['松ヶ瀬', '隆弥', 'まつがせ', 'たかや', 'マツガセ', 'マツガセ', 'タカヤ', 'タカヤ', 'がせ', 'ガセ', 'ガセ'],
'浅見 真紀 プロ':['浅見', '真紀', 'あさみ', 'まき', 'アサミ', 'アサミ', 'マキ', 'マキ'],
'鈴木 たろう プロ':['たろう', 'タロウ', 'タロウ', 'ぜうす', 'ゼウス', 'ゼウス'],
'園田 賢 プロ':['園田', '賢', 'そのだ', 'けん', 'ソノダ', 'ソノダ', 'ケン', 'ケン'],
'渡辺 太 プロ':['渡辺', '太', 'わたなべ', 'ふとし', 'ワタナベ', 'ワタナベ', 'フトシ', 'フトシ', 'ふとっし', 'フトッシ', 'フトッシ', 'ないお', 'ナイオ', 'ナイオ'],
'多井 隆晴 プロ':['多井', '隆晴', 'おおい', 'たかはる', 'オオイ', 'オオイ', 'タカハル', 'タカハル', '最速最強'],
'白鳥 翔 プロ':['白鳥', '翔', 'しらとり', 'しょう', 'シラトリ', 'シラトリ', 'ショウ', 'ショウ', 'しょー', 'ショー', 'ショー'],
'日向 藍子 プロ':['日向', '藍子', 'ひなた', 'あいこ', 'ヒナタ', 'ヒナタ', 'アイコ', 'アイコ'],
'松本 吉弘 プロ':['松本', '吉弘', 'まつもと', 'よしひろ', 'マツモト', 'マツモト', 'ヨシヒロ', 'ヨシヒロ', '松', 'まつ', 'マツ', 'マツ'],
'猿川 真寿 プロ':['猿川', '真寿', 'さるかわ', 'まさとし', 'サルカワ', 'サルカワ', 'マサトシ', 'マサトシ', '猿', 'さる', 'サル', 'サル'],
'菅原 千瑛 プロ':['菅原', '千瑛', 'すがわら', 'ひろえ', 'スガワラ', 'スガワラ', 'ヒロエ', 'ヒロエ', 'ヒロ', 'ヒロ'],
'鈴木 大介 プロ':['大介', 'だいすけ', 'ダイスケ', 'ダイスケ', 'D介'],
'中田 花奈 プロ':['中田', '花奈', 'なかだ', 'なかた', 'かな', 'ナカダ', 'ナカダ', 'ナカタ', 'ナカタ', 'カナ', 'カナ'],
'黒沢 咲 プロ':['黒沢', '咲', 'くろさわ', 'さき', 'クロサワ', 'クロサワ', 'サキ', 'サキ', 'セレブ', 'セレブ', 'お嬢'],
'瀬戸熊 直樹 プロ':['瀬戸熊', '直樹', 'せとくま', 'なおき', 'セトクマ', 'セトクマ', 'ナオキ', 'ナオキ', '熊', 'くま', 'クマ', 'クマ'],
'萩原 聖人 プロ':['萩原', '聖人', 'はぎわら', 'まさと', 'ハギワラ', 'ハギワラ', 'マサト', 'マサト', 'ハギ', 'ハギ'],
'本田 朋広 プロ':['本田', '朋広', 'ほんだ', 'ともひろ', 'ホンダ', 'ホンダ', 'トモヒロ', 'トモヒロ', 'プリンス', 'プリンス'],
'浅井 堂岐 プロ':['浅井', '堂岐', 'あさい', 'たかき', 'アサイ', 'アサイ', 'タカキ', 'タカキ'],
'茅森 早香 プロ':['茅森', '早香', 'かやもり', 'カヤモリ', 'カヤモリ'],
'竹内 元太 プロ':['竹内', '元太', 'たけうち', 'げんた', 'タケウチ', 'タケウチ', 'ゲンタ', 'ゲンタ'],
'醍醐 大 プロ':['醍醐', 'だいご', 'ひろし', 'ダイゴ', 'ダイゴ', 'ヒロシ', 'ヒロシ', 'ディエゴ', 'ディエゴ']
}
# 関数4:各選手に関連するポストの平均極性値を算出する関数
def calculate_player_sentiment(posts, search_words):
total_sentiment = 0 # 極性値の合計の初期値を設定
count = 0 # 検索ワードを含むポスト数の初期値を設定
for text, sentiment in zip(posts['text'], posts['sentiment']): # ポスト本文とポストごとの極性値を、それぞれ変数text、sentimentに格納
# ポスト本文にリスト内の何れかの単語を含む場合、total_sentimentにそのポストの極性値を、countに1を加算
if any(word in text for word in search_words):
total_sentiment += sentiment
count += 1
# countが1以上ならポストの平均極性値を算出し、countが0なら平均極性値に0を代入
if count > 0:
average_sentiment = total_sentiment / count
else:
average_sentiment = 0
return average_sentiment # 平均極性値を戻り値として返す
# 各選手に関連するポストの平均極性値を算出
sentiment_ave_dict = {} # 極性値の平均を格納する空の辞書を作成
for list_name, search_word in search_words.items(): # 検索ワードのリストのkeyとvalueを変数list_name、search_wordにそれぞれ格納(例:list_name = '内川 幸太郎' player_name = ['内川', '幸太郎', 'うちかわ', 'こうたろう'])
sentiment_ave = calculate_player_sentiment(posts_df,search_word) # 関数4を使用、検索ワードが含まれているポストの平均極性値を算出し変数sentiment_aveに格納
sentiment_ave_dict[list_name] = sentiment_ave # 平均極性値を、sentiment_ave_dict辞書のkey(選手名)に対応するvalueとして格納
for list_name, sentiment_ave in sentiment_ave_dict.items(): # 選手名を変数list_nameに、その選手に関するポストの平均極性値を変数sentiment_aveにそれぞれ格納
print(f'{list_name}の極性値: {sentiment_ave}')
# 各選手に関連するポストの平均極性値を、縦棒グラフで出力
sorted_sentiment_ave_dict = dict(sorted(sentiment_ave_dict.items(), key = lambda x: x[1], reverse = True)) # sentiment_ave_dict辞書のkey(極性値)を降順でソートし、sorted_sentiment_ave_dict辞書に格納
labels = sorted_sentiment_ave_dict.keys() # X軸として、sorted_sentiment_ave_dict辞書のkey(選手名)を指定
data = sorted_sentiment_ave_dict.values() # Y軸として、sorted_sentiment_ave_dict辞書のvalue(極性値)を指定
plt.bar(labels, data) # 縦棒グラフを描画
plt.xticks(ticks = range(len(labels)), labels = ['\n'.join(list(name)) for name in labels], fontsize = 7) # X軸のラベル位置を選手名の数に合わせて設定、選手名を1文字ずつ分解し文字間を改行で結合
plt.yticks(np.arange(-1, 1.1, 0.1)) # Y軸の最小値、最大値、間隔を設定
plt.grid(axis = 'y') # Y軸にグリッド線を追加
plt.show概要は下記の通りです。
選手ごとに、氏名や愛称をまとめた検索ワードリストを作成します。尚、鈴木優プロについては、名前の「優」を検索ワードに設定すると、「優勝」といった語句が含まれたポストが該当し、結果として過剰にポジティブ判定される傾向が見られたことから、名前+助詞とする等、多少工夫しました。
リスト内の単語が含まれたポストの合計極性値を算出し、それをポストの数で割ります。元々は合計極性値のみ算出していたのですが、分析期間中の対局の有無等により、ポストの数が選手によってばらつきがあることが考えられた為、最終的には1回のポストに於ける平均極性値を算出する形へ見直しました。尚、リストは選手ごとに分けているので、算出された値が、Xの投稿に於ける選手別のネガポジ分析の結果ということになります。(値が大きければ大きいほどその選手に関するポジティブな投稿が多く、逆に小さければ小さいほどその選手に関するネガティブな投稿が多い、ということになります)

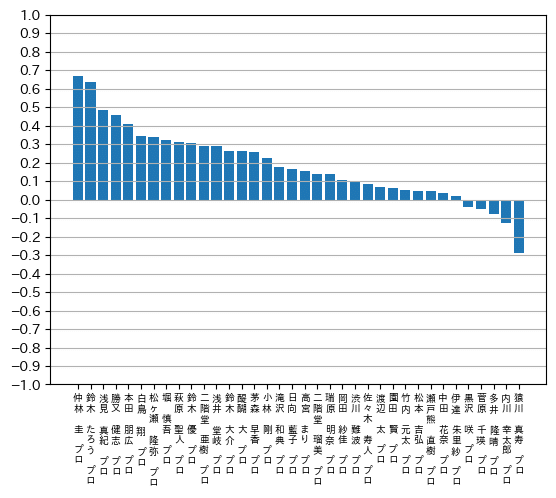
算出された平均極性値を基に、縦棒グラフも出力しました。
6.相関係数の算出
算出された極性値に影響を与えている指標は何なのかという観点で、もう少し調べてみることにしました。
先ず、各選手の今シーズンに於ける個人スコア順位と、今回算出した極性値の相関係数を算出してみました。
# 各選手の個人スコア順位(2025年1月12日時点)
score_ranks = {
'内川 幸太郎 プロ':23, '岡田 紗佳 プロ':36, '渋川 難波 プロ':7, '堀 慎吾 プロ':6,
'佐々木 寿人 プロ':19, '高宮 まり プロ':29, '滝沢 和典 プロ':15, '伊達 朱里紗 プロ':13,
'小林 剛 プロ':27, '鈴木 優 プロ':10, '仲林 圭 プロ':12, '瑞原 明奈 プロ':11,
'勝又 健志 プロ':16, '二階堂 亜樹 プロ':21, '二階堂 瑠美 プロ':22, '松ヶ瀬 隆弥 プロ':31,
'浅見 真紀 プロ':2, '鈴木 たろう プロ':14, '園田 賢 プロ':9, '渡辺 太 プロ':5,
'多井 隆晴 プロ':30, '白鳥 翔 プロ':4, '日向 藍子 プロ':18, '松本 吉弘 プロ':35,
'猿川 真寿 プロ':34, '菅原 千瑛 プロ':25, '鈴木 大介 プロ':33, '中田 花奈 プロ':32,
'黒沢 咲 プロ':26, '瀬戸熊 直樹 プロ':24, '萩原 聖人 プロ':17, '本田 朋広 プロ':8,
'浅井 堂岐 プロ':20, '茅森 早香 プロ':28, '竹内 元太 プロ':1, '醍醐 大 プロ':3
}
# 各選手に関連するポストの平均極性値と個人スコア順位をデータフレームに格納
sentiment_and_rank = {
'平均極性値': list(sentiment_ave_dict.values()), # 出力例 '極性値': [0.48325073374368865, 0.05155469892995288, 0.26338079095195094]
'個人スコア順位': list(score_ranks.values()) # 出力例 '個人スコア順位': [2, 1, 3]
}
sentiment_and_rank_df = pd.DataFrame(sentiment_and_rank) # sentiment_and_rank辞書をデータフレーム型に変換
# 個人スコア順位を反転
maxrank = sentiment_and_rank_df['個人スコア順位'].max() # 個人スコア順位の最大値を取得(最下位の値)
sentiment_and_rank_df['個人スコア順位(反転)'] = maxrank - sentiment_and_rank_df['個人スコア順位'] + 1 # データフレーム型に'個人スコア順位(反転)'列を追加し、最下位の値 - 個人スコア順位列の値 + 1の値を格納(例:2位 33 - 2 + 1 = 32)
# 各選手に関連するポストの合計極性値と個人スコア順位の相関係数を出力
correlation_sentiment_and_rank = sentiment_and_rank_df['平均極性値'].corr(sentiment_and_rank_df['個人スコア順位(反転)'])
print('個人スコア順位との相関係数:', correlation_sentiment_and_rank)注意点として、極性値は高ければ高いほど良い(=ポジティブな投稿が多い)という判断になりますが、個人スコア順位は値が小さければ小さいほど良い(=今シーズンの成績が良い)ものなので、そのままでは正しく相関係数が算出されません。その為、個人スコア順位を少し加工しました。具体的には、値を反転させ、成績が良いほど値が大きくなるような形としました。(例:1位 → 32、2位 → 31、・・・32位 → 1)
コードを実行し得られた値は「0.3954192962953229」でした。
相関係数は下記のような目安とされており、算出された極性値と個人スコア順位の間には「弱い正の相関がある」(=個人スコア順位が高ければ高いほど、ポジティブな投稿が多い傾向にある)、と判断されます。
0.7 ~ 1.0 かなり強い正の相関がある
0.4 ~ 0.7 正の相関がある
0.2 ~ 0.4 弱い正の相関がある
-0.2 ~ 0.2 ほとんど相関がない
-0.4 ~ -0.2 弱い負の相関がある
-0.7 ~ -0.4 負の相関がある
-1.0 ~ -0.7 かなり強い負の相関がある
続いて、各選手のXのフォロワー数との相関関係を調べてみました。
# 各選手のXフォロワー数(2025年1月1日時点)
followers = {
'内川 幸太郎 プロ':92000, '岡田 紗佳 プロ':4521000, '渋川 難波 プロ':874000, '堀 慎吾 プロ':775000,
'佐々木 寿人 プロ':1355000, '高宮 まり プロ':1762000, '滝沢 和典 プロ':1158000, '伊達 朱里紗 プロ':1986000,
'小林 剛 プロ':955000, '鈴木 優 プロ':518000, '仲林 圭 プロ':667000, '瑞原 明奈 プロ':1544000,
'勝又 健志 プロ':486000, '二階堂 亜樹 プロ':1084000, '二階堂 瑠美 プロ':1025000, '松ヶ瀬 隆弥 プロ':497000,
'浅見 真紀 プロ':241000, '鈴木 たろう プロ':69000, '園田 賢 プロ':819000, '渡辺 太 プロ':389000,
'多井 隆晴 プロ':1966000, '白鳥 翔 プロ':1139000, '日向 藍子 プロ':928000, '松本 吉弘 プロ':1229000,
'猿川 真寿 プロ':402000, '菅原 千瑛 プロ':652000, '鈴木 大介 プロ':302000, '中田 花奈 プロ':1243000,
'黒沢 咲 プロ':915000, '瀬戸熊 直樹 プロ':855000, '萩原 聖人 プロ':0, '本田 朋広 プロ':518000,
'浅井 堂岐 プロ':227000, '茅森 早香 プロ':798000, '竹内 元太 プロ':206000, '醍醐 大 プロ':324000
}
# 各選手に関連するポストの平均極性値とXフォロワー数をデータフレームに格納
sentiment_and_follower = {
'平均極性値': [sentiment_ave_dict[name] for name, follower in followers.items() if follower > 0],
'Xフォロワー数': [follower for follower in followers.values() if follower > 0]
}
sentiment_and_follower_df = pd.DataFrame(sentiment_and_follower)
# 各選手に関連するポストの平均極性値とXフォロワー数の相関係数を出力
correlation_sentiment_and_follower = sentiment_and_follower_df['平均極性値'].corr(sentiment_and_follower_df['Xフォロワー数'])
print('Xフォロワー数との相関係数:', correlation_sentiment_and_follower)コードを実行し得られた値は「-0.2435160895157632」でした。
前述した基準と照らしてみると、「弱い負の相関がある」(=Xのフォロワー数が多ければ多いほど、ネガティブなポストが多い傾向にある)という判断になります。
3.結論
1.分析を通して分かったこと
今回の分析に於いて、最もポジティブな投稿が多い傾向にあった仲林圭プロは、1/11に自団体の最高峰タイトルである雀王戦で連覇を達成したことが大きく影響しているものと思われます。また、2番目にポジティブな投稿が多い傾向にあった鈴木たろうプロは、結婚を発表されたことで祝福のポストが多かったことが影響しているのではないかと推察しています。
今回は分析期間が短く、結果、その期間中に話題になった選手に対するポジティブな投稿が分析に大きく影響した面があると認識しています。
相関関係については、個人成績と弱い正の相関が、Xフォロワー数と弱い負の相関がある、という結果を得ることができました。
2.今後やりたいこと
継続してXの投稿を収集し、より信憑性の高い分析結果を得られればと考えています。
今回は東北大学の乾・鈴木研究室のウェブページで公開されている日本語評価極性辞書(名詞編)を極性値算出に用いましたが、他の辞書を活用した分析も行いたいと考えています。
成績は良いのに分析上はネガティブな投稿が多い選手(=過小評価されている選手)、逆に成績は悪いのにポジティブな投稿が多い選手(=過大評価されている選手)を明らかにできればと考えています。