
量子誤り訂正入門

量子誤り訂正とは、量子計算の過程で発生する誤りを訂正する技術です。この技術は、量子コンピュータに特有の技術ではなく、我々が普段使用している計算機でも使用されています。現代の非常に高性能なコンピュータでも、非常に僅かな確率ではありますが、計算の途中でエラーが発生します。しかし、誤り訂正技術を用いることで正確な計算ができるのです。
量子誤り訂正がなぜ必要か
量子コンピュータにおいても、この誤り訂正技術は非常に重要になります。例えば、最先端の研究で実現されている量子ゲートの成功確率は、99~99.9%程度となっています。仮に、一回のゲートの成功確率を99%としたとき、そのような量子ゲートを$${n}$$回作用させた時の成功確率は、
$$
0.99 \times 0.99 \times \cdots \times 0.99 = (0.99)^n
$$
と計算されるので、量子ゲートの数$${n}$$が増えるにつれて、成功確率が小さくなります。つまり、量子コンピュータで大規模な計算を実現するためには、量子誤り訂正は必須の技術なのです。
古典計算における誤り訂正の符号
量子誤り訂正の中身に入っていく前に、古典計算における誤り訂正技術を先に学びましょう。古典計算における誤り訂正符号は、これまで様々な方式が提案されてきましたが、基本的な誤り訂正符号の考え方は、情報に冗長性を持たせることで、発生したエラーを検出および訂正するというものです。
反復符号
最も単純な誤り訂正符号である反復符号(repetition code)について学びましょう。今、田中さんから山田さんへ、あるビット0を送ることを考えます。

しかし、田中さんと山田さんを結ぶ情報の通信路にノイズがある場合、送信した情報がノイズの影響で正確に伝わらない可能性があります。

例えば、このノイズの影響によって、
$$
0\rightarrow1
$$
というビット反転エラーが起きることが考えられます。つまりノイズの影響によって、正確な情報処理を行うことができません。
それでは、どうすればいいのでしょうか。解決策を考えるために、今の状況を少しモデル化して考えてみましょう。今、ノイズによってビット反転が起こる確率を$${p}$$とします。つまり、
確率$${p}$$でビット反転エラー
確率$${1-p}$$でエラーが起こらない
と考えます。
情報の冗長化
さて、このようなノイズの影響から情報を守るためにはどうすればいいのでしょうか。結論から答えると、「たくさんのビットを使って守りたい情報を表現する」ということを行います。つまり、情報に冗長性を足すことで情報の一部分が失われたとしても、元の情報を取り戻すことができるようにします。
3ビットの例
例として、3ビットを使って情報の冗長化を行うことを考えてみましょう。ここで、ビット0と1を以下のようにエンコードします。
$$
\begin{cases}
0 \rightarrow 000 \\
1 \rightarrow 111
\end{cases}
$$
つまり、同じ情報を何度も送ることによって、情報の冗長化を図るという作戦となります。もしエンコードしたビット列を送った際に、ノイズの影響でエラーが発生し、一つのビットが反転したとします。
$$
000 \rightarrow 010
$$
この時多数決をとると、0のほうが多いことがわかるので、元の情報0を復元することが可能となります。
$$
000 \rightarrow 010 \rightarrow 0
$$
しかし一方で、2つ以上のビットが反転した場合はどうなるでしょうか。
$$
000 \rightarrow 011 \rightarrow 1
$$
このように、2つ以上のビットが反転した場合は、エラー訂正に失敗することがわかります。
さて、実際にこの冗長化によってエラーが起こる確率$${p}$$がどのように変化するかを見ていきましょう。3ビットの場合、以下のバターンのエラーが起こることがわかります。
全てのビットが反転しない確率: $${p_0 = (1-p)^3}$$
1つのビットが反転する確率: $${p_1 = 3p(1-p)^2=3p^2-3p^3}$$
2つのビットが反転する確率: $${p_2 = 3p^2(1-p)=3p^2-3p^3}$$
全てのビットが反転する確率: $${p_3 = p^3}$$
3ビットの場合は、2つ以上のビットが反転した場合誤り訂正が失敗するので、そのような確率を求めると、
$$
P_{error} = p_3 + p_2 = p^3 + 3p^2-3p^3 = 3p^2-2p^3
$$
となります。この値とエンコードしなかった場合のエラー確率($${P_{error} = p}$$)をプロットしたものが以下のグラフです。

このグラフから明らかなように、$${p<0.5}$$の領域では、3つのビットを使ってエンコードした場合のエラー確率が元々のエラー確率よりも小さくなっていることがわかります。また、ビット数を増やした時のエラー確率の変化をこちらのグラフに示しています。
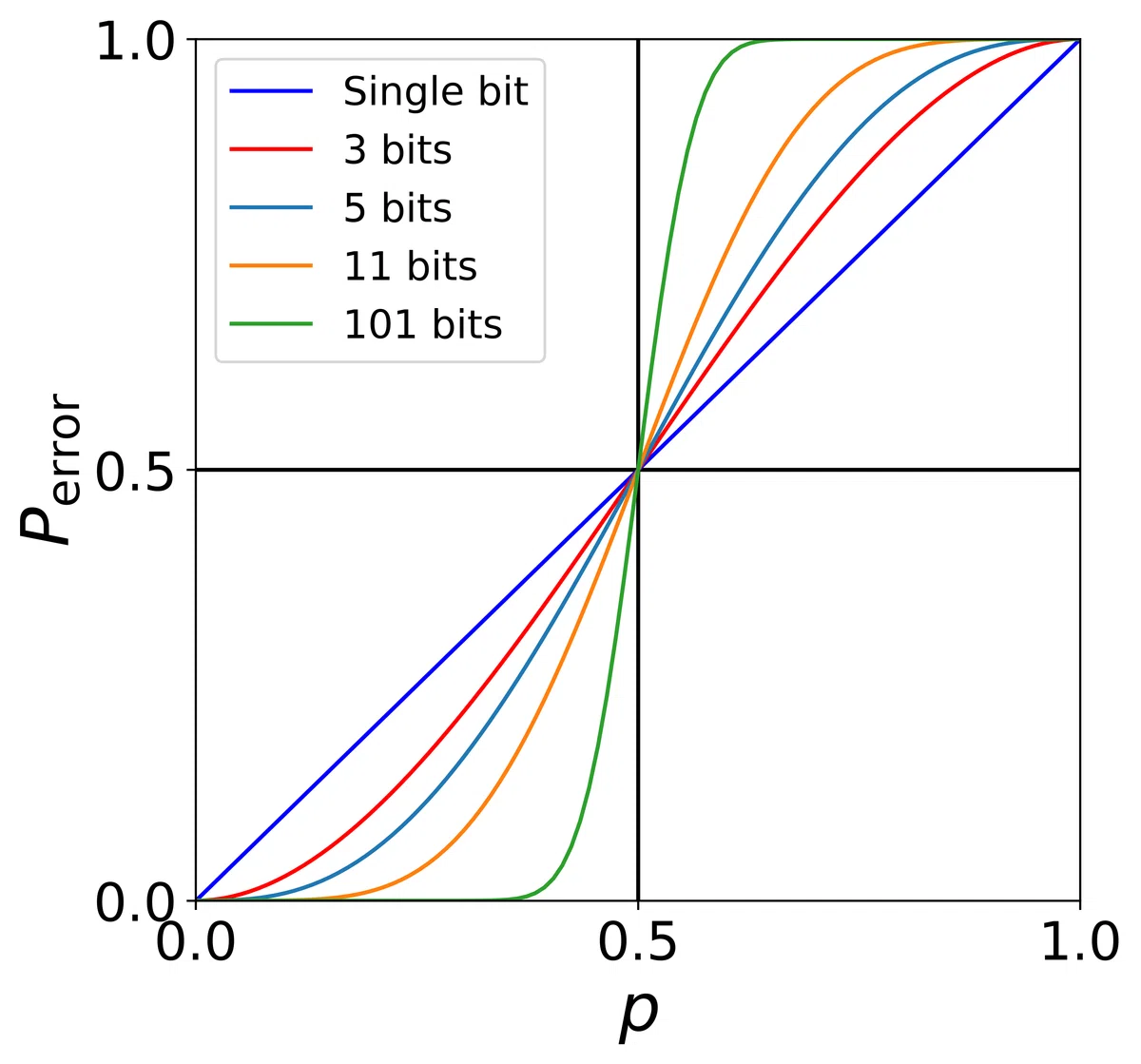
このように多くのビットを用いてエンコードすることで、エラーが発生する確率を小さくすることができるのです。
量子版反復符号?
ここまで、古典の誤り訂正符号の一例を学んできました。ここからは、量子誤り訂正符号の基礎的な内容について見ていきましょう。
さて、古典の誤り訂正も、量子誤り訂正も、「情報に冗長性を加えることで、エラーから守る」という考え方は同じです。それでは、先ほどの反復符号をそのまま量子情報に応用して、量子誤り訂正符号を構築することができるでしょうか。残念ながら、以下に挙げる量子情報特有の性質から、量子誤り訂正はそこまで単純な話ではないのです。
量子誤り訂正符号が難しい理由
理由1: No-cloning定理により量子情報の複製ができない
反復符号では、同じ情報を複製し、繰り返し情報を送信することで情報の冗長化を行っていました。しかし、量子情報に関してはno-cloning定理の存在によって、量子情報を複製することができないため、単純に反復符号を応用することができません。
No-cloning定理とは、未知の量子情報のコピーをつくることができないという定理です。数式で表現すると、任意の量子状態$${\ket{\psi}}$$に対して、
$$
\ket{\psi}\ket{0} \rightarrow \ket{\psi}\ket{\psi}
$$
を実現するようなユニタリ操作が存在しないということを意味しています。
理由2: 測定によって量子状態が壊れる
反復符号でも見たように、誤り訂正をする際には、出力された古典ビットの状態を調べて、その状態に応じて適切な操作を行っています。しかし一方で、量子状態は観測をすることによってその状態壊れてしまいます。
例えば、$${\ket{\psi}=\alpha\ket{0}+\beta\ket{1}}$$を観測したときに、確率$${|\alpha|^2 (|\beta|^2)}$$で量子状態$${\ket{0} (\ket{1})}$$が得られることとなります。つまり、うかつに量子情報の中身を確認することができないのです。
理由3: アナログなエラー
古典のビットにおけるエラーは、
$$
\begin{cases}
0\rightarrow1 \\
1\rightarrow0
\end{cases}
$$
のような、ビット反転エラーだけでした。当然、量子情報においても、
$$
\begin{cases}
\ket{0}\rightarrow \ket{1} \\
\ket{1}\rightarrow \ket{0}
\end{cases}
$$
のようなビット反転のエラーも起こります。また、
$$
\frac{1}{\sqrt{2}}(\ket{0}+\ket{1})\rightarrow \frac{1}{\sqrt{2}}(\ket{0}-\ket{1})
$$
といった、位相反転のエラーも存在します。しかし、これだけではありません。古典におけるエラーと違う点は、アナログなエラーが起こるということでえす。例えば、以下のような、回転角$${\theta}$$だけ回ったような回転エラーも起こります。
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow (\alpha\ket{0}+\beta\ket{1})\cos\frac{\theta}{2} + (-\beta\ket{0}+\alpha\ket{1})\sin\frac{\theta}{2}
$$
また、以下のように$${z}$$軸に対して、微小回転したエラーも起こります。
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow \alpha\ket{0}+e^{i\delta}\beta\ket{1}
$$
これらは、もとの量子状態とほとんど変わらないのですが、同じ量子状態ではないのです。つまりこのように多様で複雑なエラーを訂正する必要があるのです。
量子誤り訂正符号
ここまで、古典と量子の誤り訂正技術の違いについて解説しました。その結果、古典の誤り訂正と比べて、量子誤りを訂正はそこまで単純な技術ではないことがわかりました。
それでは量子誤り訂正を実装することは不可能なのでしょうか。実は、少し工夫をすることで、量子誤り訂正は実現可能になります。ここでは、比較的わかりやすい例である3量子ビットを用いた量子誤りを訂正符号について勉強していきましょう。
3-qubit code
3量子ビット符号では、3個の量子ビットを使って、様々なエラーを訂正することが可能になります。3量子ビット符号では
$$
\begin{cases}
\ket{0}\rightarrow \ket{000}\equiv \ket{0_L} \\
\ket{1}\rightarrow \ket{111}\equiv \ket{1_L}
\end{cases}
$$
というエンコードを行います。ここで、$${\ket{0_L}}$$と$${\ket{1_L}}$$を論理量子ビットと呼び、この論理ビットを構成している各量子ビットを物理量子ビットと呼びます。つまり、量子情報
$$
\ket{\psi}=\alpha\ket{0}+\beta\ket{1}
$$
に対して、
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow \alpha\ket{000}+\beta\ket{111}
$$
となるようにエンコードを行います。
ビット反転エラーの訂正
上記のようなエンコーディングを用いることで、
$$
\begin{cases}
\ket{0}\rightarrow \ket{1} \\
\ket{1}\rightarrow \ket{0}
\end{cases}
$$
のような単一量子ビットに対するビット反転エラーを訂正することができるのです。
エンコーディング
3量子ビット符号では、先ほども述べたように、
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow \alpha\ket{000}+\beta\ket{111}
$$
のようなエンコーディングを行います。このようなエンコーディングは、以下のような量子回路によって実現することができます。

この回路の仕組みを順に追っていくと、
Step1: 初期状態
$$
\ket{\psi}\ket{0}\ket{0}=(\alpha\ket{0}+\beta\ket{1})\ket{0}\ket{0}=\alpha\ket{000}+\beta\ket{100}
$$
Step2: 1つ目のCNOTゲート
$$
\alpha\ket{000}+\beta\ket{100}\rightarrow\alpha\ket{000}+\beta\ket{110}
$$
Step3: 2つ目のCNOTゲート
$$
\alpha\ket{000}+\beta\ket{110}\rightarrow\alpha\ket{000}+\beta\ket{111}
$$
となります。
エラーの検出
誤りを訂正するためには、どの量子ビットにどんなエラーが発生したかを知る必要があります。まず、どの量子ビットにビット反転エラーが発生したのかを調べる方法を考えてみましょう。結論から答えると、これは、$${i}$$番目と$${i+1}$$番目の量子ビットに対する$${Z_i Z_{i+1} (i=1, 2)}$$に対する固有値
$$
\begin{cases}
Z_iZ_{i+1}\ket{00} = \ket{00} \\ Z_iZ_{i+1}\ket{01} = -\ket{01} \\ Z_iZ_{i+1}\ket{10} = -\ket{10} \\ Z_iZ_{i+1}\ket{11} = \ket{11}
\end{cases}
$$
を測定することで解決します。
例1: エラー無し
まず、簡単な場合としてエラーが起こらなかった場合を考えてみましょう。エラーが起こらなかった場合は、当然量子状態には何の変化もありません。
$$
\alpha\ket{000}+\beta\ket{111} \rightarrow \alpha\ket{000}+\beta\ket{111}
$$
そしてこの時、
$$
\begin{cases}
Z_1Z_2 = 1 \\ Z_2Z_3 = 1
\end{cases}
$$
となります。
例2: 1番目の量子ビットにエラーが起こった場合
$$
\alpha\ket{000}+\beta\ket{111} \rightarrow \alpha\ket{100}+\beta\ket{011}
$$
$$
\begin{cases}
Z_1Z_2 = -1 \\ Z_2Z_3 = 1
\end{cases}
$$
例3: 2番目の量子ビットにエラーが起こった場合
$$
\alpha\ket{000}+\beta\ket{111} \rightarrow \alpha\ket{010}+\beta\ket{101}
$$
$$
\begin{cases}
Z_1Z_2 = -1 \\ Z_2Z_3 = -1
\end{cases}
$$
例4: 3番目の量子ビットにエラーが起こった場合
$$
\alpha\ket{000}+\beta\ket{111} \rightarrow \alpha\ket{001}+\beta\ket{110}
$$
$$
\begin{cases}
Z_1Z_2 = 1 \\ Z_2Z_3 = -1
\end{cases}
$$
つまり、$${Z_i Z_{i+1}}$$に対する固有値は、隣り合う量子ビットの状態が同じ場合には$${+1}$$、違う場合には$${-1}$$となることがわかります。そして、$${Z_1 Z_2}$$と$${Z_2 Z_3}$$を調べることによって、どの量子ビットにエラーが発生したのかがわかるのです。
エラー検出のための量子回路
さて、エラーがどの量子ビットに発生したのかを調べる方法について解説しました。しかし前述したように、量子ビットを測定すると、その量子状態を壊してしまうため、うかつに量子ビットを測定することはできません。
そこで、補助量子ビットを用いることで、保護したい量子ビットに対して直接測定を行うことを回避します。それでは、まず$${Z_1 Z_2}$$と$${Z_2 Z_3}$$を測定するための量子回路を見てみましょう。

エラーがない場合
エラーが起こらなかった場合、測定前の量子状態は、
$$
(\alpha\ket{000}+\beta\ket{111})\ket{00}
$$
となっており、補助量子ビットの状態から$${Z_1 Z_2}$$と$${Z_2 Z_3}$$はともに$${1}$$となることがわかります。
1番目の量子ビットにエラー起こった場合
測定前の量子状態は、
$$
(\alpha\ket{100}+\beta\ket{011})\ket{10}
$$
となっており、$${Z_1 Z_2=-1}$$、$${Z_2 Z_3=1}$$となります。2番目または、3番目の量子ビットにエラーが起こった場合も、同様に計算できます。このように補助量子ビットを用いることで、論理量子ビットの量子状態を壊すことなく、$${Z_1 Z_2}$$と$${Z_2 Z_3}$$を測定することができます。
エラーの訂正
さて、エラーを検出した後は、エラーを訂正する必要があります。これは、測定した結果に応じてエラーが発生した量子ビットに対して、$${X}$$ゲートを作用させればいいことがわかります。一例として、トフォリゲートを用いたエラー訂正のための量子回路を載せます。

以上のようなステップを踏むことで、3量子ビットを用いてビット反転エラーを訂正することができるのです。
位相反転エラーの訂正
さて、上記のような量子回路を構成することで、量子ビットの反転エラーを訂正することができることがわかりました。しかし、量子ビットに起こるエラーは、ビット反転エラー以外にも、位相が反転する位相反転エラーも存在します。
$$
\begin{cases}
\frac{1}{\sqrt{2}}(\ket{0}+\ket{1})\equiv\ket{+} \rightarrow \frac{1}{\sqrt{2}}(\ket{0}-\ket{1})\equiv\ket{-} \\ \frac{1}{\sqrt{2}}(\ket{0}-\ket{1})\equiv\ket{-}\rightarrow \frac{1}{\sqrt{2}}(\ket{0}+\ket{1})\equiv\ket{+}
\end{cases}
$$
3量子ビット符号を用いることで、位相反転エラーも訂正することができます。
エンコーディング
ビット反転エラーを訂正する3量子ビット符号では、
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow \alpha\ket{000}+\beta\ket{111}
$$
のようなエンコーディングを行いました。しかし、このようなエンコーディングでは、位相反転のエラーを検出できません。しかし、このエンコーディングを少し工夫することで、ビット反転エラーと同じようにエラー訂正を行うことができます。
まず、この位相反転エラーによってどのように量子状態が変化するのかを考えてみましょう。位相反転エラーは、
$$
\begin{cases}
\ket{0}\rightarrow \ket{0} \\ \ket{1}\rightarrow -\ket{1}
\end{cases}
$$
のように、$${Z}$$ゲートと同じ作用となっています。ビット反転エラーが$${X}$$ゲートに相当することを考えると、位相反転エラーを検出するには、このように重ね合わせ状態、$${\ket{+}, \ket{-}}$$という基底を使用すればいいことがわかります。
$$
\begin{cases}
\ket{000}\rightarrow \ket{+++}\equiv \ket{0_L} \\ \ket{111}\rightarrow \ket{---}\equiv \ket{1_L}
\end{cases}
$$
当然、
$$
\begin{cases}
H\ket{0}\rightarrow \ket{+} \\ H\ket{1}\rightarrow \ket{-}
\end{cases}
$$
なので、このエンコーディングは、以下のような量子回路で簡単に実現することができます。

この量子回路により、
$$
\alpha\ket{0}+\beta\ket{1}\rightarrow \alpha\ket{+++}+\beta\ket{---}
$$
というエンコードが実現できます。
エラーの検出
位相反転エラーに対しても、ビット反転エラーと同様にして、誤りの検出を行います。しかし、少し基底が変わっているので、今回は、$${i}$$番目と$${i+1}$$番目の量子ビットに対する$${X_i X_{i+1} (i=1, 2)}$$の固有値
$$
\begin{cases}
X_iX_{i+1}\ket{00} = \ket{00} \\ X_iX_{i+1}\ket{01} = -\ket{01} \\ X_iX_{i+1}\ket{10} = -\ket{10} \\ X_iX_{i+1}\ket{11} = \ket{11}
\end{cases}
$$
を測定します。また、これらの値は以下のような量子回路を実行することで測定することができます。

そして、測定した結果に応じてフィードバックを行うことで、位相反転エラーを訂正することができます。

9-qubit Shor code
そして、以上の量子回路を組み合わせることで、1量子ビットにおける任意のエラーを訂正することができる量子誤りを訂正が実現することができます。この量子誤りを訂正符号は、9個の量子ビットで実現され、Shor符号とも呼びます。
エンコーディング
Shor符号は、反転エラーと位相反転エラーを検出できるエンコーディング用の量子回路を組み合わせることで実現され、以下のような量子回路で実現されます。

Shor符号は、9個の物理量子ビットで1個の論理量子ビットを表現します。
$$
\begin{cases}
\ket{0_L} = \frac{1}{2\sqrt{2}}(\ket{000}+\ket{111})(\ket{000}+\ket{111})(\ket{000}+\ket{111}) \\ \ket{1_L} = \frac{1}{2\sqrt{2}}(\ket{000}-\ket{111})(\ket{000}-\ket{111})(\ket{000}-\ket{111})
\end{cases}
$$
このように、エンコーディングを行うことで、1量子ビットに対する、ビット反転エラーと位相反転エラー、またそれらの重ね合わせのエラーを訂正することができます。
エラーの検出
ビット反転エラーの検出
ビット反転エラーの検出は、$${i}$$番目と$${i+1}$$番目の量子ビットに対する$${Z_i Z_{i+1} (i=1, 2)}$$の固有値を測定します。
例えば、1番目の量子ビットにエラーが発生した場合を考えてみましょう。
$$
\frac{\alpha}{2\sqrt{2}}(\ket{000}+\ket{111})(\ket{000}+\ket{111})(\ket{000}+\ket{111})+\frac{\beta}{2\sqrt{2}}(\ket{000}-\ket{111})(\ket{000}-\ket{111})(\ket{000}-\ket{111})
$$
$$
\rightarrow \frac{\alpha}{2\sqrt{2}}(\ket{100}+\ket{011})(\ket{000}+\ket{111})(\ket{000}+\ket{111})+\frac{\beta}{2\sqrt{2}}(\ket{100}-\ket{011})(\ket{000}-\ket{111})(\ket{000}-\ket{111})
$$
この時、$${Z_1Z_2=-1}$$となり、そのほかの場合は$${1}$$となることがわかります。つまり、どの量子ビットにエラーが発生したのかを特定することができます。
位相反転エラーの検出
位相反転エラーの検出は、$${i}$$番目の量子ビットに対する$${X_iX_{i+1}X_{i+2}X_{i+3}X_{i+4}X_{i+5}}$$の固有値を測定します。
例えば、1番目の量子ビットにエラーが発生した場合を考えてみましょう。
$$
\frac{\alpha}{2\sqrt{2}}(\ket{000}+\ket{111})(\ket{000}+\ket{111})(\ket{000}+\ket{111})+\frac{\beta}{2\sqrt{2}}(\ket{000}-\ket{111})(\ket{000}-\ket{111})(\ket{000}-\ket{111})
$$
$$
\rightarrow \frac{\alpha}{2\sqrt{2}}(\ket{000}-\ket{111})(\ket{000}+\ket{111})(\ket{000}+\ket{111})+\frac{\beta}{2\sqrt{2}}(\ket{000}+\ket{111})(\ket{000}-\ket{111})(\ket{000}-\ket{111})
$$
この時、
$$
\begin{cases}
X_1X_2X_3X_4X_5X_6 = -1 \\ X_4X_5X_6X_7X_8X_9 = 1
\end{cases}
$$
となり、1, 2, 3番目の量子ビットのどこにエラーが発生したのかがわかります。この場合、
$$
Z_i (\ket{000}-\ket{111}) = \ket{000}+\ket{111} (i = 1, 2, 3)
$$
となるので、エラーの発生した量子ビットを特定する必要がありません。これらの測定結果に応じて、フィードバックを行うことで、誤り訂正を行うことが可能になります。
(備考): この記事は、以前にQiitaに投稿した内容をアップデートして書いたものになります。