
XBRLを読み込んで大量保有報告書に関するデータを取得する【Python】

今回は、株式関連のデータ収集として大量保有報告書のデータをPythonを用いて集約しようと思います。
大量保有報告書のデータを取得したいと思った背景
詳しく話すと大変ややこしいのですが、ふと大学の研究活動を通して「上場企業経営者の株式保有に関するデータを集めてみよう!」と思いつきました。
上場企業経営者の株式保有数は有価証券報告書を通して年に1回開示される他、保有比率が大きく変動した際には不定期で5%ルール関連の書類でも開示されます。今回は後者の5%ルール関連の書類から株式保有に関するデータを集約します。
5%ルールとは、簡単に言えば「企業の発行済み株式数に対して5%以上の株式を保有すればそれを公にする」ことであり、5%以上の株式を保有したとき、また大きな変動(保有数が大きく変動した、など)に大量保有報告書や変更報告書が作成されます。
以前、XBRLを読み込んで財務数値をCSVに出力するPythonコードについてNoteを書きましたが、XBRLで公開されている金融情報は有価証券報告書や四半期報告書だけではありません。この5%ルールに関するデータもXBRLファイルで作成されます。
↓以前書いたnote
今回は以前財務数値の取得に利用したPythonのコードを応用して、最大5年分の5%ルールの情報もCSVに出力します。
実行環境:Jupyter Notebook
大量保有報告書から得られる情報

大量保有報告書から得られる情報は、主に
・誰が(提出者、大量保有者)
・どこの(保有する銘柄、発行者)
・どんだけ(何株、株数)
・なんで(保有理由)
・いつ買った(義務発生日)
・いつ言った(提出日)
です。この情報を中心に取得していこうと思います。(正確な変数は後ほど...)
手順1. ファイルのダウンロード
今回の5%ルールに関連するデータは、EDINET APIを利用してXBRLをダウンロードします。詳しい手順は以下のサイトを参考にしました。
EDINET APIでデータを要求する際、5%ルールに関連する書類が提出された「日付」と「提出書類」を指定します。(なお、EDINET APIから取得できる情報は過去5年以内のようです)
例えば、2020年1月1日から2020年1月15日までの書類を取得するときは、
##################
### EDINET API ###
##################
#########日付の指定##########
start_date = datetime.date(2020, 1, 1)
end_date = datetime.date(2020,1,15)
period = end_date - start_date
period = int(period.days)
day_list = []
for d in range(period):
day = start_date + datetime.timedelta(days=d)
day_list.append(day)
day_list.append(end_date)
######### EDINETへアクセス #########
for index, day in enumerate(day_list):
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
params = {"date": day, "type": 2}
res = requests.get(url, params=params, proxies=proxies)
json_data = res.json()
print(day)
aa = json_data["results"]
for num in range(len(json_data["results"])):
ordinance_code = json_data["results"][num]["ordinanceCode"]
form_code = json_data["results"][num]["formCode"]
if ordinance_code == "060" and form_code == "010000":
securities_report_doc_list.append(json_data["results"][num]["docID"])
elif ordinance_code == "060" and form_code == "010002":
securities_report_doc_list.append(json_data["results"][num]["docID"])
EDINET APIからは、まず指定した書類のフォルダ名が返ってくるので、securities_report_doc_listにlistとして格納します。
ここで、コード後半にあるordinance code(府令コード)とform code(様式コード)について注目します。EDINET操作ガイドによれば、今回利用する大量保有報告書と変更報告書の府令コード・様式コードが確認できます。異なる書類を取得したい場合はこのコードを変更することで対応できます。

各書類のフォルダ名(doc_id)をもとに、edinetからのダウンロードを開始します。Pythonのrequestsを利用して、DL先のURLとなるdisclosure.edinet-fsa.go.jp/api/v1/documents/ の語尾にフォルダ名を付けて繰り返し処理を実行します。
(例:disclosure.edinet-fsa.go.jp/api/v1/documents/S100HOK6.zip)
##########################
### download zip files ###
##########################
number_of_lists = len(securities_report_doc_list)
print("start downloading zip files...")
for index, doc_id in enumerate(securities_report_doc_list):
print(doc_id, ":", index + 1, "/", number_of_lists)
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + doc_id
params = {"type": 1}
filename = "任意のディレクトリ" + doc_id + ".zip"
res = requests.get(url, params=params, stream=True)
if res.status_code == 200:
with open(filename, 'wb') as file:
for chunk in res.iter_content(chunk_size=1024):
file.write(chunk)手順2. フォルダ内のXBRLを探す
先ほどダウンロードしたファイルは複数の階層構造になっており、XBRLファイルまでのディレクトリ名を取得する必要があります。
例えば ダウンロードしたファイルが S100HOK6.zip である場合、XBRLファイルがあるのは
S100HOK6.zip/XBRL/PublicDoc/****.xbrlです。上のようなディレクトリ名を複数取得する予定なので、file_datasというリストを作成します。
############################
### get xbrl directories ###
############################
file_datas = []
for file_name in securities_report_doc_list:
zip_file = str()
zip_file = "府フォルダをダウンロードしたディレクトリ" + file_name +".zip"
try:
with zipfile.ZipFile(zip_file, 'r') as zip_data:
# ファイルリスト取得
infos = zip_data.infolist()
in_xbrl_dir = zip_file + '/XBRL/PublicDoc/'
# os.chdir(in_xbrl_dir)
for info in infos:
root, ext = os.path.splitext(info.filename)
# os.path.splitextで取得した拡張子名 ext が .xbrlであれば、xbrlディレクトリを保管するリストにディレクトリ名をappend()する
if ext == ".xbrl" and "PublicDoc" in root:
xbrl_file_dir = zip_file + "/" +info.filename
file_datas.append(xbrl_file_dir)
continue
except zipfile.BadZipFile:
print(traceback.format_exc())手順3. XBRLを読み込む
XBRLを読み込む際に利用するライブラリとしてArelleを想定しています。xbrl内のタグを指定するだけで対応する値を返してくれるので非常に便利です。Arelleの環境整備は複雑なのでこちらの記事を参考にしました。
ArelleでXBRLを読むときは、まずmodel_xbrl(オブジェクト?)にxbrlファイルを代入すれば、あとは要素ごとに繰り返し処理を行い、必要なタグを含むfactであるかどうかを探索します。
例えば、大量保有報告書の書類名のみを抽出するときは:
###############
### example ###
###############
from arelle import Cntrl
xbrl_file = "./任意のディレクトリ/****.xbrl"
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
model_xbrl = model_manager.load(xbrl_file)
for fact in model_xbrl.facts:
if fact.concept.qname.localName == "DocumentTitleCoverPage":
print(f'実行結果:{fact.value}')
>>実行結果:大量保有報告書というコードになります。
なお今回抽出する変数は、
"EDINET_CODE"
"書類名"
"根拠",
提出者"
"提出者住所"
"義務発生日"
"報告日"
"保有者数"
"保有形態"
"報告理由"
"保有目的"
"重要提案行為等"
"発行者"
"証券コード",
"市場"
"保有株券等の数(総数)"
"保有潜在株券等の数"
"株券等保有割合"
"直前の保有割合"
とします。
以下が読み込みコードになります:
#######################
### read xbrl facts ###
#######################
from arelle import Cntrl
i = 0
count_of_files = len(file_datas)
for index, xbrl_file in enumerate(file_datas):
print(f'loading data {index + 1} / {count_of_files}')
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
model_xbrl = model_manager.load(xbrl_file)
for fact in model_xbrl.facts:
##提出書類の表紙情報##
if fact.concept.qname.localName == "DocumentTitleCoverPage":
doc_title = fact.value
elif fact.concept.qname.localName == "ClauseOfStipulationCoverPage":
konkyo = fact.value
elif fact.concept.qname.localName == "NameCoverPage":
filer_name = fact.value
elif fact.concept.qname.localName == "ResidentialAddressOrAddressOfRegisteredHeadquarterCoverPage":
filer_address = fact.value
elif fact.concept.qname.localName == "DateWhenFilingRequirementAroseCoverPage":
arose_date = fact.value
elif fact.concept.qname.localName == "FilingDateCoverPage":
filing_date = fact.value
elif fact.concept.qname.localName == "TotalNumberOfFilersAndJointHoldersCoverPage":
numof_holders = fact.value
elif fact.concept.qname.localName == "ArrangementOfFilingCoverPage":
keitai = fact.value
elif fact.concept.qname.localName == "ReasonForFilingChangeReportCoverPage":
reason_for_filing_change = fact.value
elif fact.concept.qname.localName == "ReasonForFilingChangeReportCoverPageNA":
no_reason_for_filing_change = fact.value
##発行者情報##
elif fact.concept.qname.localName == "NameOfIssuer":
issuer = fact.value
elif fact.concept.qname.localName == "SecurityCodeOfIssuer":
sec_code = fact.value
elif fact.concept.qname.localName == "StockListing":
stock_listing = fact.value
##提出者に関する事項##
elif fact.concept.qname.localName == "IndividualOrCorporation":
indiv_or_corp = fact.value
elif fact.concept.qname.localName == "Name":
nameof_holder = fact.value
elif fact.concept.qname.localName == "ResidentialAddressOrAddressOfRegisteredHeadquarter":
address_of_holder = fact.value
elif fact.concept.qname.localName == "FormerName":
old_name = fact.value
elif fact.concept.qname.localName == "FormerResidentialAddressOrAddressOfRegisteredHeadquarter":
old_address = fact.value
#個人の場合
elif fact.concept.qname.localName == "DateOfBirth":
dob_of_holder = fact.value
elif fact.concept.qname.localName == "Occupation":
occup_of_holder = fact.value
elif fact.concept.qname.localName == "NameOfEmployer":
kinmusaki_of_holder = fact.value
elif fact.concept.qname.localName == "AddressOfEmployer":
kinmusaki_address_of_holder = fact.value
#法人の場合
elif fact.concept.qname.localName == "DateOfEstablishment":
dob_of_corp = fact.value
elif fact.concept.qname.localName == "NameOfRepresentative":
name_of_corprep = fact.value
elif fact.concept.qname.localName == "JobTitleOfRepresentative":
jobtitle_of_corprep = fact.value
elif fact.concept.qname.localName == "DescriptionOfBusiness":
business_of_corp = fact.value
##保有目的##
elif fact.concept.qname.localName == "PurposeOfHolding":
purpose_of_holdings = fact.value
# elif fact.concept.qname.localName == "PurposeOfHoldingNA":
# no_purpose_of_holdings = fact.value
##重要提案行為等##
elif fact.concept.qname.localName == "ActOfMakingImportantProposalEtc":
act_of_prop = fact.value
# elif fact.concept.qname.localName == "ActOfMakingImportantProposalEtcNA":
# no_act_of_prop = fact.value
##保有株式等##
elif fact.concept.qname.localName == "TotalNumberOfStocksEtcHeld":
total_num_of_stock = fact.value
elif fact.concept.qname.localName == "NumberOfResidualStocksHeld":
total_num_of_residual_stock = fact.value
elif fact.concept.qname.localName == "HoldingRatioOfShareCertificatesEtc":
ratio_final = fact.value
elif fact.concept.qname.localName == "HoldingRatioOfShareCertificatesEtcPerLastReport":
ratio_last_report = fact.value
elif fact.concept.qname.localName == "DetailsOfAcquisitionsAndDisposalsOfStocksEtcIssuedByIssuerOfSaidStocksEtcDuringLast60DaysTextBlock":
sixtydays = fact.value
elif fact.concept.qname.localName == "EDINETCodeDEI":
if fact.contextID =="FilingDateInstant":
edinet_code = fact.value
datalist = list()
datalist = [[edinet_code, doc_title, konkyo, filer_name, filer_address, arose_date, filing_date, numof_holders, keitai, reason_for_filing_change, purpose_of_holdings, act_of_prop, issuer, sec_code, stock_listing, total_num_of_stock, total_num_of_residual_stock, ratio_final, ratio_last_report]]
datalist
df = pd.DataFrame(datalist, columns = ["EDINET_CODE", "書類名", "根拠", "提出者", "提出者住所", "義務発生日", "報告日", "保有者数",
"保有形態", "報告理由", "保有目的", "重要提案行為等", "発行者", "証券コード",
"市場", "保有株券等の数(総数)", "保有潜在株券等の数", "株券等保有割合",
"直前の保有割合"])
df
print(f'書類名 :{doc_title}')
print(f'提出根拠 :{konkyo}')
print(f'提出者の氏名 :{filer_name}')
print(f'提出者の住所 :{filer_address}')
print(f'報告義務発生日 :{arose_date}')
print(f'提出日 :{filing_date}')
print(f'保有者数 :{numof_holders}')
print(f'保有形態 :{keitai}')
print(f'報告義務が発生した理由:{reason_for_filing_change}')
# print(f'義務発生の理由(無し):{no_reason_for_filing_change}')
print(f'保有目的 :{purpose_of_holdings}')
# print(f'保有目的(無し) :{no_purpose_of_holdings}')
print(f'重要提案行為等 :{act_of_prop}')
# print(f'重要提案行為等(無し):{no_act_of_prop}')
print(f'発行者 :{issuer}')
print(f'証券コード :{sec_code}')
print(f'市場 :{stock_listing}')
print(f'保有株券等の数(総数):{total_num_of_stock}')
print(f'保有潜在株券等の数 :{total_num_of_residual_stock}')
print(f'株券等保有割合 :{ratio_final}')
print(f'直前の保有割合 :{ratio_last_report}')
print(sixtydays) #過去60日間の取引履歴
if i == 0:
# 1回目はHeaderを記入する条件分岐
df.to_csv("任意のディレクトリ//****.csv", encoding='cp932', errors='ignore', index = False)
i = i + 1
else:
df.to_csv("任意のディレクトリ//****.csv",mode='a', header=False, encoding='cp932', errors='ignore', index = False)
1個の報告書を読むごとにCSVに出力し、2回目以降でヘッダーを追記しないよう条件分岐しています。(最後に一気にCSV出力するよりもメモリが節約できる...はず)
Q. XBRLタグは、どうやって探すの?
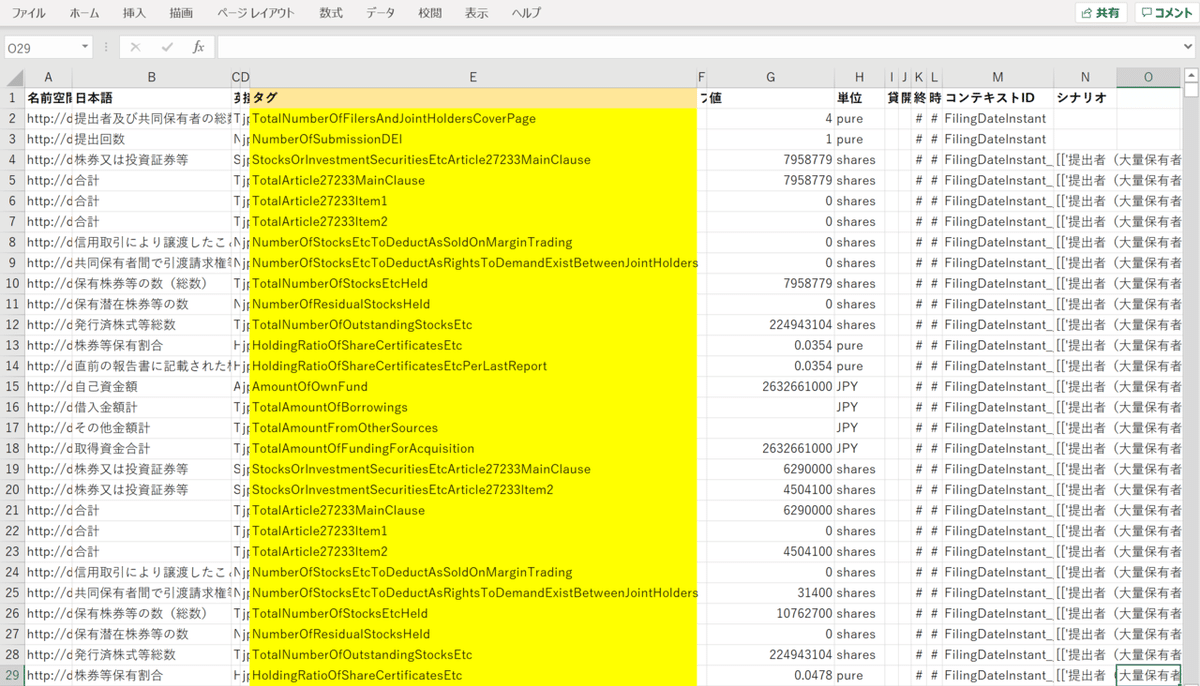
Arelleを用いて指定したタグの値を抽出していますが、自分が利用したいタグがどれなのか 探すのに苦労します。そこで、以下の記事を参考にして、すべてのタグの対になる値や日本語名、単位などを確認しました。
上の記事は有価証券報告書などの会計XBRLを対象にしていますが、大量保有報告書についても同様に必要な情報は確認できます。
付録:抽出したデータの概要
2016年9月20日から2021年9月17日にかけて、取得した報告書数は合計で25,906件で、ほとんどが1人で保有、一部では連名で所有しているケースがあります。
この期間のユニークな提出者はたったの5050件で、サンプルサイズの約1/5となりました。個人による取引だけでなく、大規模な株式取引を主な商いとする企業や銀行が多く報告している可能性が高いです。
ユニークな被報告企業数は3135件で、東証上場企業数とほぼほぼ同じです。反対に、大量保有報告書が提出されていない企業の特徴が気になる結果となりました。


