
EDINETの書類情報をMySQLに書き込む

EDINETに公開されているXBRLを複数年分ダウンロードする下準備として、まずはEDINETに公開されている書類情報を保存しようと思います。
今回はPCの空き容量が少ないのと、最近AWS上で稼働するプログラムを作っているので、勉強を兼ねてDBに書類情報を書き込むようにします。
開発環境
実行環境:Cloud 9(Amazon Linux 2023) t2.micro (1 GiB RAM + 1 vCPU)
データベース:RDS(MySQL)db.t3.micro
①EDINETのアクセスキーを登録する
EDINETは2024年4月1日からversion1のEDINET APIが使用できなくなりました。これまではEDINETの利用登録が無くても利用することができましたが、version2からはアクセスキーがないとEDINET APIの利用ができません。
まずEDINETで公開されているAPIの仕様書をよく読んで、利用登録を進めます。(この時、利用登録をする際には必ずポップアップのブロックを解除してから登録するようにしましょう!私はこの手順をすっ飛ばしていたおかげで30分ほど登録に手こずりました…。どんなシステムでも仕様書はちゃんと読まないといけません。)
②EDINETのAPIのレスポンスを確認する
アクセスキーを取得したら、正しくAPIを利用できるか確認します。
この時、私はChromeの拡張機能であるTalend API Testerを利用しました。
EDINETのAPIは、全部GETでリクエストを送信するのでブラウザの検索欄に直接URLを書き込んでも良いのですが、パラメータが見やすいのと、レスポンスBodyが見やすいのでこの拡張機能を使用しました。

③EDINETのデータを格納するDBのテーブルを作成する
EDINETのAPIを使用する準備ができたので、次はEDINETのデータを保管するためのテーブルを作成します。
EDINETの書類一覧 APIからは1つの書類に対して29種類の情報が格納されています。例えば提出者のEDINETコードやXBRLファイルの有無フラグ、英文ファイルの有無フラグなどがあります。今回はXBRLファイルのダウンロードがしたいので、書類管理番号とXBRLファイルの有無フラグがあれば十分ですが、経験として後から知りたい情報が出てくる(書類の提出時刻が知りたくなる、とか)ので広めに取捨選択してDBに書き込む情報を決定します。

取捨選択した結果、21個のデータを保管することにしました(全然取捨選択できていない…。)。。。このとき、私はGoogle Spreadsheetで変数を書き込んでいます。このままDB定義をすれば、SQLのCREATE TABLE文が書きやすいからです。

Spreadsheetに書き込んだ情報を元にSQL文を作成しました。
Cloud9にログインし、RDSにログインした後、DBにCREATE TABLE文を実行します。ちなみに今回はDB名を「edinet」にしました。
ちゃんとテーブルが作成できたか、下記クエリを実行して確認します。
SHOW COLUMNS FROM table名;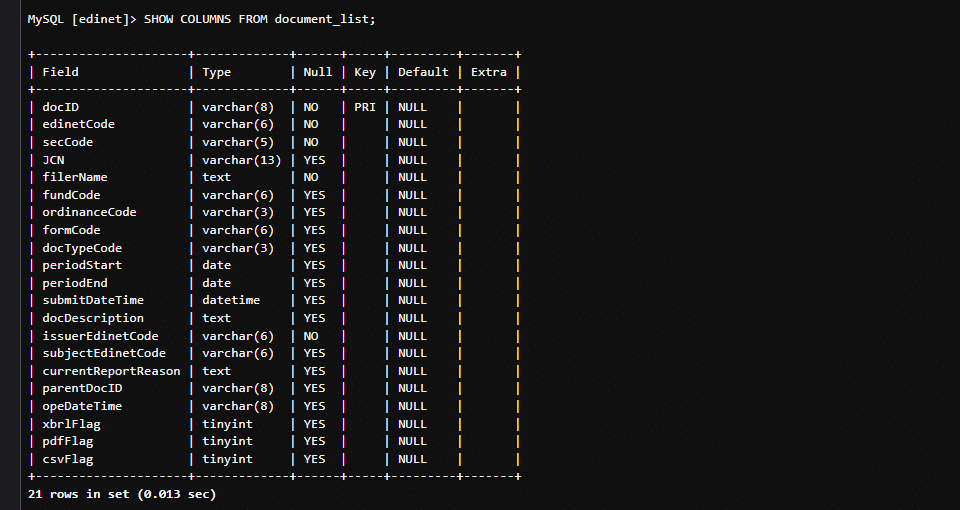
④EDINET APIからデータを取得するコードを書く
EDINET APIからのデータを処理する部分はPythonで実装します。EDINET APIの書類取得コードはいつもXBRLJapanさんがQiitaに投稿しているコードを参考(がっつりコピペ)にしています。とても分かりやすいです。
https://qiita.com/XBRLJapan/items/27e623b8ca871740f352
注意しないといけないのは、APIのバージョンアップに伴って①エンドポイントが変わっているのと②アクセスキーのパラメータをセットする必要があることです。アクセスキーのパラメータは"Subscription-Key"です。
加えて、今回はDBに格納する変数を取捨選択しているので、APIの戻り値からあらかじめ取得対象の変数に絞るよう変更します。
URL = "https://disclosure.edinet-fsa.go.jp/api/v2/documents.json"
EDINET_KEY = "ここにAPIのキーを書き込む"
class ApiResponseError(Exception): # EDINET APIのHTTPレスポンスが200でも、APIのBODY内でレスポンスが404の時がある
pass
def make_day_list(start_date, end_date):
print("start_date:", start_date)
print("end_day:", end_date)
period = end_date - start_date
period = int(period.days)
day_list = []
for d in range(period):
day = start_date + datetime.timedelta(days=d)
day_list.append(day)
day_list.append(end_date)
return day_list
def make_doc_id_list(target_date):
securities_report_doc_list = []
params = {
"date" : target_date,
"type" : 2,
"Subscription-Key" : EDINET_KEY
}
time.sleep(10)
try:
res = requests.get(URL, params = params)
res.raise_for_status()
print(res.status_code)
json_data = res.json()
if json_data['metadata']['status'] != '200':
raise ApiResponseError('APIのステータスが200以外のレスポンスです')
for num in range(len(json_data["results"])):
securities_report_doc_list.append([
json_data['results'][num]['docID'],
json_data['results'][num]['edinetCode'],
json_data['results'][num]['secCode'],
json_data['results'][num]['JCN'],
json_data['results'][num]['filerName'],
json_data['results'][num]['fundCode'],
json_data['results'][num]['ordinanceCode'],
json_data['results'][num]['formCode'],
json_data['results'][num]['docTypeCode'],
json_data['results'][num]['periodStart'],
json_data['results'][num]['periodEnd'],
json_data['results'][num]['submitDateTime'],
json_data['results'][num]['docDescription'],
json_data['results'][num]['issuerEdinetCode'],
json_data['results'][num]['subjectEdinetCode'],
json_data['results'][num]['currentReportReason'],
json_data['results'][num]['parentDocID'],
json_data['results'][num]['opeDateTime'],
json_data['results'][num]['xbrlFlag'],
json_data['results'][num]['pdfFlag'],
json_data['results'][num]['csvFlag']
])
return securities_report_doc_list
except RequestException as e:
print("request failed. error=(%s)", e.response.text)
return securities_report_doc_list
except ApiResponseError as e:
print(e)
return securities_report_doc_list
また、HTTPレスポンスが200なのにAPI独自定義のレスポンスエラーについても対処するように書きました。例えば誤って未来の日付でRequestを送信すると、HTTPのレスポンスは200ですがResponse Bodyの中のstatusコードが404で応答します。JSONの['metadata']['status']を見て200で応答していないときは独自定義の例外が送出されるようにしました。
⑤APIから受け取った値をDBに格納する
DBはMySQLを使っているので、MySQLとやり取りするためのライブラリを使用します。今回はAWSのLambdaで使用実績のあるmysql-connector-pythonを使用します。
こちらの記事が参考になりました。
書き込み対象のデータはmake_doc_id_list()関数の戻り値をそのまま使います。
また、EDINETの書類情報については書類情報の洗い替え(更新)は想定しないので、同じ日に提出されたデータを再度取得した際は書き込みを無視します。そのため、docIdはPRIMARY KEYを付け、SQLではISNERT IGNOREを定義しました。
import mysql.connector as mydb
#環境変数
RDS_ENDPOINT = "*****.com"
password = "*****"
user = "*****"
def insert_list(doc_info_list):
# コネクションの作成
conn = mydb.connect(
host= RDS_ENDPOINT,
port='3306',
user=user,
password=password,
database='edinet')
with conn:
with conn.cursor() as cursor:
sql = """
INSERT IGNORE INTO document_list (docID, edinetCode, secCode, JCN, filerName, fundCode, ordinanceCode, formCode, docTypeCode, periodStart, periodEnd, submitDateTime, docDescription, issuerEdinetCode, subjectEdinetCode, currentReportReason, parentDocID, opeDateTime, xbrlFlag, pdfFlag, csvFlag)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);
"""
cursor.executemany(sql, doc_info_list)
conn.commit()これらのコードを組み合わせます。
import mysql.connector as mydb
import requests
from requests.exceptions import RequestException
import datetime
import time
EDINET_KEY = "ここにEDINET APIのキー"
URL = "https://disclosure.edinet-fsa.go.jp/api/v2/documents.json"
RDS_ENDPOINT = "*****.com"
password = "*****"
user = "*****"
class ApiResponseError(Exception):
pass
def make_day_list(start_date, end_date):
print("start_date:", start_date)
print("end_day:", end_date)
period = end_date - start_date
period = int(period.days)
day_list = []
for d in range(period):
day = start_date + datetime.timedelta(days=d)
day_list.append(day)
day_list.append(end_date)
return day_list
def make_doc_id_list(target_date):
securities_report_doc_list = []
params = {
"date" : target_date,
"type" : 2,
"Subscription-Key" : EDINET_KEY
}
time.sleep(10)
try:
res = requests.get(URL, params = params)
res.raise_for_status()
print(res.status_code)
json_data = res.json()
if json_data['metadata']['status'] != '200':
raise ApiResponseError('APIのステータスが200以外のレスポンスです')
for num in range(len(json_data["results"])):
securities_report_doc_list.append([
json_data['results'][num]['docID'],
json_data['results'][num]['edinetCode'],
json_data['results'][num]['secCode'],
json_data['results'][num]['JCN'],
json_data['results'][num]['filerName'],
json_data['results'][num]['fundCode'],
json_data['results'][num]['ordinanceCode'],
json_data['results'][num]['formCode'],
json_data['results'][num]['docTypeCode'],
json_data['results'][num]['periodStart'],
json_data['results'][num]['periodEnd'],
json_data['results'][num]['submitDateTime'],
json_data['results'][num]['docDescription'],
json_data['results'][num]['issuerEdinetCode'],
json_data['results'][num]['subjectEdinetCode'],
json_data['results'][num]['currentReportReason'],
json_data['results'][num]['parentDocID'],
json_data['results'][num]['opeDateTime'],
json_data['results'][num]['xbrlFlag'],
json_data['results'][num]['pdfFlag'],
json_data['results'][num]['csvFlag']
])
return securities_report_doc_list
except RequestException as e:
print("request failed. error=(%s)", e.response.text)
return securities_report_doc_list
except ApiResponseError as e:
print(e)
return securities_report_doc_list
def insert_list(doc_info_list):
# コネクションの作成
conn = mydb.connect(
host= RDS_ENDPOINT,
port='3306',
user=user,
password=password,
database='edinet')
with conn:
with conn.cursor() as cursor:
sql = """
INSERT IGNORE INTO document_list (docID, edinetCode, secCode, JCN, filerName, fundCode, ordinanceCode, formCode, docTypeCode, periodStart, periodEnd, submitDateTime, docDescription, issuerEdinetCode, subjectEdinetCode, currentReportReason, parentDocID, opeDateTime, xbrlFlag, pdfFlag, csvFlag)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);
"""
cursor.executemany(sql, doc_info_list)
conn.commit()
def main():
start_date = datetime.date(2022, 1, 1)
end_date = datetime.date(2022, 12, 31)
print(start_date.strftime('%Y%m%d'))
day_list = make_day_list(start_date, end_date)
for target_date in day_list:
print(target_date)
# 1日の有報を取得する
securities_report_doc_list = make_doc_id_list(target_date)
# print(securities_report_doc_list)
if len(securities_report_doc_list) > 0:
insert_list(securities_report_doc_list)
if __name__ == "__main__":
main()⑥コードを実行してデータが書き込まれることを確認する
このコードを実行して、データベースに書類情報が書き込まれたのを確認します。大体3年分くらいのデータを取り込みました。

有価証券報告書に限定して件数を確認します。EDINET APIの仕様書には付録でExcelファイルが添付されていて、書類の様式コード等の仕様が記載されています。これを参考に、府令コードが010、様式コードが030000の書類を確認します。

上場企業数は約4000社で、3年分だと12000件であればよいので、おおよそデータが取得できたのが分かります。
⑦今後の開発
今後は、このテーブルを使ってXBRLを取得するLambdaのアプリを作成予定です。例えば、このテーブルにXBRLのダウンロード歴を記録する列を作成し、未保存のデータを保存しにいく、というフレームワークを考えています。Lambdaは1度の実行が15分までという制約があるので、保存の有無をDBに記録するのが重要だと思っています。なので今回はRDSにEDINETの書類情報を保存しました。
XBRLデータを保存するAWSアプリケーションを作成したら、またnoteを更新したいと思います。