【R】JPXが公開している先物・オプションのデータを使ってRの練習をする①

データの保存
本来ならばPython等で自動収集したほうが早いですが、データ数が少ないので手動でDLします。

保存したEXCELファイルは、どこかにまとめて保管します。
データ集約デザイン
ありがたいことに、1日の中でも合計4種類のデータが存在します。これを1つのデータフレームに集約していきます。
例えば、各エクセルファイルが提供している表が1つのデータフレームだとすれば、
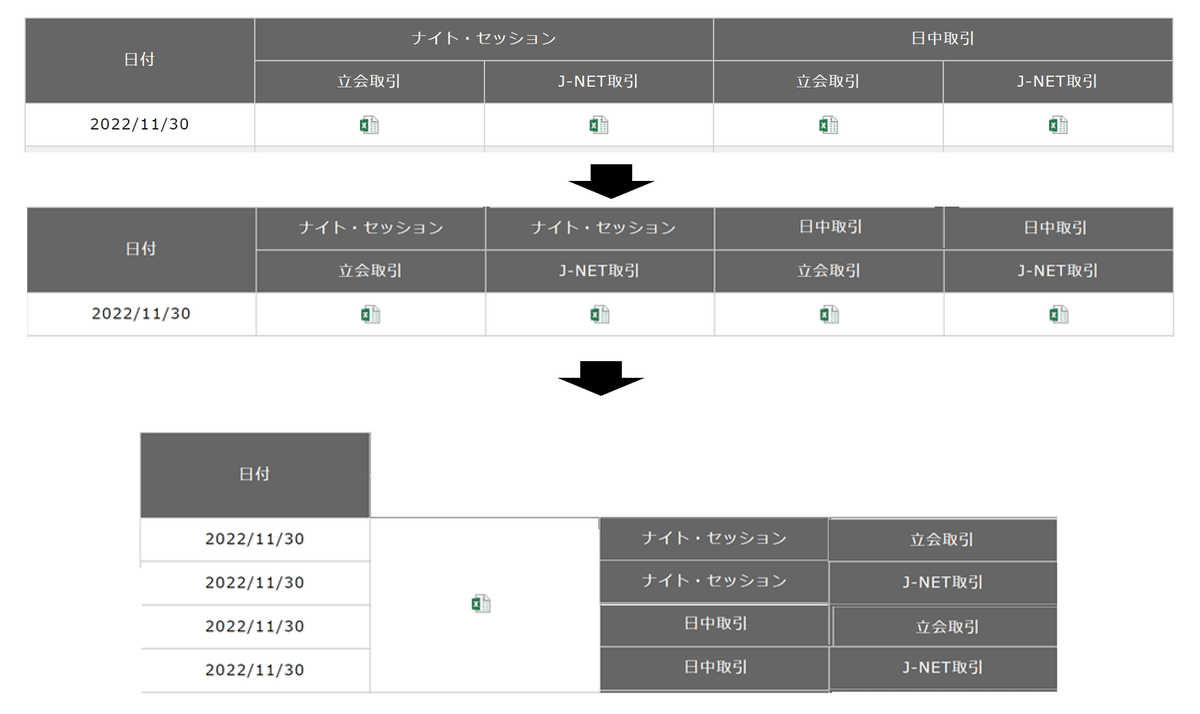
こんな感じのデータフレームになれば、見やすい気がします。
ここで、EXCELの中身を確認します。
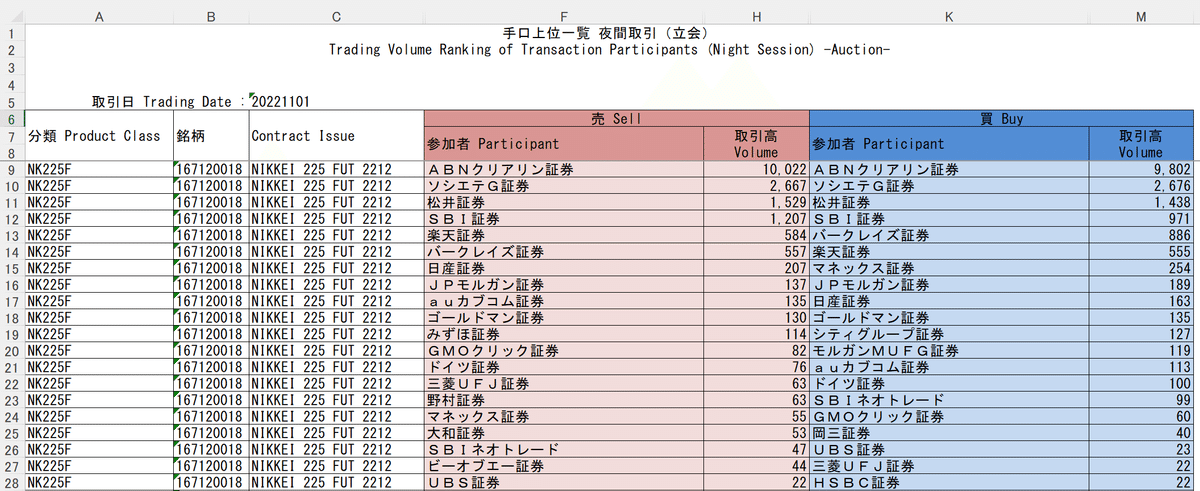
よく見ると、1行(1レコード)の中には買いと売りデータの2つが混同しています。
1行の中に異種情報があると後々分析に手間がかかってしまうので、買いデータ、売りデータは分けた方がよさそうです。
1行に含まれる取引情報について銘柄は一致しているので、1行分から{銘柄情報+買いデータ}、{銘柄情報+売りデータ}の2種類にデータを分けることができます。
たとえば、1行のデータは、次のように2行に分けることができます。

この作業を行えば、1行の中には1つの取引データだけが残るようになります。
EXCELにはナイトセッション、日中取引、立会取引、JNET取引の区別があることと、買いデータ+売りデータの2種類が存在することから、最終的なデータフレームの構造は、

という形になりそうです。
R出動
1.対象となる全EXCELファイルを探す
RでEXCELを呼び出すとき、通常は
library(readxl)
df_1 <- read_excel('no1.xlsx')
df_2 <- read_excel('no2.xlsx')
df_3 <- read_excel('no3.xlsx')
df_4 <- read_excel('no4.xlsx')
...というコードを書きます。ですが、ファイルが複数あるのに毎回ファイルを指定するのは大変です。そこで、指定したフォルダ内にあるエクセルデータの名前を聞く関数を利用して、1つのリストの中にファイル名を保管することにします。
excel_list <- list.files(pattern = "*.xlsx")
このexcel_listに入っているファイルごとにread_excelをかけていきます。
セル結合されたヘッダ(列名)付きのEXCELファイルの読込
ありがたいことに、提供されているEXCELは、列名セルが結合されています。例えば、参加者を示す列名は、E,F,G列、7行、8行目の計6マスを結合して表示しています。

人間の目には優しいですが機械には優しくないため、機械フレンドリーな方法でデータを読み込みます。その方法は、①8行目までは無視すること、②R側からは列名を指定しないこと、の2つの手順を踏みます。
つまり
df <- read_excel(filename, skip = 8, col_names = FALSE)というように、8行目までスキップし、1行目を列名に変換しないように指示するというわけです。列名を指定しないため、このデータフレームの列名は…1, …2, …3, ..という無機質な名前が与えられます。
ただ、列名が無いと後々分析が面倒になるので、新たな列名を与えます。
df <- read_excel(filename, skip = 8, col_names = FALSE) %>%
rename('ProductClass' = ...1) %>%
rename('TickNum' = ...2) %>%
rename('ContractIssue' = ...3) %>%
rename('SellVolRanking' = ...4) %>%
rename('SellParticipantID' = ...5) %>%
rename('SellParticipantNameJa' = ...6) %>%
rename('SellParticipantNameEn' = ...7) %>%
rename('SellVolume' = ...8) %>%
rename('BuyVolRanking' = ...9) %>%
rename('BuyParticipantID' = ...10) %>%
rename('BuyParticipantNameJa' = ...11) %>%
rename('BuyParticipantNameEn' = ...12) %>%
rename('BuyVolume' = ...13)もしかしたらc( )でまとめて改名できるかもしれません。
列名を変更した後のdfを確認します。ちゃんと名前が与えられているのが確認できました。

(次回に続く)