
【東証XBRL】業績修正に関する開示のXBRLについてのメモ(予想業績数値に上限・下限が設定されている場合)

週末に気付いたことを書き残すメモ程度の内容なので、あまりしっかりは書きません。
XBRLに関するネット記事の多くは金融庁(EDINET)から取得できる有価証券報告書ついて記載されているケースが多いです。今回の記事は特殊で、EDNETではなく東京証券取引所が提供する適時開示情報閲覧サービス(TDnet)から取得できるXBRLファイルの一部分に焦点を当てたメモを残そうと思います。
まず有価証券報告書と適時開示のXBRLの違いとして、若干のタグ表記に違いがあるようです。例えばXBRLのタグにコンテキストタグが利用されますが、東証XBRLはEDINETのXBRLとは違っています。
その違いの1つに、業績予想のタグが挙げられます。EDINETで公表される数値は決算後の一意な数字だと思いますが、東証XBRLで表現する業績予想は必ずしも1つの値ではなく、売上高の予想○○円~○○円という範囲を表現するケースがあることに気づきました。
四半期開示の廃止議論に代表されるように、短期的な目標数値の達成を避けるために、こうした業績目標に数値範囲を適用する企業は多いのかもしれません。
例えば2023年6月26日に開示されたサイジニア株式会社の業績予想に関する公表を見てみると、前回の業績予想では特定の値を示していましたが、修正後の数値はある程度数値の範囲を設けた予想になっています。
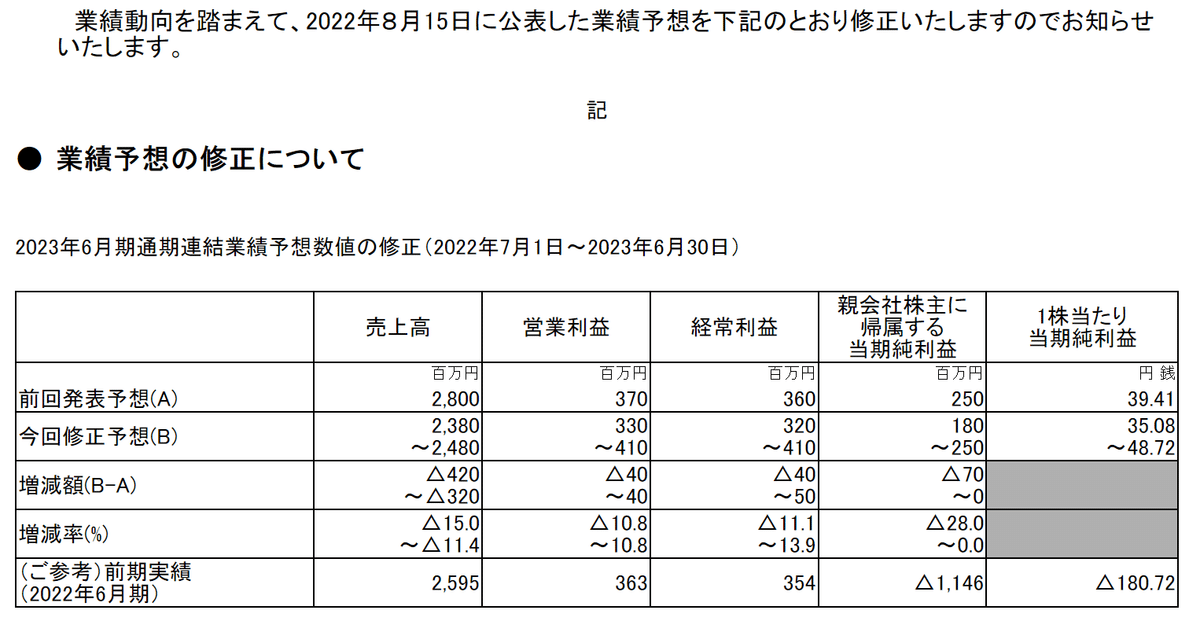
この開示には、①前回発表予想では一意な数字を示している分と②範囲を設けて数字を示している分、の2種類の要素があります。それぞれXBRL内ではどのように表現されているのでしょうか?以下のコードは、PythonでXBRLを解析して、主要な情報をCSV形式に落とし込むコードです。
from bs4 import BeautifulSoup
import pandas as pd
text_content = "インラインXBRLのテキストデータ"
soup = BeautifulSoup(text_content)
# https://qiita.com/XBRLJapan/items/d23bc251c53d81d49852
# タグの取り方はXBRL JapanさんのQiitaコードを参考にしています
tags = soup.find_all('ix:nonfraction')
record = []
for tag in tags:
contextref = tag.get('contextref')
decimals = tag.get('decimals')
name = tag.get('name')
unitref = tag.get('unitref')
# マイナス表記の場合の処理+円単位への変更
if "Shares" in unitref:
if len(tag.text) > 0:
amount = float(tag.text)
else:
amount = None
if tag.get('sign') == '-' and tag.get('xsi:nil') != 'true':
amount = float(tag.text.replace(',', '')) * -1 * 10 ** int(tag.get('scale'))
elif tag.get('xsi:nil') != 'true':
amount = float(tag.text.replace(',', '')) * 10 ** int(tag.get('scale'))
else:
amount = ''
record.append([contextref, decimals, name, unitref, amount])
df = pd.DataFrame(record,columns = ["contextRef", "decimals", "name", "unitRef", "value"])
df.to_csv("gyoseki_shusei_upper_lower.csv", encoding = "UTF-8")これでXBRLの中身をExcel上で確認することができます。
まず、①前回発表予想(一意な数字を示している部分)についてみてみます。ここは、コンテキストレフタグは_で次々と要素を足し合わせた状態になっています。
今年の、連結の、前回予想の、予想値、なので
CurrentYearDuration_ConsolidatedMember_PreviousMember_ForecastMemberのところに数値が入っているのが確認できます。nameには勘定科目、unitRefには数値単位が入っています。

次に②業績予想を数値範囲を持たせて開示しているパターンを見てみます。すると先ほどのコンテキストレフタグがCurrentYearDuration_ConsolidatedMember_CurrentMember_ForecastMemberのvalueが空白になり、代わりにCurrentYearDuration_ConsolidatedMember_CurrentMember_LowerMemberとCurrentYearDuration_ConsolidatedMember_CurrentMember_UpperMemberの2つに値が入っています。名前から推測できる通り、タグ名にLowerが付く要素には予想される業績の下限値、Upperが付く要素には業績の上限値が記載されていることが確認できます。

これは筆者の単なるぼやきですが、業績予想値の上限・下限ならば、コンテキストレフは命名規則的にはCurrentMember_ForecastLowerMember・CurrentMember_ForecastUpperMemberという名前にしてほしかったですね…(最初、UpperMemberとLowerMemberが示すものが何なのかわからなかった)。
今回は東証XBRLの要素をCSVに落とし込むコードと、その中で気付いたことと、ぼやきを残して〆たいと思います。ありがとうございました。