
スクレイピングで詰まっている件

Pythonを使った有価証券報告書の情報スクレイピングを始めてかなり経ちますが、壁にぶつかっては解決しての繰り返しです。
今はHTML化された有価証券報告書の中にある経営者情報、「役員の状況」の表をスクレイプしようと試行錯誤中です。この情報を1つのデータベースにすることで、経営者がどれほどの株式を持っていて、どのタイミングでどれほど保有数が変動しているのかを知ろうとしています。

これは、有価証券報告書内で経営者の情報をまとめた表です。この表では、役員の役職名、氏名、生年月日、略歴、任期、最後に所有株式数が示されています。
ある程度、各企業が開示すべき情報はこの様式に沿っているので、EDINETからダウンロードした有価証券報告書をプログラムに読ませるだけでデータが取得できるはずです。
では一体何が難しいのか?
①実は様式なんて決まっていない
この「役員の状況」欄、実は各社によって情報のまとめ方が異なります。
例えば下の図のように、役員のポジションを示す列が2つ存在します。上のカゴメ株式会社とは様式が異なっているのが分かります。

他にも、所有株式数の単位がバラバラになっているのも確認できます。下の企業では所有株式数は千株単位で、しかも全角数字で記載されているのが分かります。
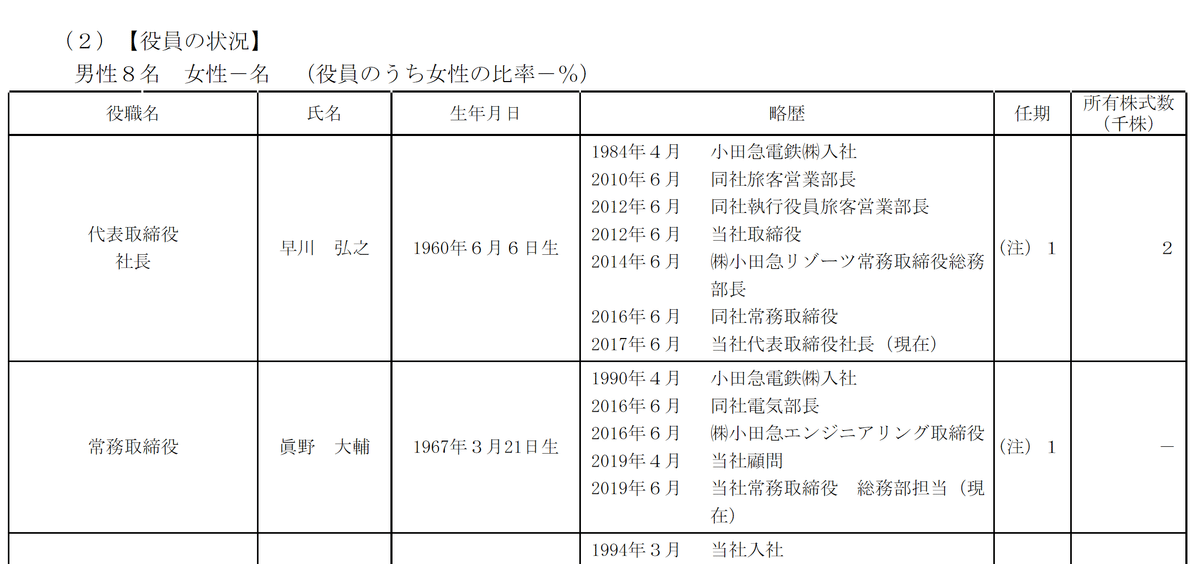
このような様式の違いがどれくらい存在するのかを調べるために、現在作成済みのコードで一旦スクレイプしてみました。まずは2019年に提出された有価証券報告書3263件のうち、エラーが出るまでテーブルを取得できた889件について確認します。
まずこの889社の役員の状況のうち、確認できたユニークなカラム様式は113件でした。つまり、表の様式がこの889社だけで113通り存在することになります。
ほとんどの企業が「役職名・氏名・生年月日・略歴・任期・所有株式数(株)」の様式で情報開示していますが、役員の氏名欄にフリガナや生年月日を併記したり、所有株式数の次にストックオプションの保有数を記載したり、さまざまな様式が存在します。
他にも文字と文字の間に半角・全角スペースが存在するなど、細かい違いも区別してしまうため、113通りという膨大なパターンが発生してしまいました。



プログラミングでデータを集約する際は、ある程度の規則性の基づいてプログラムを書きます。なのでこのようなイレギュラーがあるだけでデータベース作成にかなりの時間を要することになります。
②表の中に表が存在する(この様式だけ皆守ってる)
今回のプログラムでは、HTMLテーブルを取得するためにpandasのread_htmlを使用しています。報告書内のHTML内に存在するすべてのテーブルをいったん取得し、後からふるいにかけている、そんなイメージです。
しかし、厄介なことに実は役員の状況テーブルの中には実は二重でデーブルが存在します。
つまりどういうことかというと、
<table>
<tbody>
<tr>
・役職名
・氏名
・生年月日
<table>
・略歴
</table>
・任期
・保有株式数
</tr>
</tbody>
</table>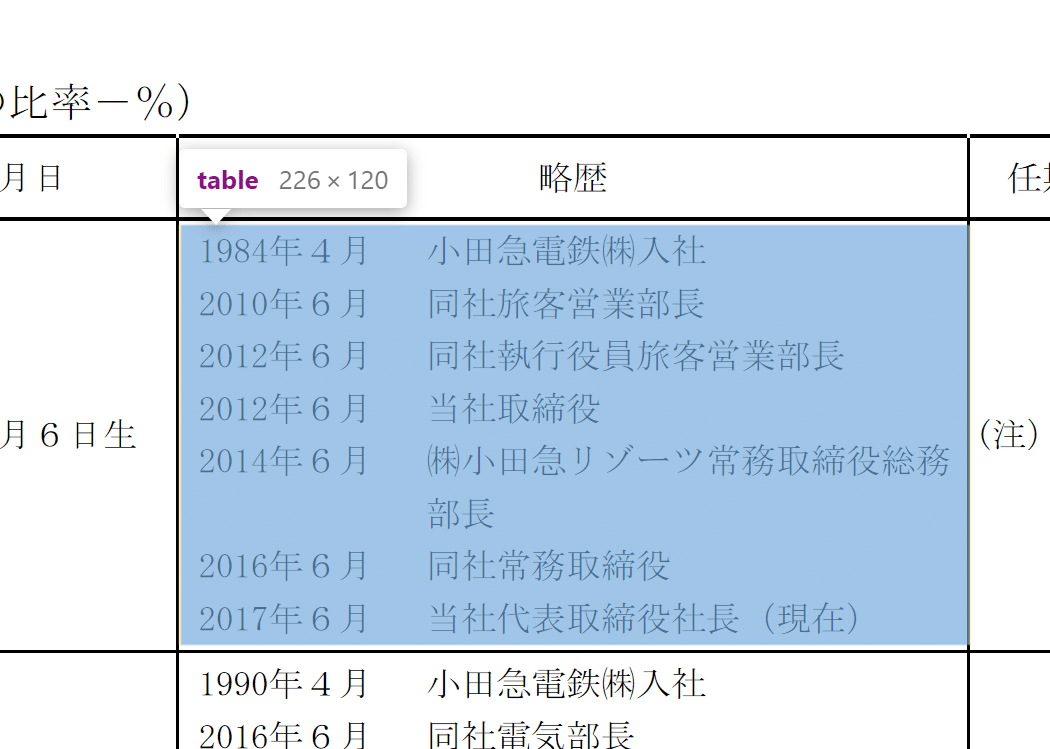
そう、略歴の項目だけ再度テーブルが作成されているのです。pandasのread_htmlはこうした二重のテーブルに対しては再度 別テーブルとして認識してしまうため、大変厄介です。
というのも、役員の状況テーブルは複数の表に分かれており(印刷時にページを跨ぐのを想定した仕様?)、想定では複数の「役員の状況テーブル」が格納されたリストを作成する予定でした。しかしながら、そのリストに格納した役員の状況テーブルとテーブルの間に各役員の略歴のみのテーブルが混入してしまうのです。イメージとしては、
◆◆理想のリスト(こうなると思ってた)◆◆
>>> for element in elements:
>>> officer_table = pd.read_html(str(element))
>>> officer_table_list.append(officer_table)
>>> print(officer_table_list)
[役員の状況table1ページ目, 役員の状況table2ページ目, 役員の状況テーブル3ページ目....]
◆◆実際のリスト(こうなってしまった)◆◆
>>> for element in elements:
>>> officer_table = pd.read_html(str(element))
>>> officer_table_list.append(officer_table)
>>> print(officer_table_list)
[役員の状況table1ページ目, 略歴, 略歴, 略歴, 略歴, 略歴, 役員の状況table2ページ目....]といった歪なリストが完成します。役員の状況だけを残したリストを作成するには、細かい条件分岐を設定してふるいにかけるしかありません。
③必ず株数を書いてくれているわけではない
今回のデータベース作成で最も重要なデータ要素の1つ、保有株式数ですが、すべての企業が「所有株式数」欄に数字だけを残してくれているわけではありません。
例えば、株式を所有していない役員の項目では、所有株式数の欄が 0 ではなく横線 - になっているケースが存在します。では、果たしてint型やfloat型で処理できないレコードは全て所有株式数を0株としてもよいのでしょうか…??
答えはNOです。
発行している株式が普通株式だけでなく、かつ役員が普通株式以外を保有している場合はその株式の種類を保有株式数欄に併記しているからです。
下の図で示した企業の場合は、普通株式以外にも株式が存在するため、値をintやfloatに変換するのが難しいです。そもそもこの書き方だと、保有しているのが普通株式なのか種類株式なのか、プログラムで判定するのは難しいです。

とりあえずこれから取り組むこと
どれだけデータの型に一貫性がなかろうが、何か解決策を考えて取り組むしかありません。
まずは、様式を一般化するところから始めようと思います。役名・職名に分けて表示しているところは、職名欄を捨てるか、役名・職名を連結することを検討します。半角・全角スペースが存在するところはstrip関数等を用いて適宜削除を試みます。また株式数の単位が異なるケースについては、千・百といった文字列がカラムに存在するかを判定し、その後一定倍数を掛けて1株単位で表記させる条件分岐を作成しようと思います。