
機械学習を部分的に理解してみた!

こんにちは!
ぷもんです。
前回、データセットのアヤメの品種を知るというnoteで
アヤメのデータセットの内容を見て
データセットの中身を見ることができるようになりました。
いよいよ機械学習をやっていこうと思うのですが
分類?、回帰?、決定木?など
よくわからん言葉が出てきて混乱してきたので
今回は機械学習の手法についてまとめたいと思います。
見つけたのがこのサイトです↓。
このサイトに載っていた画像がこちらです。

この画像を見て
「いやいやいや、、機械学習ってこんな多いん!?」
と衝撃を受けてしまいました。
でも、なんとか「無理や、、、。」
と思いそうになる自分をぐっと抑えました...笑。
このプログラミングを全然知らない状態で
機械学習のこれらの知識を独学で全てわかってから進むのは
あまりにも無謀なので
・アヤメのデータセットで試すことができそうなもの
・自分にもなんとか理解できそうなもの
から部分的に理解していこうと思います。
機械学習のうち
「教師あり/なし学習」、「強化学習」
さらに「教師あり学習」の中の「分類」と「回帰」
「教師なし学習」の「クラスタリング」と「アソシエーション分析」
「強化学習」に重点を置いてまとめます。
先ほどの画像の左のほうの大枠だけ理解する感じですね!
網羅性はないですが
僕自身もプログラミング初心者なので
プログラミングがわからない人にも理解できるような説明を心がけます!!
まずは「教師あり学習」についてです。
わかりやすくいうと
人間が正解のラベルをつけてそれを機械が学習する方法です。
前回書いたデータセットのアヤメの品種を知るでやったように
アヤメのデータセットにも
0=setosa、1=versicolor、2=virginicaのラベルがついていました。
このラベルを使って学習していくのが教師あり学習です。
一定のパフォーマンスを上げるようになった段階でゴールになります。
教師あり学習には「分類」と「回帰」の2種類があります。
分類とはカテゴリを分けることです。
画像を見てそれが猫なのか犬なのかを分類します。
回帰では今までのデータからあるものの数値を予想します。
今までの株価のデータから次の株価を予測するなどです。
教師なし学習は扱いやすく、正確にできますが
ラベルをつけるのが大変なのでコストがかかります。
続いて、「教師なし学習」についてです。
教師なし学習では正解のラベルがなくてもできます。
データの基本的な構造や分布をモデル化することができるとゴールになります。
教師なし学習には
「クラスタリング」と「アソシエーション分析」の二つがあります。
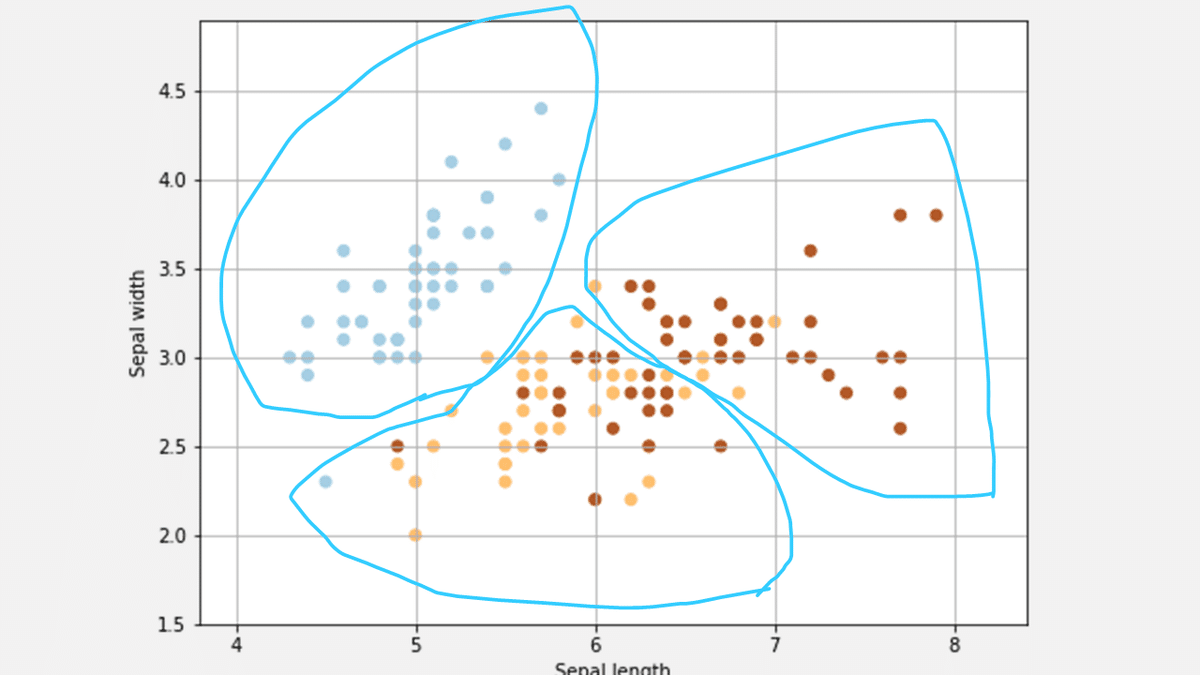
クラスタリングはデータから法則を見つけ出してグループ分けをしてくれます。
こちらのサイトの画像がイメージを掴みやすいと思います。
下のように法則性を見つけてグループ分けしています。
アソシエーション分析はデータの大部分のルールを知ることです。
アマゾンで買い物をした時に
「これもオススメです!」と出るのは
アソシエーション分析を使ったレコメンドシステムで行われています。
一部に正解がついていて
教師あり学習をして正解がついていないものでさらに教師なし学習をする
「半教師あり学習」というものもあります。
教師ありほど正確じゃないけど、教師なしより扱いやすいのが特徴です。
最後に「強化学習」についてです。
試行錯誤を繰り返して、与えられる価値を最大化していく方法です。
アルファ碁は強化学習でできていて
勝ちという報酬に向けて試行錯誤しながら最善手を見つけていきます。
株の予測、ロボットの制御、迷路探索などで使われます。
他にも、「決定木」「k近傍法」など聞いたことのある言葉はあったのですが
具体的な手法のようなので
実際にやりながら勉強していきます。
参考にした記事はこちらです!
最後まで読んでいただきありがとうございました。
ぷもんでした!
いいなと思ったら応援しよう!
