機械学習の回帰と分類の違いがやっとわかった!

こんにちは!
ぷもんです。
以前、アヤメのデータセットを使った機械学習完結!!学習して評価する
というnoteで機械学習の分類をやりました。
次は機械学習の回帰をやっていきます。
まず、今回は
・回帰とはなんなのか?
・回帰と分類の違いは何か?
について書きます。
回帰とは連続値の予想をすることのできる教師あり学習です。
教師あり学習とは正解のラベルと値のセットを使って学習する方法で
分類では
setosa、versicolor、virginicaのようなアヤメの品種(=正解のラベル)と
がく片の長さ、がく片の幅、花弁の長さ、花弁の幅(=値)を使いました。
回帰のポイントは連続値です。
株の今までのデータから連続値の流れを示す式を導き出すことで
続く値を予想する事ができます。
分類ではアヤメの値から
setosa、versicolor、virginicaの3つのグループに分けることはできても
値が連続値というわけではないですよね!
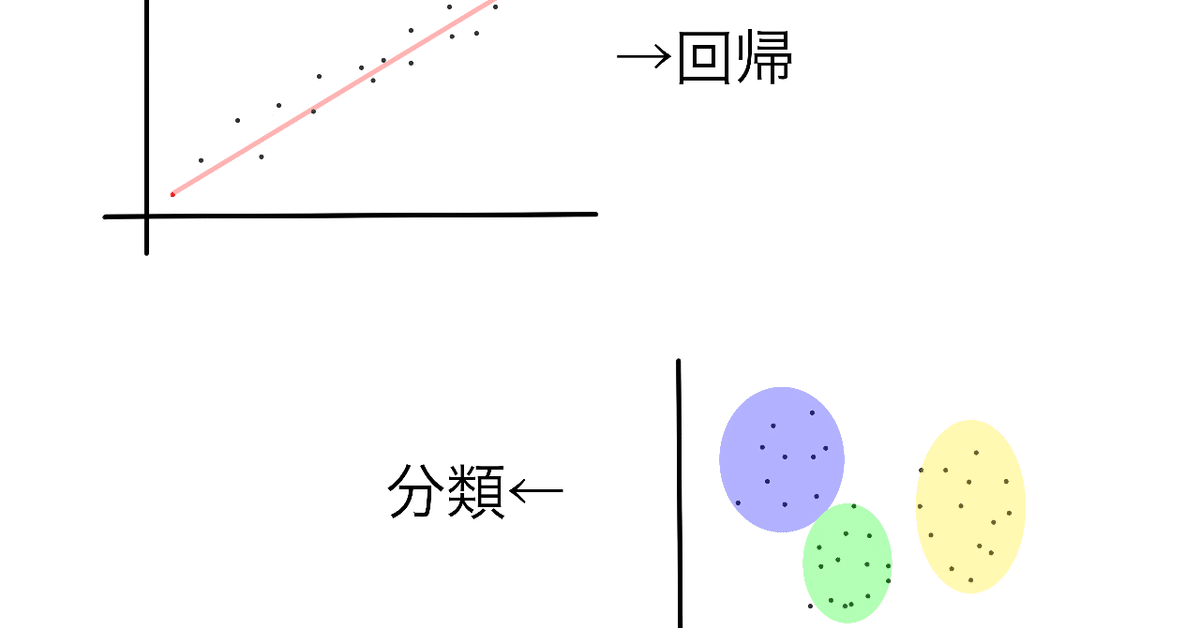
回帰は値から線(=連続値)を導き出す
分類は値からグループごとに分ける
イメージを持つと良さそうです。

このイメージが今までわかっていなくて
違いがよくわからずごちゃごちゃしていました。
次からはボストン市の住宅価格データのデータセットを使って
回帰をやっていこうと思います。
同じ教師あり学習の分類が少し理解できているので
同じ教師あり学習なのに回帰とどこが違うのか?
具体的な手法を見ながら理解していこうと思います。
最後まで読んでいただきありがとうございました。
ぷもんでした!
いいなと思ったら応援しよう!
