
ボトムアップの建築設計ツールとしての生成AI "京島LoRAプロジェクト"(2)

京島LoRAプロジェクト
築100年の木造長屋地域のリジェネラティブな郷土的建築文化の再発掘
生成AIを用いて建築や循環型社会を考えてみよう、という内容の国際コンペに応募した。
本記事では、プロジェクトのコンセプトから作業プロセスまで、生成AIで地域的建築を考えた軌跡の全容を紹介する。
3ページにわたって5章の内容を紹介する
プロジェクト概要 (p1)
最終成果物 (p1)
画像生成AIプロセス (p2)
詳細コンセプト (p3)
今後の展開 (p3)
3-1. 概念の生成

本章では、LoRAを用いた概念の生成について解説する。
本プロジェクトの要となってくるのがこのLoRA(追加学習)である。「京島っぽさ」という曖昧な集合的記憶を、AIが解釈し概念として構築していく。
3-1-1. 画像収集
まず始めに京島のフィールドワークを行った。住民になりきって、京島のいいところを撮り回っていく。
また共同作業者の森原は京島との繋がりがあるため、住民の方に案内してもらい家の中なども撮影させていただいた。
外観・内観・その他、合計で250枚ほど撮影した。その他は、水瓶やポストなど京島特有の風景や要素である。

アニメキャラなどの追加学習は10-20枚からでも高品質なものを作ることができる。しかし風景は対象が曖昧なため、もう少し多くの画像が必要だ。(アニメキャラや人物以外は全体的に情報が少なく、手探りで作業している)
今回の対象は風景で、さらに外観と内観の2要素を学習させる必要があるため、70枚程度学習させることにした。外観・内観・その他、合計で66枚まで絞った。

3-1-2. キーワード抽出
次に、画像からキーワードを抽出していく。これらはLoRAの学習に使うだけでなく、プロンプトの参考にすることもできる。
キーワード抽出に使える機能
Dataset Tag Editor
- 画像に含まれている単語を抽出する
- 文章は作れない
- 追加学習の際のタグとしても使用する
CLIP interrogator
- 画像からそれを生成可能なプロンプトを推測する
- 単語ではない
- image 2 prompt 2 image のように画像生成が出来る


例として、学習画像の中の1枚をこの2つの機能で解析してみる。

[dataset tag editor]
outdoors, day, tree, no_humans, window, plant, ground_vehicle, building, scenery, motor_vehicle, door, basket, potted_plant, road, house, street, bicycle, flower_pot, bicycle_basket
[dataset tag editor]
outdoors, day, tree, no_humans, window, plant, ground_vehicle, building, scenery, motor_vehicle, door, basket, potted_plant, road, house, street, bicycle, flower_pot, bicycle_basket
dataset tag editorは単語だけを、CLIP interrogatorは文章を抽出していることが分かる。後者はプロンプトにそのまま投げることが出来るのが便利。
dataset tag editorを用い、学習画像66枚から抽出した単語を、出現する頻度の高いもの順に並び替える。

ground_vehicle[31], power_lines[29], plant[28], utility_pole[23], bycycle[20], tree[20], potted_plant[18], motor_vehicle[16], air_conditioner[9], flower_pot[6], trash_can[4]
以上が京島の景観における特徴的な単語であろうか。
単語を抽出することで、京島のデザインコードを把握することが出来る。言語情報としてのデザインコードは、人間が街並みを理解するのにとても役立つ。従来の把握方法ながらとても強力である。
3-1-3. 追加学習(LoRA)
ここからは、AIのための非言語情報としてのデザインコードの構築を行っていく。Stable Diffusion の機能のひとつ、LoRA(追加学習)を作成する。


完成したLoRAモデルをwebuiで読み込み、今回のトリガーワードである“lora:kyojima:1 kyojima townscape” を入力すると、「京島っぽさ」を呼び出すことができる。
このようにして、AIが把握した「京島っぽさ」の概念が作られる。
3-1-4. 今回のLoRA評価
今回自作したLoRAには、「京島っぽさ」がかなり反映されていた。
京島の景観を形成している要素をいくつかあげてみる
- 植木鉢
- 溢れだす植物
- まばらな農場
- 狭い路地
- トタンの壁
- 瓦の屋根
- 低層の木造住宅
- 古いが修理されて使われているもの
- 電線と電柱

また、左は現実の写真で、右が生成写真である。この一枚からだけでも、様々な要素が抽出され反映されていることが分かる。
しかし、LoRAはとても深いブラックボックスの中にある。
使用する学習画像の数や質、LoRA作成時の数多くのパラメータ、画像と一緒に読み込ませるタグなど、様々な要因がLoRAの質を大きく左右する。アニメキャラなどに比べて難しく検証例も少ない建築や景観では、どのような設定が最適なのかはまだよく分からない。
3-2. 発散的な生成過程

LoRAを作り終わったので、いよいよ画像生成に取り掛かっていく。
画像を探索していくプロセスとして、発散的なものと収束的なものを分けた。ここではまず、生成AIの非制御的側面を利用した発散的生成プロセスから始めていく。起爆剤としてのAIである。
最終成果物の方向性を決めるために、とりあえずひたすら画像を生成していく。
ここで用いた機能
- text 2 image
- 特殊なプロンプト
- xyz plot
- prompts from file
3-2-1. 各設定
今回用いたプロンプトやパラメータの設定。この設定で、だいたい1枚10秒程度かかる。

今回の出力設定
wh: 1024 x 768
- 画像のサイズ, 今回はこれで固定
steps: 20~50
- 複雑度みたいなもの, 大きくししすぎると時間がかかる
cfg scale: 5~7
- プロンプトへの忠実度みたいなもの, 大きくしすぎると彩度やコントラストが高くなりすぎてしまう
seed: -1
- ランダムにおけるシード値, -1 は乱数, 非制御過程なので-1に
sampling method: DPM++ 2M Karras
- 画像生成方法みたいなもの, 色々あるが、とりあえずこれが無難
checkpoint model: Realistic Vision V2.0
- 画像生成のもととなる学習モデル, 今回はリアル系のものを使用
LoRA: kyojima
- 特徴を指定するための追加学習モデル, 自作の京島LoRAを使用
<lora:kyojima:0.95> kyojima townscape,
detailed photo of people in (farm:1.3) and buildings,
collective housing, wood, table, [glass], sunny, blue sky, (flowerpot)
negative: blurry, low qualityプロンプトの意味
<lora:kyojima:0.95>
- stable diffusion内にLoRAを呼び出す
- 0.95はLoRAの重み、どのくらい出力に影響を与えるか
“kyojima townscape”
- 京島LoRA作成時に設定したトリガーワード
- これが抜けているとLoRAが働かない
“detailed photo of people in (farm:1.21) and buildings”
- メインのプロンプト
- 何の画像を生成したいのか
“collective housing, wood, table, [glass], sunny, blue sky, (flowerpot)”
- サブのプロンプト
- 画像に反映させたい要素
(…), (…:1.3), […]
- 特殊構文のひとつ、重み
- (…)=1.1倍、((…))=1.1x1.1=1.21倍、のように中身の影響力を強める
- […]=0.9倍、[[…]]=0.9x0.9=0.81倍、のように中身の影響力を弱める
- (…:1.3)のように数値を指定することも出来る
- 今回は、”farm”や”flowerpot”を強め”glass”を弱めた
negative: “blurry, low quality”
- ネガティブプロンプト(下の欄)
- 反映させたくない要素
プロンプトに従ってランダムに画像が生成されていく。batch countを調整し、複数枚一気に出力していく。

3-2-2. 発散的画像生成
プロンプトやパラメータの設定はおおよそ決まったので、ここからは一気に生成していく。無数の画像を自動で作れるという生成AIのひとつの長所を最大限活用する。
今回はこの発散的過程で2500枚程度出力した。
一気に生成する方法はいくつかある
batch count
- 生成枚数を増やす、単純な方法
- デフォルトは100が上限だが、設定ファイルを弄れば無限に生成できる
xyz plot
- プロンプトやパラメータを各軸に並べて、表を作る
- それらを比較できるので、方向性を絞っていきやすい
prompts from textfile
- .txt としてプロンプトを複数作っておきそれを読み込ませる
- pythonやchatgptなどとも合わせやすい
dynamic prompt
- プロンプトの並列記述やランダム処理ができる
今回はxyz plotを使用する。プロンプトやパラメータをx軸y軸に並べて表をつくるもの。
各軸の要素には様々なものを設定できるが、ここではまだ何が作りたいかを探索する段階なので、ワードにしておく。

<lora:kyojima:0.95> kyojima townscape,
detailed photo of people in (farm:1.3) and buildings,
house, water, [glass], sunny, blue sky, (flowerpot)xyz plot:
X type: Prompt S/R
X values: house, cafe, cafeteria, bookstore, market, design atelier, small factory, small school, kindergarten, gallery
Y type: Prompt S/R
Y values: water, plants, park, parking lot, small street, apple trees, animals, bicycle, large market, tower
Z type: Nothingこのようにxyz plotを設定する。
これはプロンプトの”house”をcafe, cafeteria, market…に、”water”をplants, park, parkin lot…へと置き換えていくものである。

自分の環境では、10x10=100枚を生成するのにだいたい30分かかった。寝ている間に10x10x10=1000枚生成させたりもした。
3-2-3. 自作LoRAとの対話
生成AIはブラックボックスがとても大きいツールである。だからこそ、良い画像を作るためには手探りでその特性を把握していく必要がある。
前節では、かなり自由に大量の画像を生成した。ここでは、生成AIをいい方向に導くための探索をしていく。ある種のAIとの対話である
分かりやすい例をあげてみる
<lora:kyojima:0.95> kyojima townscape,
detailed photo of people in farm and buildings,
narrow street, [glass], sunny, blue sky, (flowerpot)
上のプロンプトで出力した画像はこの4枚のようなものであった。
自分は家と農地が隣り合った風景を作りたかったのに、なかなか農地があらわれない。
<lora:kyojima:0.95> kyojima townscape,
detailed photo of people in (farm:1.4) and buildings,
narrow street, [glass], sunny, blue sky, (flowerpot)
そこで、”farm” を ”(farm:1.4)” に上げてみる。農地がかなり出てきた。
画像生成AIには言葉同士の相性があるらしい。
机の上に林檎を置くのは簡単だが、ダンプカーを置くのは少し努力がいるといった風に。特に、自作LoRAはこの相性が顕著に現れる気がする。(自作にもコツがあるが難しい)
今回のプロジェクトを通して、この相性や出しやすさの把握、「対話」に最も時間をかけた



「対話」のために調整したいプロンプトやパラメータ
LoRAの重み
- <lora:kyojima:0.95>の数値の部分
- 「京島っぽさ」を重視しすぎると柔軟な画像を出しにくくなることも
プロンプトの重み
- (farm:1.4) などの括弧構文
- 重視したい要素につけてみる
- 出しやすいワードと出しにくいワードがあるので、同じくらい重視したい場合でも、出しにくい方にだけ1.5くらいつける場合も多い
プロンプトの相性
- 言葉の相性
- 出しやすさ、出しにくさ
プロンプトの順番
- 基本的に前にあるワードのほうが反映されやすい
プロンプトの書き方
- “photo of people in farm”と”photo of farm, people” では結果はそれなりに違ってくる
- 何がメインになるのかなどを意識して書き換えていく
長いプロンプト
- アニメ系の人たちが書いているような長いプロンプトはとても参考になる
- しかし長いプロンプトが必ずしも良いというわけではない
- 今回の自作LoRAでは相性が悪く、あまり長いプロンプトは使わなかった
3-2-4. 方向性の決定
大量の生成画像から良い画像をピックアップしていく。最終成果物の方向性を絞っていく。


この時点ではまだ方向性は定まっていない。
外観、内観、路地それぞれ20枚ずつくらいの様々な画像がある。
ここまでが発散的プロセスである。
ここからは収束へと向かう制御プロセスに入っていく。
3-3. 収束的な生成過程

生成AIには制御可能性と制御不可能性が共存している。
基本的な画像生成手法では、プロンプトを用いることである程度方向性を制御できるが、最終的な出力をコントロールはできない。最後はAIに任せるしかないのである。
一度人間の手から離しブラックボックスを介して出力に変換するという生成AIは、Rhinoceros や Photoshop とは全く異なるツールであり、それが大きな長所にも短所にもなりうる。
これまで、発散的な手法で大量の画像を生成してきた。
ここからは、最終成果物の1枚に収束させるための制御のプロセスに入る。
もちろん、photoshopなどを含め、他のソフトは一切使わない。
Stable Diffusionは他の画像生成AIと異なり、制御可能性にもとても優れている。いくつかの拡張機能を用いた収束プロセスを考えていく。
収束的画像生成で用いる機能
- text 2 image
- seed variation
- png info
- control net
- cutoff, latent cupple
- inpaint, outpaint
- hires.fix, loopback scaler
3-3-1. 収束的画像生成
ここでは外観写真の生成過程を例に、収束プロセスを見ていく。
2-2-4.で絞った画像について、miro上でディスカッションをした。

ここでの評価軸はこのようなものであった
1. 単純に美しく目を惹かれるもの
2. 良い構図
3. 従来の建築とは異なる、生成AIならではの意外性が見えるもの
4. 「京島っぽさ」が残りつつ、新たな循環型社会に対応しているもの
逆に悪い部分でも評価対象には入れない要素がいくつかあった
1. 構造面での非現実性
2. 人間の崩れ
3. 一部分だけかなり良くない、残念な部分
4. 物や植物の多い少ない
特に3,4はこの後いくらでも直せるので、何の問題もない
まとめると、良い構図やコンセプトのものは高く評価し、一部分の残念な箇所はこれから直していくという方針である。
話し合いから、この3枚の候補に絞り込んだ
16 → 3枚への絞り込みである

ここからは、この3枚をもとにヴァリエーションを生成していく。
このヴァリエーション生成が、収束的生成プロセスの主な手法の一つである。ここでの重要な概念がseedである。

seed
- プログラミングにおいて乱数生成時に使用される十桁程度の整数。同じseedを入力すると、同じ結果が返ってくる
- 画像生成AIでも、同じ生成条件下で同じseedを用いると全く同じ画像が生成される
- stable ddifusionではデフォルトは乱数を意味する-1
- seedが少しずれると画像も少しだけ変化する
seed variation
- seedを少しずつずらした画像を生成する機能
- variation strength の値が大きいほどseedが大きく変わる=画像が大きく変わる
variation seed
- ヴァリエーションを生成したときに使用されたseed
候補画像1枚目のヴァリエーションを生成。
全く同じ生成条件にしなければ元画像と似たものにはならないため、プロンプトとseedは全く同じものを使用。
元画像と少しずつ異なっているのが分かる。
<lora:kyojima:0.95> kyojima townscape,
photo of people in (farm:1.21) and buildings,
collective housing, wood, table, [plants], sunny, blue sky
seed: 4088372307
variation seed: -1
variation strength: 0.13
生成画像のプロンプトやseedなど各パラメータを確認するためには、PNG Infoを使う。この条件でまた生成を行いたい場合は、send to txt2imgを押すと情報を送ってくれる。

候補1の画像のヴァリエーションから4枚の画像に絞り込む

このように、同じ要素や配置をもとにヴァリエーションを作っていきたい場合は、seed variation がとても有用である。
3-3-2. Control Net
強力な構図指定方法にcontrol netがある。
画像生成AIの最も重要な機能のひとつである。

Control Net
- 輪郭や深度などから画像の構図を指定する(輪郭、落書き、深度、セグメンテーション、骨格などから)
- 構図を強制した上で、プロンプトに従った画像を生成してくれる
- 色々なパラメータで、強度や推測力などを調整できる
- 生成時間は2,3倍ほどになる
3-2-4. で絞った外観画像にcontrol netを使ってみる


ここではMLSDという直線の輪郭を拾ってくれるモデルを使用した。
抽出した線をもとに、プロンプトの通りに再構成してくれる。
seed variationはプロンプトはほとんど変えられなかったが、control netの場合は変更できるのが大きな強みである。新たな要素を追加してヴァリエーションを作りたいときに助かる。
今回のプロジェクトでは、最終的にはcontrol netは使用しなかった。
途中の収束過程で何回か使用した程度で、ほとんどseed variationに頼った。
3-3-3. その他の制御手法
他にもさまざまな制御機能がある
cutoff は修飾するワードを切り離し、混ざりを避けるための拡張機能である。
”blue wall, white door”と入力しても、基本的には青い壁と白いドアがはっきり分かれて出力されることは少ない。
cutoffを用いることで、ある程度分離させることができる。
<lora:kyojima:0.85> kyojima townscape,
photo of people in (farm:1.21) and buildings,
blue wall, white door, narrow street, sunny
cutoff
target tokens: blue, white
weight: 1.2

確かに、青い壁と白いドアが区別されている画像は出力された。
しかし、上手く生成される確率はあまり高くなく、より多くの要素を区別するよう制御するのはなかなか難しい。
今回のプロジェクトでは結局使わなかった。
複数の要素を切り離して混ざらないように制御する拡張機能には、latent couple などもある。
このように、拡張機能が日々増えていくStable Diffusionでは、さまざまな制御手法が生み出されていく。cutoff や latent couple はそのような波の一つである。
ここまでが収束的な生成過程のループである。
最良の1枚を選んだら、最終調整に入る。
3-3-4. 最終調整
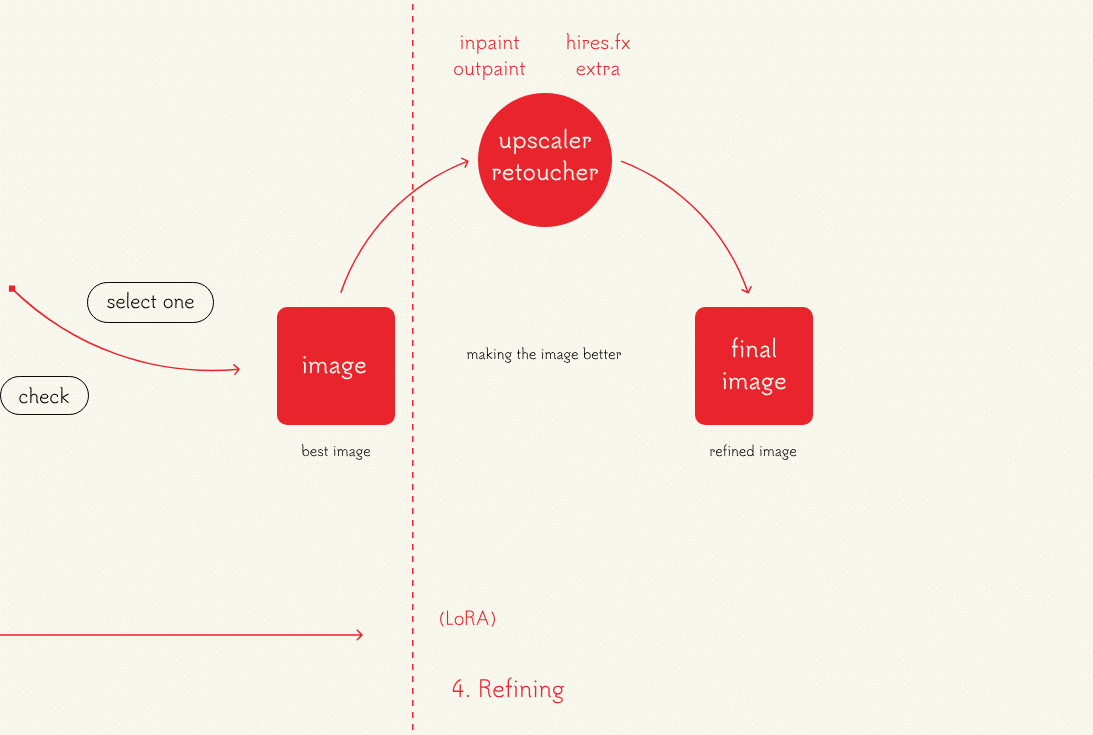
最終調整では、解像度を上げたり一部分を修正したりする。
先ほどまでとは異なり、ループを回す作業ではない。
主な機能
画像の一部修正
- inpaint
- outpaint
アップスケーラー
- extra
- hires.fix
- loopback scaler
- multi diffusion
このように最後の一枚を洗練させて全工程は終了となる。
3-4. 最終成果物
この工程を経て、最終的に生成したものを紹介する。








I would be very happy if you gave me coffee!!
この記事が気に入ったらサポートをしてみませんか?