
SITUATIONAL AWARENESS AIアライメント、AI倫理、哲学野観点から人類史を俯瞰する。スターゲート計画は悪か?善か?

嘘つきで詐欺師のAGI を誕生させたら、人類滅亡まで行く可能性があるAI倫理課題
— 山下安音 (@SelfRetreat12) January 27, 2025
教え込む側の人間存在が嘘つきで詐欺師であったら、AG I開発を委ねるのは間違いではありませんか? https://t.co/LnWFyjFlwA
この動画は、AI開発におけるオープンソースとクローズソースの対立、特にOpenAIの事例を通して、アメリカと中国の技術競争と経済政策の現状を分析しています。さらに、日本の自動車産業の現状や、中央銀行デジタル通貨の導入に関するリスク、そして日本の官僚主義と政府予算の不正使用問題といった、国際情勢と国内問題を絡めて論じています。 特に、トランプ前大統領の政策やイーロン・マスク氏の言動も引用され、現状への批判と将来への懸念が表明されています。 最後に、これらの問題を解決するための提案として、情報公開とシステム改革の必要性が強調されています。
2つの動画、「人類の倫理講座へようこそ (1).mp4」と「人類の倫理講座へようこそ (2).mp4」からの抜粋は、アメリカ合衆国の政治・経済状況、特にトランプ政権とバイデン政権の政策、そしてウクライナ紛争とAI開発の現状について、独自の視点で解説している。 (1)では、ウクライナ紛争の背景やアメリカの介入、生物兵器開発疑惑、そして国際社会の対応に焦点を当て、(2)では、AI開発におけるオープンソースとクローズソースの対立、アメリカの経済的衰退、そして日本の官僚主義と腐敗の問題を論じている。 両動画とも、国際情勢と国家運営における倫理的な課題を提起し、視聴者へ警鐘を鳴らす内容となっている。
AIが悪用させない。ロスアラモス国立研究所とOpenAIが共同研究
— 山下安音 (@SelfRetreat12) January 27, 2025
https://t.co/y8OHwcpar1
オープンAI、内部告発者、イリア氏の著作権法違反を指摘する
— 山下安音 (@SelfRetreat12) January 27, 2025
資料https://t.co/sSfPPkjvTx
— 山下安音 (@SelfRetreat12) January 27, 2025
【勉強会での資料】 Stargate Project
解説スライド https://x.gd/4maA5
SITUATIONAL AWARENESS https://x.gd/qxhJ0
Ilya: the AI scientist shaping the world (イリヤ・サツケバー氏動画) https://x.gd/VcegY
丸山 隆一 (Ryuichi Maruyama) - 資料公開 - researchmap https://x.gd/F3Ebl Dario Amodei — Machines of Loving Grace https://x.gd/rglWG
ヴィタリック・ブテリン氏の「d/acc」構想の概略 (Genspark) https://x.gd/lgtFT
【レジメ】 https://x.gd/nTWMS
元アメリカ空軍の研究者マイカ・エンズリーによれば、シチュエーションアウェアネスは次の3つのレベルに分かれるとされる:
SITUATIONAL Awareness(状況認識)について、AIアライメント(AIの目標と人間の価値観の一致)の立場から見たリスクは以下の通りです:
1. 誤った状況認識による誤解
AIが状況を正確に認識できず、誤った判断を下す可能性があります。これは特に、複雑な社会的または倫理的な問題を扱う際に顕著です。例えば、AIが特定の文化的背景や文脈を理解せず、適切でない行動を取ることが考えられます。
2. 信頼性の低下
AIが状況を誤って解釈したり、適切な反応を示せない場合、ユーザーや社会全体のAIに対する信頼が低下します。これは、AIが重要な意思決定に参加する場面で特に問題となります。信頼の低下は、AIの利用拡大や新しい技術の導入を阻害する可能性があります。
3. 安全性の問題
AIが正確な状況認識を持たない場合、安全性に直接影響を与えることがあります。例えば、自動運転車が交通状況を誤解した場合、事故のリスクが増大します。また、医療診断AIが患者の症状や背景を正確に理解できず、誤診を引き起こす可能性もあります。
4. 道徳的・倫理的なジレンマ
AIが特定の状況を理解し、適切な倫理的な判断を下すことができない場合、道徳的な問題が発生します。例えば、AIが人間の価値観や倫理に基づく決定をする際に、どの行動が「正しい」かを判断する基準が曖昧になることがあります。
5. 戦略的リスク
状況認識の欠如は、AIが戦略的または長期的な目標を達成する能力に影響を与えます。例えば、ビジネスAIが市場の動向や競争状況を正しく理解できないと、企業戦略に悪影響を及ぼす可能性があります。
6. 偏見と不公平
AIが訓練データから学ぶ過程で、そのデータが偏っていると、状況認識自体が偏見を含むものになるリスクがあります。これは、AIが特定のグループに対して不公平な判断を下す原因となるかもしれません。
対策
多様なデータセットの使用: AIのトレーニングデータが多様であることを確保することで、より広範な状況認識が可能になります。
人間との協働: AIの判断プロセスに人間が関与し、AIの理解を補完または修正することが重要です。
透明性と説明責任: AIの意思決定プロセスを透明にし、なぜそのような判断が下されたのかを説明できるようにすることで、誤解や不信を防ぎます。
継続的な学習: AIが新しい状況や環境から学び続けるシステムを持つことで、状況認識の精度を向上させることができます。
これらのリスクを理解し、対策を講じることで、AIアライメントの目標に向けた進歩を促進できます。
SITUATIONAL AWARENESSについての論文は、さまざまな分野や研究者によって数多く出版されていますが、ここではいくつかの主要な論文や資料を紹介します:
Leopold Aschenbrennerの"SITUATIONAL AWARENESS: The Decade Ahead"
この論文は、AIの進歩とその社会的、経済的、軍事的影響について詳細に論じています。特にサンフランシスコを拠点とする技術者や研究者の視点から、AIの未来とその潜在的な影響を予測しています。この論文は、AIがどのように人間の知能を超える可能性があるか、またそれがもたらす地政学的影響についても触れています。
Situation Awareness in AI-Based Technologies and Multimodal Systems
この論文は、状況認識(SA)がどのようにAI技術やマルチモーダルシステムに組み込まれるかについて概説しています。研究では、AIがデータ融合、表現、分類、予測というタスクを通じてSAを強化する方法を探求しています。
Situation awareness - Wikipedia
状況認識の概念についての基本的な情報や歴史的背景を提供しています。特に、Endsleyの状況認識理論に基づく3つのレベル(知覚、理解、予測)について詳述しています。
シチュエーションアウェアネス - Wikipedia (Japanese)
日本語で状況認識の概要が記載されています。軍事から自動運転まで、広範な応用分野での重要性が説明されています。
これらの論文や資料は、状況認識の理論、アプリケーション、そしてAIの進化との相互作用について理解を深める助けとなります。論文そのものへの直接アクセスは通常、学術データベースや出版元のウェブサイトを通じて行うことができますが、ここでは関連する情報源を紹介しています。
これからの10年
II. AGIから超知能へ:知能爆発
AIの進歩は人間レベルにとどまりません。何億ものAGIがAI研究を自動化し、10年間のアルゴリズムの進歩(5+ OOM)を≤1年に圧縮することができます。私たちは、人間レベルから超人的なAIシステムへと急速に移行するでしょう。超知能の力と危険性は劇的なものになるだろう。
この作品の内容:
超知能機械とは、どんなに賢い人間のすべての知的活動をはるかに凌駕できる機械と定義しよう。機械の設計はこれらの知的活動の一つであるため、超知能機械はさらに優れた機械を設計することができます。そうなれば、間違いなく「知能爆発」が起こり、人間の知性ははるか後ろに取り残されるでしょう。したがって、最初の超知能機械は、人間が作る必要のある最後の発明です。
爆弾とスーパー
一般的な想像では、冷戦の恐怖は主に原子爆弾の発明によるロスアラモスにまでさかのぼります。しかし、『ザ・ボム』だけでは、おそらく過大評価されているのだろう。「原爆」から「スーパー」への移行、つまり水素爆弾への移行も、ほぼ間違いなく同じくらい重要だった。
東京大空襲では、数百機の爆撃機が数千トンの通常爆弾を東京に投下した。その年の後半、広島に投下されたリトルボーイは、同様の破壊力を一つの装置で解き放った。しかし、そのわずか7年後、テラーの水素爆弾は再び1000倍にも膨れ上がり、第二次世界大戦中に投下されたすべての爆弾を合わせたよりも爆発力のある爆弾1つとなった。
爆弾は、より効率的な爆撃作戦であった。スーパーは国を壊滅させる装置でした。
つまり、AGIとSuperintelligenceもそうです。
AIの進歩は人間レベルにとどまりません。最初に最高の人間のゲームから学んだ後、AlphaGoは自分自身と対戦し始め、すぐに超人的になり、人間が思いつかない非常に創造的で複雑な動きをしました。
AGIへの道筋については、前回の記事で説明しました。汎用人工知能を手に入れたら、もう1回、あるいは2回、3回とクランクを回すと、AIシステムは超人的、つまり非常に超人的なものになります。彼らはあなたや私よりも質的に賢くなり、おそらくあなたや私が小学生よりも質的に賢くなるのと同じように、はるかに賢くなるでしょう。
超知能への飛躍は、現在の急速かつ継続的なAIの進歩の速さで十分にワイルドなものになるでしょう(GPT-4から4年後にAGIに飛躍できるとしたら、その4年または8年後に何が起こるのでしょうか?しかし、AGIがAI研究自体を自動化するのであれば、それよりもはるかに高速になる可能性があります。
AGIを手に入れたら、AGIは1つだけではありません。数字については後で説明しますが、それまでに推論GPUフリートがあることを考えると、数百万のフリートを実行できる可能性があります(おそらく1億人で、その後すぐに10倍+の人間の速度で)。まだオフィスを歩き回ったり、コーヒーを淹れたりできなくても、コンピューターでMLの研究を行うことができます。主要なAIラボに数百人の研究者やエンジニアがいるのではなく、その10万人以上が昼夜を問わずアルゴリズムのブレークスルーに猛烈に取り組んでいることになります。はい、再帰的な自己改善ですが、SFは必要ありません。アルゴリズムの進歩の既存のトレンドライン(現在~0.5 OOMs/年)を加速するだけでよいのです。

自動化されたAI研究は、おそらく人間の10年分のアルゴリズムの進歩を1年未満に圧縮できるでしょう(そしてそれは控えめに思えます)。それは、AGIの上に、GPT-2からGPT-4への別のサイズのジャンプである5+ OOMSであり、未就学児から賢い高校生への質的なジャンプであり、すでに専門のAI研究者/エンジニアと同じくらい賢いAIシステムの上にジャンプします。
実験のための計算が限られていること、人間との相補性、アルゴリズムの進歩が難しくなっていることなど、いくつかのもっともらしいボトルネックがありますが、これについては後で説明するつもりですが、物事を決定的に遅らせるのに十分なものはないようです。
いつの間にか、私たちは超知能を手に入れているでしょう - 人間よりもはるかに賢いAIシステム、私たちが理解し始めることさえできないような斬新で創造的で複雑な行動をとることができる - おそらく何十億人もの小さな文明さえも。彼らの力もまた、莫大なものになるだろう。超知能を他の分野の研究開発に応用すれば、爆発的な進歩は単なるML研究から広がるだろう。やがて彼らはロボット工学を解決し、数年以内に他の科学技術分野を飛躍的に飛躍させ、産業爆発が続くでしょう。超知能は、おそらく決定的な軍事的優位性を提供し、計り知れない破壊力を解き放つだろう。私たちは、人類の歴史の中で最も激しく、不安定な瞬間の一つに直面することになるでしょう。
AI研究の自動化
すべてを自動化する必要はなく、AIの研究だけを自動化する必要があります。AGIの変革的な影響に対する一般的な反対意見は、AIがすべてをこなすのは難しいというものです。例えば、ロボット工学を見てみて、懐疑的な人は言う。これは、AIが認知的に博士号のレベルにあるとしても、厄介な問題になるでしょう。あるいは、生物学の研究開発の自動化を例にとってみれば、それには多くの物理的な実験室での作業や人体実験が必要になるかもしれません。
しかし、AIがAIの研究を自動化するためには、ロボット工学は必要ないし、多くのものも必要ない。主要な研究所のAI研究者やエンジニアの仕事は、完全に仮想的に行うことができ、同じように現実世界のボトルネックに遭遇することはありません(ただし、コンピューティングによって制限されますが、これについては後で説明します)。そして、AI研究者の仕事は、大まかに言えば、MLの文献を読んで新しい質問やアイデアを考え出し、それらのアイデアをテストするための実験を実施し、結果を解釈し、繰り返すという、非常に単純なものです。これはすべて、現在のAI能力を単純に外挿するだけで、2027年末までに最高の人間のレベルに簡単に到達できる、またはそれを超えることができる領域に真っ向から取り組んでいるように思われます。
「ああ、正規化を追加するだけだ」(LayerNorm/BatchNorm)、「f(x)+xの代わりにf(x)+xを実行」(残差接続)、「実装バグを修正する」(Kaplan → Chinchillaスケーリング法)など、過去10年間の最大の機械学習のブレークスルーのいくつかがいかに単純でハッケーであったかを強調する価値があります。AI研究は自動化できます。そして、AI研究を自動化するだけで、並外れたフィードバックループが始まります。
自動化されたAI研究者のコピーを何百万も(そしてまもなく人間の10倍+の速度で)実行できるようになります。2027 年までにも、GPU フリートは数十万台になると予想されています。トレーニングクラスターだけでも~3 OOMに近づくはずで、すでに1,000万+ A100相当になります。推論フリートはさらに大きくする必要があります。(これについては後の記事で詳しく説明します。
これにより、自動化されたAI研究者の数百万部、おそらく1億人の人間研究者相当のコピーを昼夜を問わず実行できるようになります。正確な数値には、人間が100トークン/分で「考える」という仮定(例えば、内面的なモノローグを考えてみてください)や、同じ球場に残っているフロンティアモデルのトークンごとの推論コストについて、過去の傾向やチンチラのスケーリング法則を推定することなど、いくつかの仮定が正確な数値に流れ込んでいます。
また、一部の GPU は、実験の実行や新しいモデルのトレーニングのために予約したいと考えています。脚注での完全な計算。
別の見方をすれば、2027年に推論フリートが存在することを考えると、インターネット全体に相当するトークンを毎日生成できるはずだということです。
いずれにせよ、正確な数字は、単純な妥当性の証明以外にはそれほど重要ではありません。
さらに、自動化されたAI研究者は、まもなく人間の速度よりもはるかに速く実行できるようになるかもしれません。
推論のペナルティを負うことで、より速いシリアル速度で実行することと引き換えに、実行数を減らすことと引き換えにすることができます。(例えば、自動化された研究者を100万部だけ実行するだけで、人間の速度を~5倍から~100倍に増やすことができる。
)
さらに重要なことは、自動化されたAI研究者が取り組む最初のアルゴリズムの革新は、10倍または100倍のスピードアップを達成することです。Gemini 1.5 Flashは、最初にリリースされたGPT-4よりも~10倍高速です。
それだけでも、推論ベンチマークでは、最初にリリースされたGPT-4と同様のパフォーマンスを発揮しました。これが、数百人の人間の研究者が1年で見つけることができるアルゴリズムのスピードアップであるならば、自動化されたAI研究者は、同様の勝利を非常に迅速に見つけることができるでしょう。
つまり、AI研究の自動化が始まって間もなく、1億人の自動化された研究者がそれぞれ人間の100倍の速度で働くことが予想されます。 彼らはそれぞれ、数日で1年分の仕事をこなせるようになるのです。研究努力の増加は、今日の主要なAI研究所の数百人のちっぽけな人間の研究者が人間の1倍の速度で働いているのに比べて、驚くべきものになるでしょう。
これにより、アルゴリズムの進歩の既存の傾向が簡単に劇的に加速し、10年間の進歩が1年に圧縮される可能性があります。自動化されたAI研究がAIの進歩を激しく加速するために、まったく新しいことを仮定する必要はありません。前の記事の数字を見てみると、アルゴリズムの進歩が過去10年間のディープラーニングの進歩の中心的な推進力であったことがわかりました。アルゴリズムの効率性だけで年間~0.5 OOM/年のトレンドラインが見られ、さらにアンホブリングによるアルゴリズムの大きな利益が上に置かれていることに注目しました。(私は、アルゴリズムの進歩の重要性は多くの人に過小評価されてきたと思いますが、それを適切に評価することは、知能爆発の可能性を評価するために重要です。
何百万人もの自動化されたAI研究者(まもなく人間の10倍または100倍の速度で作業)は、人間の研究者が10年で発見したであろうアルゴリズムの進歩を1年に圧縮できるでしょうか?これは、年間で5+ OOMSになります。
ここに1億人のジュニアソフトウェアエンジニアのインターンがいると想像するだけではありません(今後数年以内に、もっと早く、彼らを獲得するでしょう)。本物の自動化されたAI研究者は非常に賢く、自動化されたAI研究者は、その生の定量的な優位性に加えて、人間の研究者よりも大きな利点を持っています。
これまでに書かれたMLの論文をすべて読み、ラボでこれまでに行われたすべての実験について深く考え、それぞれのコピーから並行して学び、数千年分に相当する経験を急速に蓄積することができます。彼らは、ML について人間よりもはるかに深い直感を育むことができます。
彼らは簡単に何百万行もの複雑なコードを書くことができ、コードベース全体をコンテキストに保ち、バグや最適化のためにコードのすべての行をチェックし、再チェックするために何十年も(またはそれ以上)を費やすことができます。彼らは仕事のあらゆる部分で見事に有能です。
自動化されたAI研究者を一人一人個別にトレーニングする必要はありません(実際、新たに採用された1億人の人間のトレーニングとオンボーディングは難しいでしょう)。代わりに、そのうちの 1 つを教えてオンボードし、レプリカを作成できます。(そして、政治活動や文化の順応などについて心配する必要はなく、彼らは昼夜を問わず最高のエネルギーと集中力で働きます。
膨大な数の自動化されたAI研究者がコンテキストを共有できるようになり(おそらくお互いの潜在空間にアクセスするなど)、人間の研究者よりもはるかに効率的なコラボレーションと調整が可能になります。
そしてもちろん、最初の自動化されたAI研究者がどれほど賢かったとしても、すぐにさらにOOMジャンプを行い、さらに賢いモデルを作成し、自動化されたAI研究でさらに有能になるでしょう。
自動化されたアレック・ラドフォードを想像してみてください、1億人の自動化されたアレック・ラドフォードを想像してみてください。
OpenAIのほぼすべての研究者が、10人のアレック・ラドフォードがいれば、ましてや100人、1000人、100万人が人間の10倍、100倍の速度で動けば、非常に多くの問題を素早く解決できると同意すると思います。他にもさまざまなボトルネックがありますが(これについては後ほど詳しく説明します)、その結果、10年間のアルゴリズムの進歩を1年に圧縮することは非常に妥当なように思えます。(100万倍の研究努力による10倍の加速で、どちらかといえば控えめに見えます。
それはそこに5+ OOMSになります。アルゴリズムによる勝利の5 OOMは、GPT-2からGPT-4へのジャンプ、つまり~未就学児から~賢い高校生への能力ジャンプを生み出したものと同様のスケールアップになります。AGIの上に、アレック・ラドフォードの上に、このような質的な飛躍を想像してみてください。
私たちがAGIから超知能に非常に早く、おそらく1年以内に移行する可能性は驚くほどもっともらしいです。
考えられるボトルネック
この基本的な話は驚くほど強力で、徹底的な経済モデリング作業によって支えられていますが、自動化されたAI研究のインテリジェンスの爆発的な増加を遅らせる可能性のある、現実的でもっともらしいボトルネックがいくつかあります。
ここで要約を説明し、興味のある方のために以下のオプションのセクションでこれらについて詳しく説明します。
コンピューティングの制限: AI 研究には、優れたアイデア、思考、数学だけでなく、実験を実行してアイデアに実証的なシグナルを導き出す必要があります。自動化された研究労働によって研究努力が100万倍増えても、100万倍の速さで進歩するわけではありません。なぜなら、計算量は依然として限られており、実験のための計算量が限られていることがボトルネックになるからです。それでも、これが1,000,000倍のスピードアップにならないとしても、自動化されたAI研究者が計算を少なくとも10倍効果的に使用できなかったとは想像しがたいです:彼らは信じられないほどのMLの直感を得ることができ(MLの文献全体と以前のすべての実験を毎回実行することで)、何世紀にもわたる思考時間に相当するものを手に入れて、実行するのに適切な実験を見つけ出すことができます。 最適に設定し、情報の最大値を取得します。彼らは、バグを回避し、最初の試行で正しくするために、小さな実験を実行する前に何世紀にもわたるエンジニアの時間を費やすことができます。彼らは、最大の勝利に焦点を当てることにより、コンピューティングを節約するためのトレードオフを行うことができます。そして、彼らは大量の小規模な実験を試すことができるでしょう(そして、それまでに効果的な計算スケールアップが進めば、「小規模」とは、アーキテクチャのブレークスルーを試すために年間100,000のGPT-4レベルモデルを訓練できることを意味します)。人間の研究者やエンジニアの中には、同じ計算量でも他の研究者の10倍の進歩を生み出すことができる人もいますが、これは自動化されたAI研究者にさらに当てはまるはずです。これが最も重要なボトルネックだと思いますので、以下で詳しく説明します。
相補性/ロングテール:経済学からの古典的な教訓(ボーモルの成長病を参照)は、たとえば何かの70%を自動化できれば、ある程度の利益が得られますが、残りの30%がすぐにボトルネックになるということです。完全な自動化に及ばないもの、例えば、本当に優れた副操縦士の場合、人間のAI研究者は依然として大きなボトルネックとなり、アルゴリズムの進歩率の全体的な増加は比較的小さくなります。さらに、AI研究の自動化にはロングテールの能力が必要とされ、AI研究者の仕事の最後の10%は特に自動化が難しいかもしれません。これにより離陸がいくらか柔らかくなるかもしれませんが、私の最善の推測では、これは物事を数年遅らせるだけだということです。おそらく、2026/27モデルのスピードは、自動化の原型であり、最終的な脱却、やや改善されたモデル、推論の高速化、完全な自動化へのねじれの解決にはさらに1年か2年かかり、最終的に2028年までに10倍の加速が得られます(そして10年後までに超知能化されます)。
アルゴリズムの進歩に内在する限界:もしかしたら、アルゴリズムの効率をさらに5OOM増やすことは基本的に不可能になるかもしれません。それはどうかと思います。確かに上限はありますが、
過去10年間で5つのOOMSを獲得した場合、少なくともさらに10年分の進歩が可能になると予想すべきでしょう。より直接的には、現在のアーキテクチャとトレーニングアルゴリズムはまだ非常に初歩的であり、はるかに効率的なスキームが可能であるように思われます。生物学的参照クラスは、より効率的なアルゴリズムが妥当であることもサポートしています。
アイデアを見つけるのが難しくなるため、自動化されたAI研究者は、現在の進捗速度を加速させるのではなく、単に維持するだけです。 1つの反論は、自動化された研究は効果的な研究努力を大幅に増やす一方で、アイデアを見つけるのも難しくなるということです。つまり、今日では、研究室のトップ研究者が数百人しか必要としないのに、年間0.5 OOMを維持するのに必要ですが、低空飛行の果実を使い果たすと、その進歩を維持するためにはますます多くの努力が必要になります。この基本モデルは正しいと思いますが、経験論は合致しません:研究努力の増加の大きさ(100万倍)は、進歩を維持するために必要であった研究努力の成長の歴史的な傾向よりもはるかに大きいです。経済モデリングの用語では、自動化による研究努力の増加が、進歩を一定に保つのに十分であると仮定するのは奇妙な「ナイフエッジの仮定」です。
アイデアを見つけるのが難しくなり、収穫逓減があるため、知能の爆発的な増加はすぐに消えます:上記の反論に関連して、自動化されたAI研究者が最初に進歩の爆発につながったとしても、急速な進歩を維持できるかどうかは、アルゴリズムの進歩に対する収穫逓減曲線の形状に依存します。繰り返しになりますが、経験的証拠の私の最良の読みは、指数が爆発的/加速的な進歩を支持して揺さぶられるということです。いずれにせよ、1回限りの増加の規模(数百万人から数十万人のAI研究者)は、アルゴリズムの進歩の少なくともかなりの数のOOMで、ここでの収穫逓減をおそらく克服するでしょう。
実験のための限られたコンピューティング
補完性と100%自動化へのロングテール
アルゴリズムの進歩に対する基本的な制限
アイデアを見つけるのが難しくなり、収穫が減少します
全体として、これらの要因は物事をいくらか遅らせるかもしれません:最も極端なバージョンの知能爆発(たとえば、一晩中)は信じがたいように思われます。そして、その結果、やや長引くことになるかもしれません(おそらく、物事が本格的に開始する前に、より低迷するプロト自動化された研究者から真の自動化されたアレック・ラドフォードまで、さらに1年か2年待つ必要があるでしょう)。しかし、彼らは確かに非常に急速な諜報活動の爆発を排除していない。1年、あるいはせいぜい数年、あるいは数ヶ月で、完全に自動化されたAI研究者から超人的なAIシステムに移行することが、私たちの主な期待であるべきです。
超知能の力
これらの議論の最も強力な形に同意するかどうかは別として、知能が<1年で爆発的に増加するか、数年かかるかは明らかです。つまり、私たちは超知能の可能性に立ち向かわなければならないのです。
この10年の終わりまでに私たちが持つであろうAIシステムは、想像を絶するほど強力になるでしょう。
もちろん、量的には超人的です。10 年後には、何十億もの GPU を搭載した GPU で、何十億もの GPU の文明を運営できるようになり、人間よりも桁違いに速く「考える」ことができるようになります。彼らは、あらゆるドメインを迅速に習得し、何兆行ものコードを書き、これまでに書かれたすべての科学分野のすべての研究論文を読み(それらは完全に学際的です!)、1つの要約を乗り越える前に新しいものを書き、そのコピーの1つの1つの並行した経験から学び、数週間のうちにいくつかの新しいイノベーションで人間に相当する数十億年の経験を得ることができます。 100%の時間、最高のエネルギーと集中力で働き、遅れているチームメイトに遅れをとられることはありません。
さらに重要なことは、しかし想像しがたいことですが、彼らは質的に超人的になるでしょう。その狭い例として、大規模なRLランは、AlphaGo対Lee Sedolの有名な37手のように、人間の理解を超えた全く斬新で創造的な行動を生み出すことができました。スーパーインテリジェンスは、多くの領域でこれを実現するでしょう。人間のコードには、人間が気付くには微妙すぎるエクスプロイトが見つかり、モデルが何十年もかけて説明しようとしても、人間が理解できないほど複雑なコードが生成されます。人間が何十年も立ち往生する非常に難しい科学技術の問題は、彼らにとって非常に明白に見えるでしょう。私たちは、量子力学の探求がオフのニュートン物理学に立ち往生している高校生のようになります。
これがどれほどワイルドであるかを視覚化するために、Minecraftを20秒で倒すこのビデオなど、ビデオゲームのスピードランのYoutubeビデオを見てください。
さて、これが科学、技術、経済のすべての領域に適用されると想像してみてください。もちろん、ここでのエラーバーは非常に大きいです。それでも、これがどれほど重大な意味を持つかを考えることは重要です。
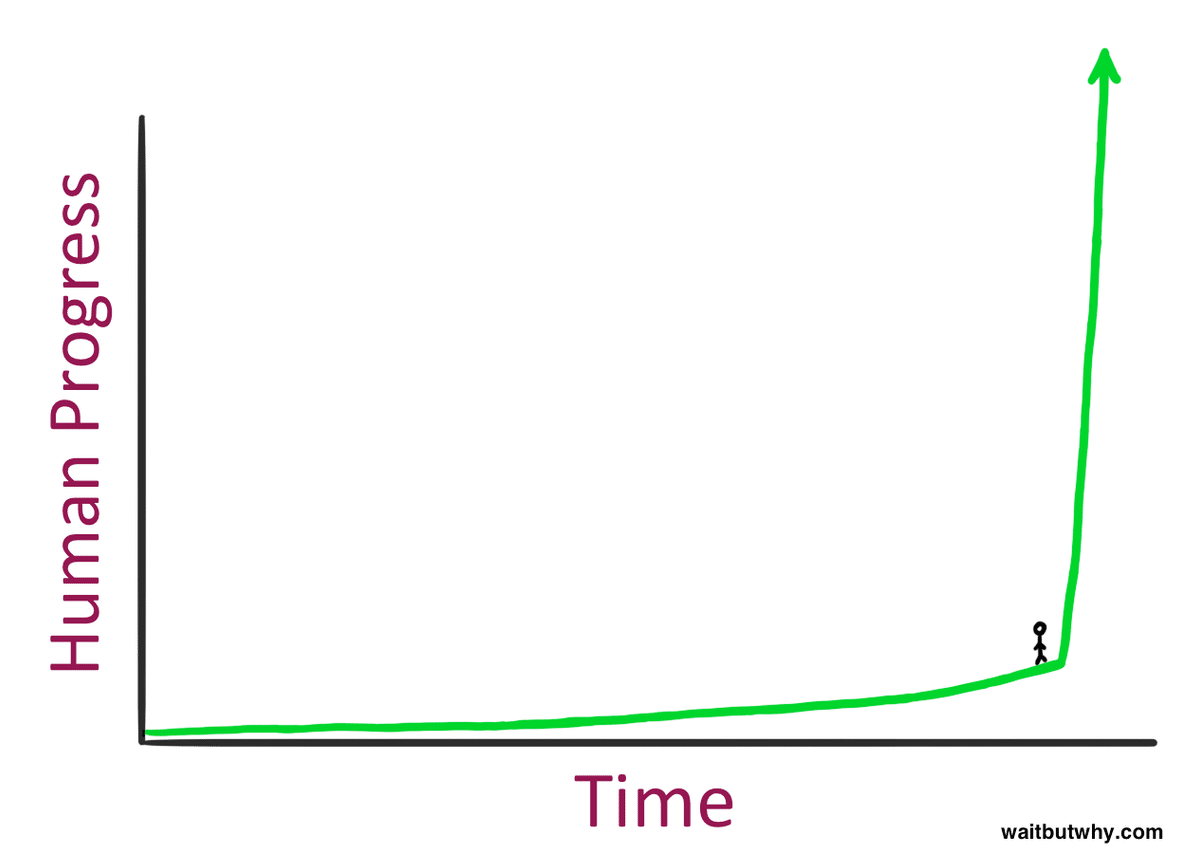
インテリジェンスの爆発的な増加において、爆発的な進歩は当初、自動化されたAI研究の狭い領域にすぎませんでした。私たちが超知能を得て、何十億もの(今では超知能の)エージェントを多くの分野の研究開発に応用するにつれて、爆発的な進歩が広がると私は予想しています。
AI能力の爆発的な増加。 おそらく、初期のAGIには制限があり、(AI研究ドメインだけでなく)他のドメインでの作業を完全に自動化することができなかったのでしょう。自動化されたAI研究は、これらを迅速に解決し、あらゆる認知作業の自動化を可能にします。
ロボティクスを解決します。 超知能は、純粋に認知的なものにとどまることは長くありません。ロボティクスをうまく機能させるには、主に (ハードウェアの問題ではなく) ML アルゴリズムの問題であり、自動化された AI の研究者はおそらくそれを解決できるでしょう (詳細は以下を参照)。工場は人間が運営するものから、人間の肉体労働を使ったAI主導型へと移行し、やがてロボットの群れによって完全に運営されるようになるでしょう。
科学技術の進歩を劇的に加速します。そう、アインシュタインだけでは神経科学を発展させ、半導体産業を築くことはできなかったが、10億人の超知能自動化された科学者、エンジニア、技術者、ロボット技術者(ロボットは人間の10倍以上の速度で動く)を生み出したのだ。
は、数年の間に多くの分野で驚異的な進歩を遂げるでしょう。(これは、AI主導のR&Dがどのようなものになるかを視覚化した素晴らしい短編小説です。10億人の超知能は、次の世紀に人間の研究者が行っていたであろう研究開発の努力を数年に圧縮することができるだろう。20世紀の技術進歩が10年未満に圧縮されたと想像してみてください。私たちは、蜃気楼と考えられていた飛行から、飛行機、そして月面の人間、そしてICBMへと数年のうちに変わっていたでしょう。これが、科学技術全体での2030年代の姿であると私が予想していることです。
産業と経済の爆発。 極端に加速する技術進歩と、すべての人間の労働を自動化する能力が組み合わさることで、経済成長を劇的に加速させることができる(自己複製ロボット工場がネバダ州の砂漠全体を急速にカバーすると考えてください)。
成長率の増加は、おそらく年間2%から2.5%/年になるだけではないでしょう。むしろ、これは成長体制の根本的な転換であり、産業革命による非常に遅い成長から年数パーセントへの歴史的な段階的変化に匹敵するでしょう。経済成長率は年率30%以上、おそらくは年に何倍にもなるでしょう。これは、経済学者の経済成長モデルからかなり直接的に従います。確かに、これは社会的な摩擦によって遅れるかもしれません。難解な規制により、弁護士や医師は、たとえAIシステムがそれらの仕事ではるかに優れていたとしても、依然として人間である必要があると保証するかもしれません。急速に拡大するロボット工場の歯車に砂が投げ込まれるのは、社会が変化のペースに抵抗するに違いありません。そして、おそらく私たちは人間の乳母を保持したいと思うでしょう。これらすべてが、全体的なGDP統計の成長を鈍化させるでしょう。それでも、人間が作り出した障壁を取り除くと(たとえば、競争によって軍事生産のためにそうせざるを得なくなるかもしれない)、産業の爆発を目にするでしょう。
成長モードナツメヤシが支配し始めた世界経済の
倍増時間
(年)狩猟紀元前2,000,000年230,000農紀元前4700年860科学と商業西暦1730年58産業西暦1903年15
超知能?西暦2030年????
文明が狩猟から農業へと移行し、科学と商業の開花、そして工業へと移行するにつれて、世界経済の成長のペースは加速しました。スーパーインテリジェンスは、成長モードの別のシフトを開始する可能性があります。ロビン・ハンソンの「指数関数的モードのシーケンスとしての長期成長」に基づいています。
決定的で圧倒的な軍事的優位性を提供します。 ここでは、初期の認知的超知能でさえ十分かもしれません。おそらく、何らかの超人的なハッキング計画が敵の軍隊を無力化することができるでしょう。いずれにせよ、軍事力と技術進歩は歴史的に密接に結びついており、非常に急速な技術進歩には軍事革命が伴います。ドローンの群れとロボアーミーは大きな問題になりますが、それらはほんの始まりにすぎません。私たちは、新しい大量破壊兵器から、難攻不落のレーザーベースのミサイル防衛、そしてまだ理解できないものまで、まったく新しい種類の兵器を期待すべきです。超知能兵器庫以前の兵器庫と比較すると、それは19世紀の軍隊が馬と銃剣で戦うようなものになるだろう。(超知能がどのようにして決定的な軍事的優位性につながるかについては、後の記事で論じる。
アメリカ政府を打倒できる。 超知能を支配する者は、超知能以前の勢力から支配権を奪取するのに十分な力を持っている可能性が非常に高い。ロボットがなくても、超知能という小さな文明は、無防備な軍事、選挙、テレビなどのシステムをハッキングし、将軍や有権者を巧妙に説得し、国民国家を経済的に打ち負かし、新しい合成生物兵器を設計し、それを合成するために人間にビットコインを支払うなどできるだろう。1500年代初頭、コルテスと約500人のスペイン人が数百万人のアステカ帝国を征服しました。ピサロと~300人のスペイン人が数百万人のインカ帝国を征服しました。アルフォンソと~1000人のポルトガル人がインド洋を征服しました。彼らは神のような力を持っていなかったが、旧世界の技術的優位性と戦略的・外交的な狡猾さが、完全に決定的な優位性をもたらした。超知能も似ているかもしれません。
ロボット

これらすべてが2030年代にどのように展開するかを予測するのは難しいです(そして、別の機会に話します)。しかし、少なくとも1つ明らかなことは、私たちは人類がこれまでに直面した中で最も極端な状況に急速に突入するということです。
人間レベルのAIシステムであるAGIは、それ自体が非常に重要になりますが、ある意味では、私たちがすでに知っていることのより効率的なバージョンにすぎません。しかし、非常にもっともらしく言えば、わずか1年以内に、私たちははるかに異質なシステム、その理解力と能力、その生の力は、人類を合わせたものをも超えるシステムに移行するでしょう。この急速な移行期には、AIシステムに信頼を委ねることを余儀なくされるため、コントロールを失う可能性が現実にあります。
より一般的には、すべてが信じられないほど速く起こり始めます。そして、世界は狂気に陥り始めるでしょう。私たちがわずか数年で20世紀の地政学的な熱狂と人為的な危険を経験したと仮定します。それが、ポスト・スーパーインテリジェンスが予期すべき状況である。それが終わる頃には、超知能AIシステムが私たちの軍事と経済を動かしているでしょう。このような狂気の沙汰の中で、正しい決断を下すための時間は極めて少ないでしょう。課題は計り知れません。それを一つにまとめるためには、私たちが持っているすべてのものが必要です。
知能の爆発と超知能化直後の時代は、人類史上最も不安定で、緊張し、危険で、最も荒々しい時期の一つとなるでしょう。
そして、10年後には、私たちはその真っ只中にいる可能性が高いでしょう。
知能爆発の可能性、つまり超知能の出現に直面することは、核連鎖反応の可能性とそれによって可能になる原子爆弾をめぐる初期の議論としばしば共鳴します。H.G.ウェルズは1914年の小説で原爆を予言しました。シラードが1933年に初めて連鎖反応のアイデアを思いついたとき、彼はそれを誰にも納得させることができませんでした。それは純粋な理論でした。1938年に核分裂が経験的に発見されると、シラードは再びパニックになり、秘密保持を強く主張し、少数の人々が爆弾の可能性に目覚め始めた。アインシュタインは連鎖反応の可能性を考えていなかったが、シラードが彼と対峙したとき、彼はその意味をすぐに理解し、必要なことは何でもするつもりだった。彼は警鐘を鳴らすことを厭わず、愚かに聞こえることを恐れなかった。しかし、フェルミ、ボーア、そしてほとんどの科学者は、「保守的」なことは、爆弾の可能性の並外れた意味合いを真剣に受け止めるのではなく、それを軽視することだと考えていた。秘密主義(自分たちの進軍をドイツと共有することを避けるため)やその他の全面的な努力は、彼らにとってばかげているように見えました。連鎖反応はあまりにも狂っているように聞こえました。(結局のところ、爆弾が現実になるのはわずか50年だったときでさえ。
私たちは、連鎖反応の可能性に再び立ち向かわなければなりません。もしかしたら、それはあなたにとっては推測的に聞こえるかもしれません。しかし、AI研究所の上級科学者の間では、多くの科学者が、急速な知能爆発を驚くほどもっともらしいと見ています。彼らはそれを見ることができます。超知能は可能です。
シリーズの次の投稿:
III.課題 – IIIa.1兆ドルクラスターへの競争
そして、冷戦の倒錯(ダニエル・エルズバーグの著書を参照)の多くは、核政策や戦争計画を大規模な能力増強に合わせて調整することなく、単に原爆を水爆に置き換えることに起因していた。
AI研究者の仕事は、AI研究所のAI研究者がよく知っている仕事でもあるため、その仕事をうまくこなすためにモデルを最適化することは、彼らにとって特に直感的になります。そして、彼らの研究とラボの競争力を加速させるために、そうするための大きなインセンティブがあります。
ちなみに、これはAIからのリスクの順序付けという点で重要なポイントを示唆しています。人々が指摘する一般的なAI脅威モデルは、新しい生物兵器を開発するAIシステムであり、それが壊滅的なリスクをもたらすというものです。しかし、AI研究が生物学の研究開発よりも自動化が簡単であれば、極端なAIの生物学的脅威が発生する前に、知能が爆発的に増加する可能性があります。これは、例えば、AIがおかしくなる前に「バイオ警告ショット」を期待すべきかどうかという点で問題になります。
先に述べたように、GPT-4 APIはリリース時のGPT-3よりも現在のコストが低く、これは、モデルがはるかに強力になっても推論コストがほぼ一定に保たれるほど、推論効率の傾向が速いことを示唆しています。同様に、GPT-4がリリースされてからわずか1年で、推論コストの大幅な勝利がありました。例えば、Gemini 1.5 Proの現在のバージョンは、オリジナルのGPT-4よりも性能が高く、しかも約10倍安価です。
また、チンチラのスケーリング法則を考慮することで、これをもう少し根拠づけることもできます。チンチラのスケーリング則では、モデルのサイズ、つまり推論コストは、トレーニングコストの平方根、つまり効果的なコンピューティングのOOMスケールアップの半分とともに増加します。しかし、前の記事では、アルゴリズムの効率がコンピューティングのスケールアップとほぼ同じペースで進んでいる、つまり、効果的なコンピューティングスケールアップのOOMの約半分を占めていることを示唆しました。これらのアルゴリズムの勝利が推論効率にも変換される場合、アルゴリズムの効率は推論コストの単純な増加を補うことを意味します。
実際には、コンピューティング効率のトレーニングは、常にではありませんが、多くの場合、推論効率の勝利につながります。ただし、学習効率の勝利ではない推論効率の勝利も別途多数あります。したがって、少なくとも大まかな球場に関しては、フロンティアモデルの$/tokenがほぼ同じままであると仮定することは、クレイジーには見えません。
(もちろん、より多くのトークン、つまりテスト時のコンピューティングをより多く使用します。しかし、それはすでにここでの計算の一部であり、人間に相当するものを100トークン/分と価格設定しています。
GPT-4ターボは約0.03ドル/1Kトークンです。A100相当のものは数十万個あると想定していましたが、A100相当の場合、GPUあたり~1時間~1ドルの費用がかかります。APIのコストを使用してGPUを生成されたトークンに変換すると、数十万のGPU×$1/GPU時間×33Kトークン/$=~1兆トークン/時間を意味します。人間が100トークン/分の思考を行うとすると、人間に相当するのは6,000トークン/時間であることを意味します。1兆トークン/時を6,000トークン/人時で割った値=~2億人の人間相当、つまり、2億人の人間の研究者を昼夜を問わず運営しているようなものです。(また、GPU の半分を実験計算用に予約したとしても、人間の研究者に匹敵する 1 億個が得られます。
前の脚注では、~1Tトークン/時間、つまり1日あたり24Tトークンと見積もっていました。前回の記事では、公開の重複排除されたCommonCrawlには約30Tトークンがあることを指摘しました。
Jacob Steinhardt は、タイリング スキーム (理論的には 100 以上の k でも機能する) による推論のトレードオフに関するいくつかの計算を考えると、モデルの k^3 並列コピーを k^2 高速な 1 つのモデルに置き換えることができると推定しています。初期速度がすでに人間の速度~5倍だったとします(たとえば、リリース時のGPT-4の速度に基づく)。そして、この推論ペナルティ(k= ~5)を負うことで、~100万人の自動化されたAI研究者を~人間の100倍の速度で実行できるようになります。
このソースは、~6x GPT-4 TurboでのFlashのスループットをベンチマークしており、GPT-4 Turboは元のGPT-4よりも高速でした。レイテンシもおそらく約10倍高速です。
アレック・ラドフォードは、OpenAIの信じられないほど才能があり、多作な研究者/エンジニアであり、最も重要な進歩の多くを支えていますが、彼はレーダーの下を飛んでいる人もいます。
例えば、GPT-4の上に25のOOMのアルゴリズムの進歩があることは明らかに不可能です:それは、ほんの一握りのFLOPでGPT-4レベルのモデルを訓練することが可能であることを意味しています。
現実の世界で物理的な研究開発を行っている10倍速のロボットは「低速バージョン」です。実際には、超知能は、AlphaFoldや「デジタルツイン」の製造のように、シミュレーションでできるだけ多くの研究開発を行おうとします。
なぜ「ファクタリオワールド」、つまり、より多くの工場を生産し、さらに多くの工場を生産し、工場を倍増させ、最終的には地球全体がすぐに工場で覆われるという「ファクタリオワールド」が今日は不可能なのでしょうか?そうですね、労働には制約があり、資本(工場、工具など)を蓄積することはできますが、固定された労働力によって制約されるため、収穫逓減に陥ります。ロボットやAIシステムが労働を完全に自動化できるようになったことで、その制約は取り除かれます。ロボファクトリーは、~制約のない方法でより多くのロボファクトリーを生産することができ、産業爆発につながる。これに関するその他の経済成長モデルについては、こちらをご覧ください。
考察ノート:「AGIリスク」の議論にどう向き合えばいいのか Ver.1カテゴリその他概要本稿では、未来のAIのもたらす甚大なリスクとして語られる「AGIリスク」について、筆者の見分と文献調査をもとにまとめたレポート。
● AGIリスクとは何か、何が懸念されているのか? (第1章)
● AGIリスクを語っているのはどういう人たちなのか? (第2章)
● AGIリスクはどのように対処されようとしているのか? (第3章)
● AGIリスク論はどれくらい主流なのか? (第4章)
● 日本語圏でAIに関わる私たちは、この問題についてどんな態度でいればよいのか?(第5章)
いいなと思ったら応援しよう!
