
3つの手順で作る、リアルな音声会話アバター作成(プロジェクトマネージャーのAI研究)【Unreal Engine+ChatGPT+GCP】

こんにちは。株式会社マネジメントのAIプロジェクトチームです。
会話する仕事をAIが助けてくれる未来が近づきつつあり、音声で会話できるアバターの技術検証を実施しています。
近い将来にはプロジェクトマネージャーやプロジェクトデザイナーのアシスタントとしてサポートできる想定です。
なお、本件は2024年10月時点の情報であり、Unreal Engineやプラグインがアップデートされて、このとおりに作動しなくなる場合もありますことは、あらかじめご了承ください。
1. はじめに
1-1.完成イメージ
PCの画面上のフォトリアルなアバターと会話ができます。
1-2. 環境
Windows 11
Unreal Engine 5.3.2
2. 準備
2-1. Unreal Engine
2-1-1. Unreal Engine インストール
以下のリンク先を参考にして、Unreal Engine をインストールします。
https://www.unrealengine.com/ja/download
2-1-2. プラグインのインストール
Epicランチャーを開き、
Unreal Engine > マーケットプレイスから

以下のプラグインをダウンロードし、インストールします。
MetaHumanプラグイン
MetaHuman SDK

Google Speech Kit

VaRest

2-1-3. 新規プロジェクト作成
プロジェクトを開くか、新規作成する。
なお、プロジェクトの保存場所は、パスに日本語がないところ。
後の手順でパッケージ化するときにエラーになるため、「ドキュメント」などの日本語のパスがあるような場所への作成はNG。
C:\ドキュメント\UnrealEngineProject #NGちなみに、今回の検証では、以下のフォルダに保存してます。
C:\UnrealEngineProject編集 > プラグイン
先ほどインストールしたプラグイン全部と
デフォルトのプラグイン「Json Blueprint Utilities」、「Audio Capture plugin」にチェックして、再起動します。
再起動してこういうメッセージが現れたら、「不足しているものを有効にする」をクリックして再起動します。

編集 > プロジェクト設定 > プラグイン > MetaHumanSDK
Personal Account をクリック

MetaHumanSDK のサイトが開き、利用者登録をして、APIキーを発行します。
そのAPIキーをさきほどのところにコピー&ペーストします。

なお、MetahumanのAPIは
STANDARD PLAN 毎月15ドルで75分まで
75分超過する場合1分あたり0.3USD
ウィンドウ > Quixel Bridge
使用するメタヒューマンを選びます。

コンテンツドロアーに Metahumans フォルダができています。
Metahumans > Taro > BP_Taroのブループリントを画面へドラッグします。

「プラグインがありません」「プロジェクト設定がありません」のような
アラートウィンドウが3つくらい出ます。
これらの「不足しているものを有効にする」をクリックします。

Metahuman Taro が画面に現れます。
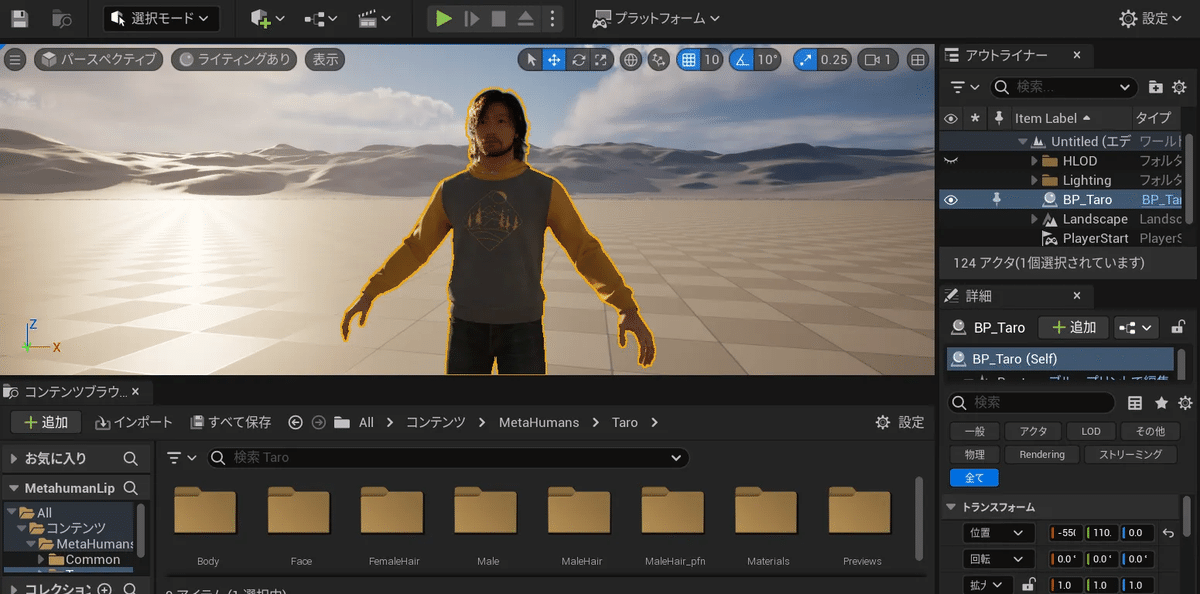
Taro の位置は、 0, 0, 0
PlayerStartの位置は以下とすると、プレイしたときTaroが画面の真正面にきます。

2-2. Google Speech to Text
パソコンに向かって話した言葉をテキストに変えるために、GoogleCloudのAPIを発行します。
Google Cloud で新規プロジェクトを作成
API とサービス > 認証情報 > 「+認証情報を作成」> APIキー
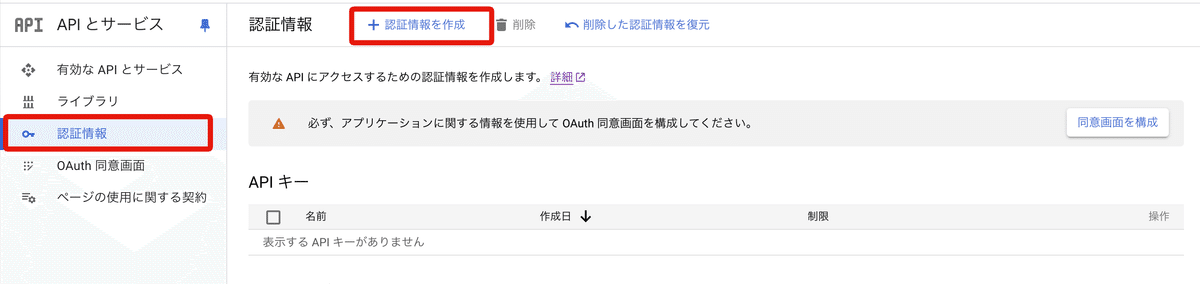

APIキーはどこかに控えておきます (あとでも見れます)
※なおAPIは有料
https://cloud.google.com/speech-to-text/pricing?hl=ja
月間で60分以上の場合、1分あたりの料金はJPY 3.69996(USD 0.016)
(60分までは無料)
UEでは、パソコンに向かって話した言葉をテキストに変えるところを、先ほどインストールした Google Speech Kit を使います。
あとでブループリントを一括コピー&ペーストするので、ここでの説明は省略します。
詳細の使用方法はこちら
https://github.com/IlgarLunin/UE4GoogleSpeechKit-docs
2-3. Audio Capture の設定
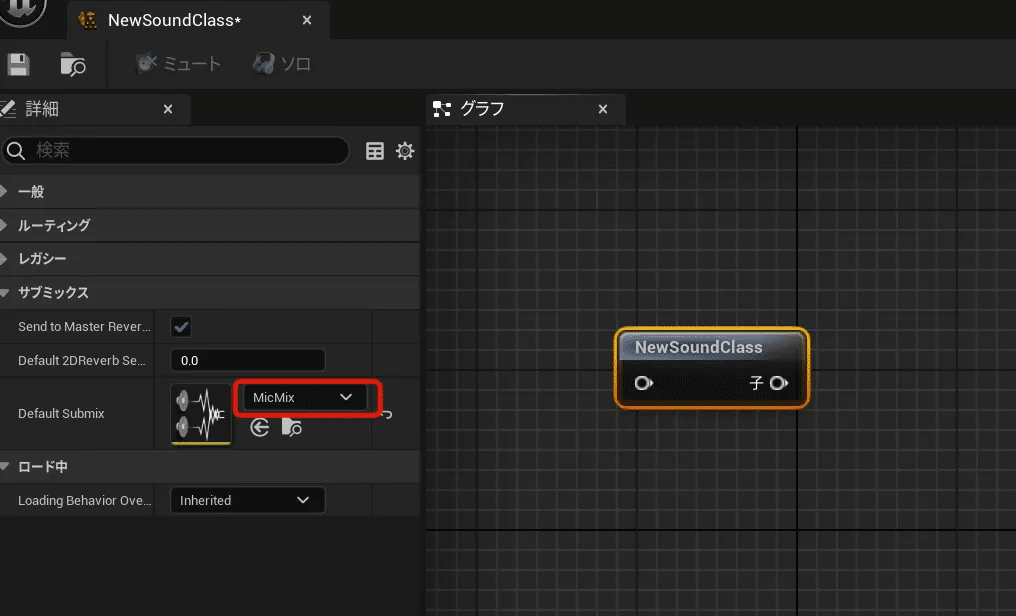
○サウンドミックス作成
コンテントブラウザーの中で右クリック
オーディオ > ミックス >サウンドサブミックス
名前を MicMixにして、ダブルクリック
サブミックスレベルの Output Volume を -96.0 に
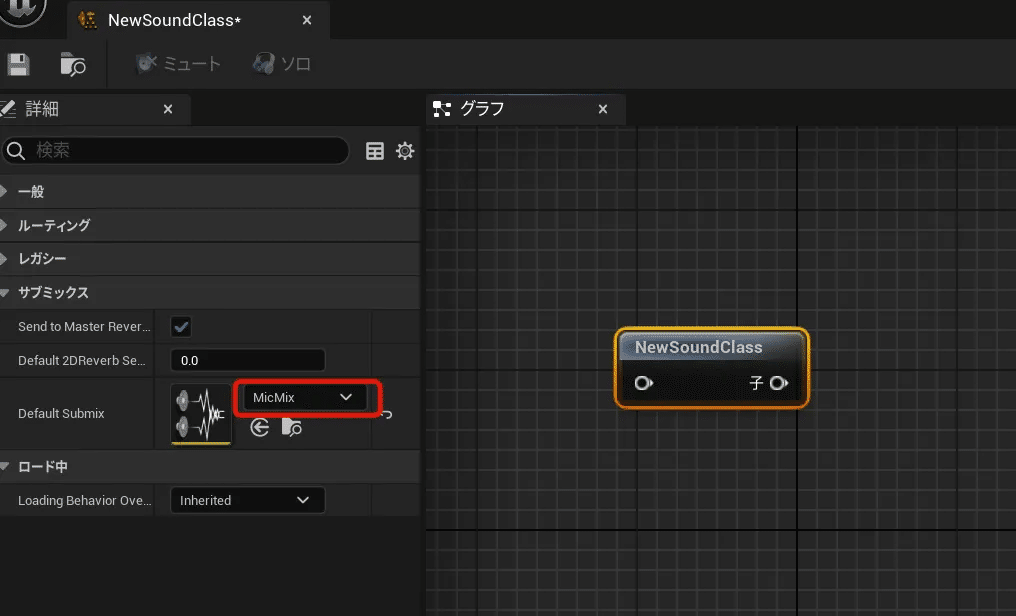
○サウンドクラス作成
コンテントブラウザーの中で右クリック
オーディオ> クラス > サウンドクラス
できたサウンドクラスを開き、さきほど作成したサブミックスをセットします。
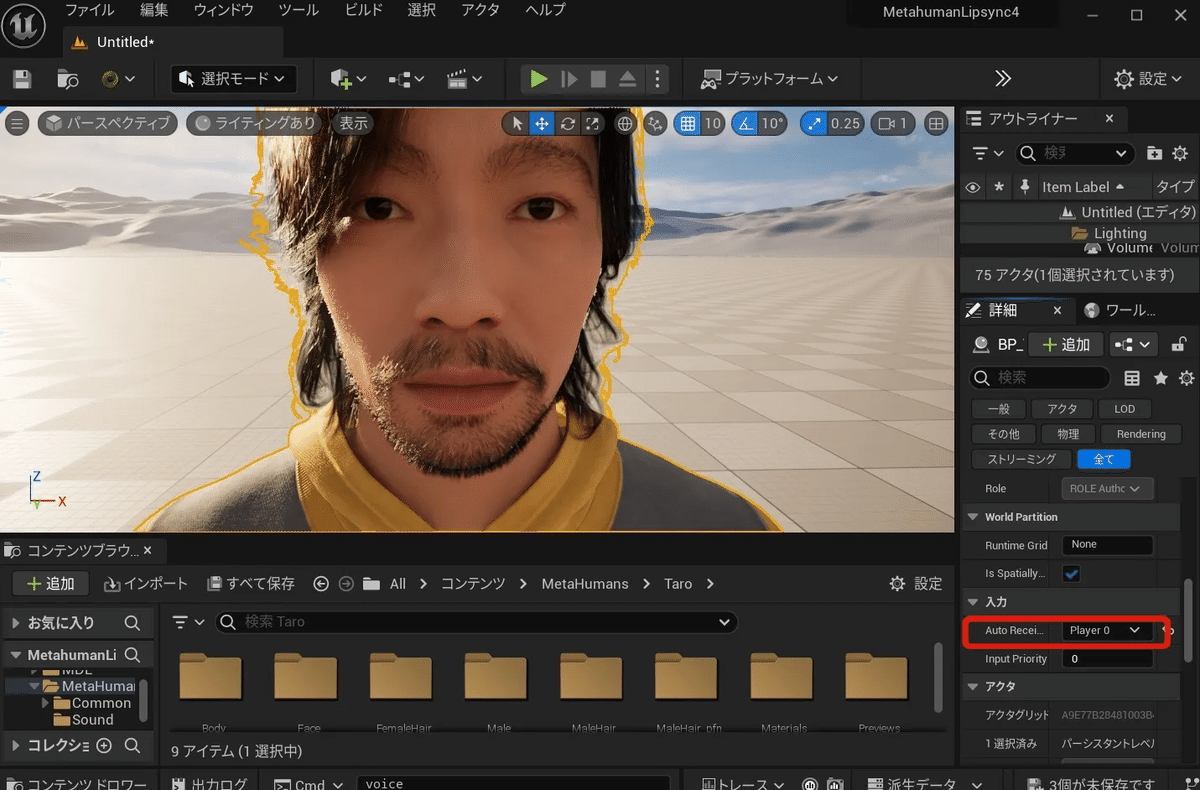
メタヒューマンのブループリントを開き、
コンポーネント>「+追加」

「AudioCapture」を選択

右側の「アクティベーション」の「Auto Activate」のチェックを外します。

サウンドクラスに先ほど作成したサウンドクラスを設定します。

メタヒューマンの右側の「入力」を「Player0」とします。
2-4. OpenAI
OpenAIのウェブサイトでAPIキーを作成、どこかに控えます。
https://platform.openai.com/docs/overview
ちなみにAPIの料金(GPT3.5 turbo)
https://openai.com/api/pricing/
入力トークン:100万トークンあたり3ドル 出力トークン:100万トークンあたり6ドル
2-5. Lipsyncの設定(MetahumanSDK)
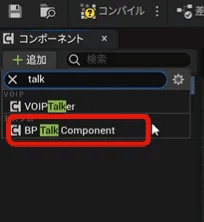
メタヒューマンのブループリントで、
コンポーネント > +追加
BP Talk Component を選びます。
3. 作成・実行
3-0. ブループリントの修正・設定
以下の画像のとおり、MetaHuman Taro のブループリントを開き、イベントグラフを開きます。
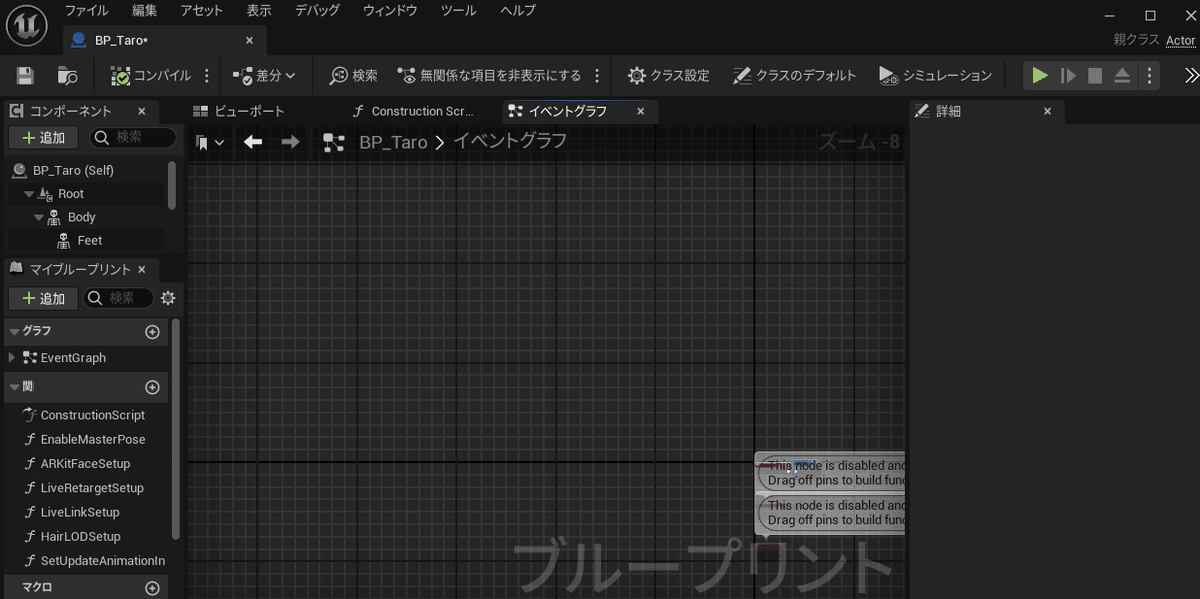
こちらの完成版のブループリント
を全部コピーして、先ほどのイベントブラフにペーストします。

左上のここが「WARNING」になってる場合は
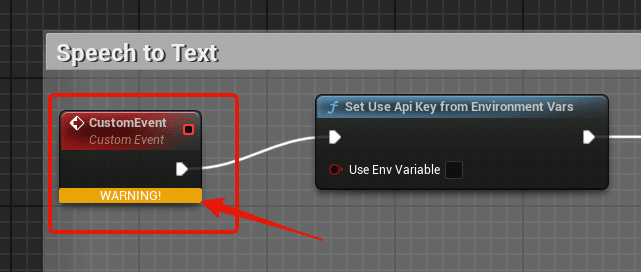
イベントグラフのデフォルトで存在するこれに

差し替えます。

一度、コンパイルします。
エラーがたくさん出てきます。
これらは変数のエラーです。

これら、エラーの出てきた3つの変数を設定します。
・Google API Key
・SampleName (音声ファイルのファイル名前、なんでもいい)
・OpenAI API Key
コンポーネント > 変数 のところで、
右クリック > 変数

変数を作成します。
・Google API Key
・Sample Name
・OpenAI API Key

コンパイルします。
先ほどと同じエラーが出て、コンパイルは失敗しますが、
さきほど作成した変数のデフォルト値を入力できるようになりましたので、
各値を入力します。

同様に他の変数もデフォルト値を入力します。
エラーが出てる変数のノードを先ほど作成した変数のノード(Get 変数名)と差し替えます。
エラーが出てる変数のノードは削除します。
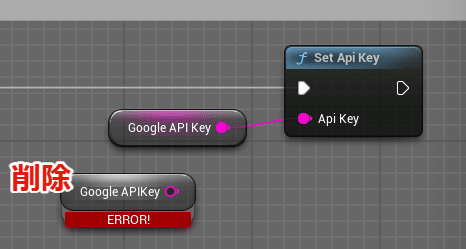
コンパイル!
これでコンパイルが成功するはずです。
最後に言語・声設定
「Talk Text」 ノードをダブルクリックして、
詳細 > Msdk Setting > TTS > Voice ID にします。
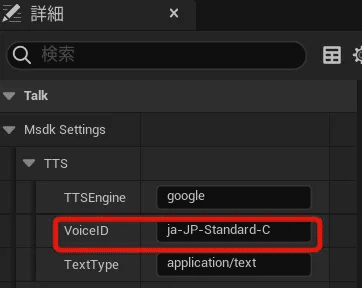
VoiceIDはこのリンク先の「音声名」というところにあります。https://cloud.google.com/text-to-speech/docs/voices?hl=ja
コンパイルして、実行すると、冒頭の動画のようにリップシンク付きのフォトリアルなアバターと会話ができます。
Rボタンを押しながら話してください。Rボタンを放すと、アバターが返答します。
では、ブループリントの内容を簡単に説明します。
大きく3つのパートに分かれます。
(1) Speech to Text
(2) ChatGPT
(3)Text to Speech with Lipsync

3-1. Speech to Text

○内容:
Rキーを押すと録音を開始し、放すと録音を停止し、音声ファイルを作成・保存。その音声ファイルからGoogle APIによりテキスト化します。
○使用プラグイン
・Google Speech Kit
・Audio Capture plugin
○使用API
・Google Cloud API
3-2. ChatGPT
○内容
先ほどのSpeech to Textでテキスト化したデータをOpenAIのAPIに投げて、テキストで返事をもらいます。
こちらのサイトのブループリントをそのまま使用させてもらいました。ありがとうございました。
https://zenn.dev/dokoro/articles/f1f4c0a870f478
○使用プラグイン
・VaRest
・Json Blueprint Utilities
○使用API
・OpenAI
3-3. Text to Speech with Lipsync
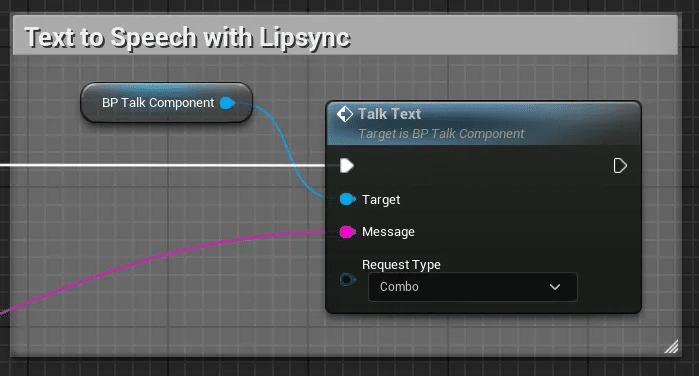
○内容
先ほどのChatGPTの返事のテキストからリップシンク付きでメタヒューマンが話します。。
○使用プラグイン
・Matahuman SDK
4.ウェブブラウザでの実行
Webブラウザで実行するには、Pixel Streaming を使用する方法があります。
こちらの記事をご参照ください。
5.その他
5-1. キャラクターの変更
・ブループリントをそのまま、コピペします。
・コンポーネントに、さきほどのアバターと同じ変数を追加し、デフォルト値の設定をします。
・アバターのコンポーネントに「AudioCapture」 を追加し、「詳細>サウンドクラス」にサウンドクラスを追加する。

・アバターのコンポーネントに「BP Talk Component」 を追加します。
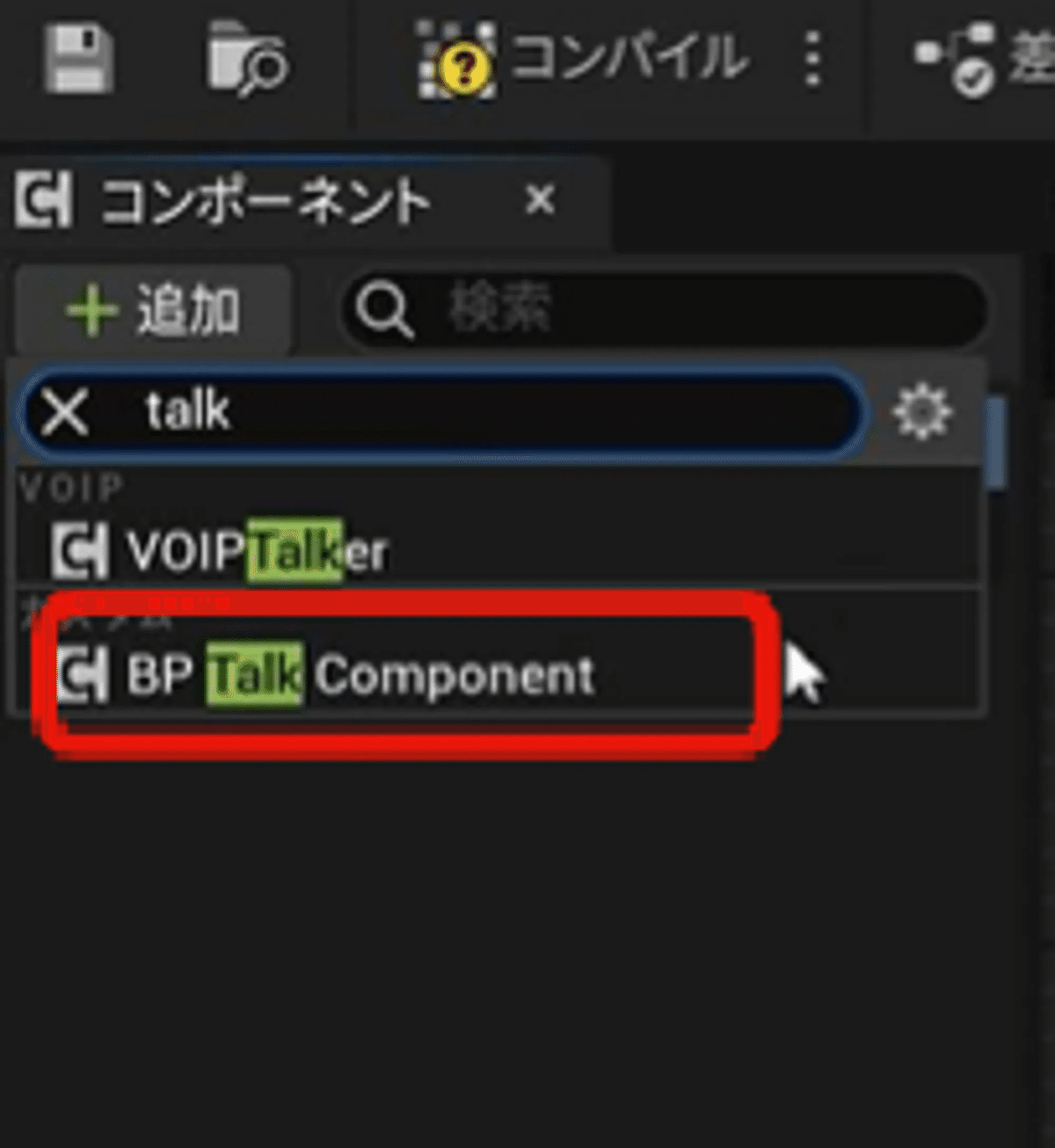
これで、アバターが入れ替わってるはずです。
5-2. 動的に言語・声を指定する方法
Metahuman SDKでは、
以下のように「Talk Text」 ノードにVoice ID(言語・声)が組み込まれているので、実行中に言語や声を切り替えることができません。
そこで、Metahumanの中身のブループリントに手を加えます。
※注意点
プラグインの中身のブループリントを変えるので、他でMetahumanのプラグイン使用プロジェクトに影響があるので気をつけること。なお、新しくプラグインをインストールしたら、この設定はなくなります。
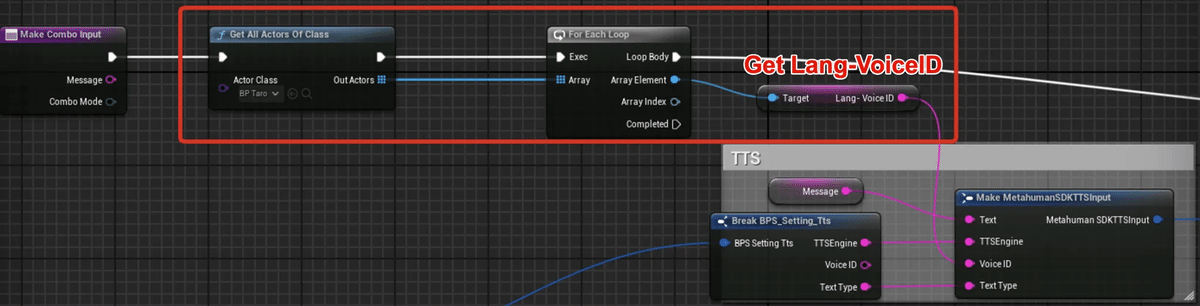
String変数「Lang-VoiceID」を作成します。
「Talk Text」ノードをダブルクリックして、どんどん階層を下っていった先の

ここの部分に

以下のノードを追加します。
以上です。
執筆者|質問&お問い合わせ先
記事の執筆者:おとわ&Tatsuya1970|対話型AI・開発プロジェクトメンバー
Tatsuya1970|自己紹介はこちら