
DeepFakeを活用した動画公開時のプライバシー対策 ━顔バレ対策をしつつもさらに完コピに近づけるための布石━

この記事は「ラブライブ!シリーズのコピユニ Advent Calendar 2023」24日目の記事です。
TL;DR
いくつかのLLコピユニ団体は、顔バレ・プライバシーのために公開する動画を個人を特定できないように工夫している。例えば、引き目のアングルにしたり、マスクをつけたり。
でもそのことは、主に以下の二つの観点で勿体無い:
可愛い顔・巧みな表情管理を拝めない!
顔アップのアングルを使えないから、映像表現をコピーできない!
そこで本稿では、表情の表現を残しつつ、顔バレを防ぐための手法を提案する。具体的にはDeepFakeという人工知能(AI)技術を利用し、顔バレを防ぎたいキャストの顔を、別人に置き換える。
簡単な実験を行い、その結果と将来性について考察する。
あなたは誰

東京工業大学のLLコピユニ「Techours」の事務をやっている教授と申します。教授はLLコピユニ界隈での通り名で、本当は西山大輝と申します。主に映像画像、モーショングラフィックを担当しています。
主の身分は東京工業大学情報理工学院の博士後期課程1年です。機械学習、とりわけAIのセキュリティや信頼性に興味があります。
多動多めの旅行が大好きで、今も青森でこのブログを書いています。
2023年3月までは筑波大学にいたので、筑波大学のLLコピユニ「ツクライブ!」の技術として、映像画像やグラフィック等を担当していました(〜2021、活動終了)。複数の大学LLコピユニを渡り歩いた、珍しい部類だと思ってます。
そのほか過去には金沢大学を中心とした「カガライブ!」や、Guilty Kissコピーユニット「ギルティなんちゃら」などなどでも、撮影関係でお手伝いをさせていただいたことがあります。
いつもみんなお世話になっております🙇🙇🙇
はじめに
非固定映像と固定映像: 「ツクライブ!」から「Techours」に移って気付いたこと、そして着想
ちょっと事情があり、私は今年2023年4月から東工大に入学しました。友達が欲しいので、2-hopの友人関係で繋がっているTechoursに入ることになりました。なぜか旧ツクライブ!メンバーからは「裏切り者」と言われています。なぜ。
Techoursに入ってからの活動は、自然と頭の中でツクライブ!時代と比較することが多かったです。いろんな違いがあるのですが、私の中での印象的な違いは、「動画によるアウトプットにおける違い」です。
ツクライブ!で公開されている動画の多くは非フィクス撮影/映像であり、ライブ映像さながらです。ここでは非フィクス撮影とは、カメラが固定されていない状態のこととし、非フィクス映像はその映像とします。ツクライブ!では、パン・チルト・ズーム視点のカメラ、高解像度のフィックス視点、クレーンによるトラック視点、そしてドローン視点を、映像編集で組み合わせます。(なおフィクス、いわゆる定点も併せて公開されています。)
Techoursで公開されている動画の多くはフィクス撮影/映像、いわゆる定点の映像です。フィクス撮影とはカメラが固定されてとられたことを指し、フィクス映像はその映像を指すこととします。
非フィクス映像とフィクス映像をセマンティックな観点で比較すると、非フィクス映像はジェネラル向けな演出で、フィクス映像は(コピー)ダンサー向けな動画になっていることは言えると思います。つまりリーチする/させたい視聴者の対象が異なるわけです。なので、非フィクス映像とフィクス映像の間には優劣はなく、どっちもあることで互いのリーチできない視聴者を補完できると言えます。
しかし、フィクス映像だけならまだしも、非フィクス映像を作成し公開するには、カメラ機材や編集技術以前の課題が存在します。それは、ズームインでのキャストの顔アップなどのアングルから発生する払拭しにくい不安、プライバシーの問題です。
私は以前Techoursに非固定撮影と映像の公開をラフに提案したことがあるのですが、そこでは顔バレ等のプライバシーの観点で控えたいという意見がありました。私の中のベースラインがツクライブ!だったので、この意見は「言われてみれば確かに」と言う、少し盲点でありました(ツクライブ!キャスト全員が顔出し完全OKというわけではありません。)。
コピユニ動画におけるプライバシーと表現のトレードオフ
以下で扱うプライバシーとは、特筆のない限り、特定の個人の顔、特にキャストの顔のことを指すこととします。
LLのみならず、多くのコピユニはYoutube上に動画でその活動を発信しています。その中には、特定の個人の顔を特定できる程度には解像度・ズーム度がある映像もあります。一方でプライバシー対策として、適度にぼかしたり、顔を画面外にしたり、マスクをつけたりした上でアップされている動画も多いです。
プライバシー対策をしているケースに共通するのは、顔に何らかの加工が施されていることです。これに起因する重大な課題に、可愛い顔、尊いお顔、巧みな表情管理など、顔起点のダンス表現を拝めないことがあります。表情はダンスの重要な因子の一つなので、できれば削りたくない要素です。
(西山の主観:)また、顔を出すか出さないかで受け取りての態度も変わると私は思いますし、それだけ顔というパーツは重要だと考えています。要は少なくとも私は人の顔が好きなのです(告白)。
すなわち、プライバシー対策がされた映像と比べて、顔を出す非フィクス映像は、表現力が高いのに対してプライバシーを守れないという課題があります。
この課題を解決することの重要性は、LLコピユニの発信や表現の完成度に繋がるから重要というだけではなく、コピユニそのもの活動と密接に関連しているという点で重要だと考えています。非フィクス映像を制作し公開することは、先に述べた立直する視聴者の範囲が広がることだけではなく、本家映像のコピーと表現をしていることであり、れっきとしたコピユニ活動の一つだと言えます。ただ制作して公開せずにユニット内で終わらせるのは意味がなく、ダンスと同様に作品という性質を持つ映像も、公にすることがいかに重要かは言うまでもないでしょう。
問題点と目標の整理
ここで一旦、何が問題で、何を以て解決となるのかを整理し、具体化しましょう。
まず課題は:
マスクをつけたり、顔にモザイクをかけるような方法では、顔起点の表現が失われる
かといって顔を出したら本末転倒
このトレードオフを解決できないか?
と言うことでした。
このことをもう少し問題を具体化します。
まず顔画像から個人を特定できるようなアイデンティティを分離させることを顔の匿名化と呼びます。
顔の匿名化で失われる顔起点の表現とは具体的に何でしょうか?それは目、鼻、口、頬などの顔のパーツの形からなる表情と、その表情の変化だと言えるでしょう。さらに顔の向きや、照明のあたり具合も、印象を左右するため重要でしょう。このような顔の表情や向き、照明条件を知覚情報と呼ぶことにします。
よって、動画における、顔の匿名化(Face De-Identification)と、知覚情報(Perception)の維持が、目標となります。
関連手法や事例
顔画像の匿名化

(画像引用元:Juels, Ari. "RFID security and privacy: A research survey." IEEE journal on selected areas in communications 24.2 (2006): 381-394.)
顔画像の匿名化は古くから研究されています。最もナイーブな方法はマスクをつけることでしょう。(ここでマスクとは、顔につける布のマスクでなく、ぼかしやモザイクなどの画像データに重ねられるものを指します。)
上の図は簡単なマスクの例です。上図は全体的にぼかしがマスクされていますが、Google mapのStreet viewのように、画像中から顔を検出してその顔部分だけをマスクすることも可能です。(Frome, Andrea, et al. "Large-scale privacy protection in google street view." 2009 IEEE 12th international conference on computer vision. IEEE, 2009.)
しかしそれら方法では顔の匿名化ができても知覚情報の維持ができません。
Deepfakeの1つ、Face swappingによる匿名化と知覚情報の維持
知覚情報を維持した匿名化のためには、匿名化したい顔(キャストの顔)を別人ないしはこの世に存在しない生成された顔に置き換えることが有効であると言えます。Deepfakeは、これを可能にする技術の一つと言えるでしょう。
Deepfake(ディープフェイク)とは、「ディープラーニング」と「フェイク(偽物)」の合成語です。これは、高度なコンピュータグラフィックスとAIアルゴリズムを使用して、人の顔、声、または表情を画像やビデオの中で別の人物のものに置き換える技術です。(参考:Chadha, Anupama, et al. "Deepfake: an overview." Proceedings of Second International Conference on Computing, Communications, and Cyber-Security: IC4S 2020. Springer Singapore, 2021.)
最近はDeepfakeを悪用した、フェイクニュースや動画の拡散に関する話題を散見します。代表例として、以下のような岸田首相のフェイク動画も、Deepfake技術によって生成されたものです。
Deepfake技術のうち、とりわけ顔を別人の顔に置き換える技術を、おおよそ総じてFace swappingやFace swapと呼ばれています。(Bitouk, Dmitri, et al. "Face swapping: automatically replacing faces in photographs." ACM SIGGRAPH 2008 papers. 2008. 1-8.)
Face swappingは以下の図のように、顔を置き換えたい対象(Target)と、置き換える顔(Source)をAIに与えることで、Target中の顔がSource顔に置き換えれたフェイク画像を出力します。また、動画は画像の連続なので、動画中のフレームごとにこの処理を行うことで、動画に対しても顔を置き換えることができます。
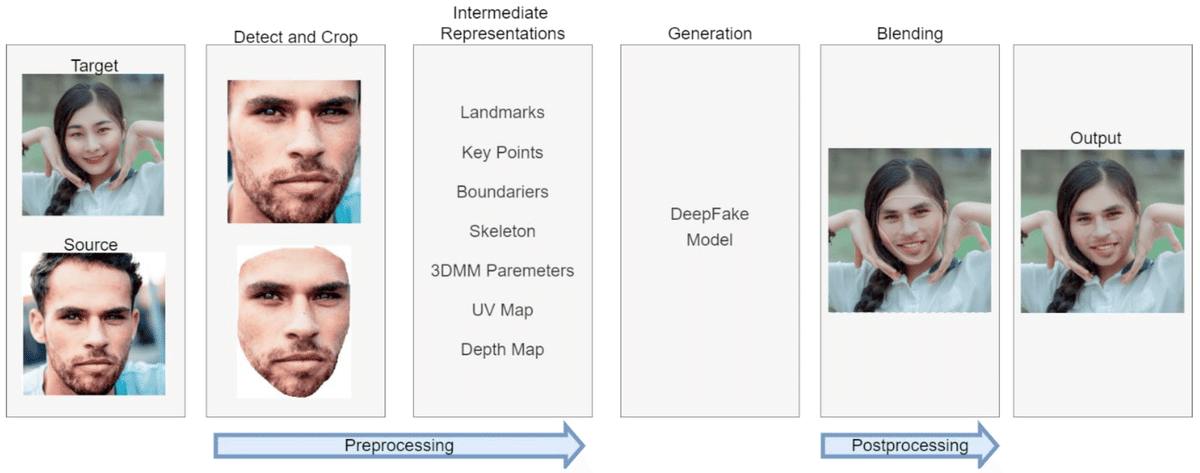
(画像引用:Walczyna, Tomasz, and Zbigniew Piotrowski. "Quick Overview of Face Swap Deep Fakes." Applied Sciences 13.11 (2023): 6711.)
Face swapの代表的な手法の一つに、GHOST(Groshev, Alexander, et al. "GHOST—a new face swap approach for image and video domains." IEEE Access 10 (2022): 83452-83462.)という手法があります。
GHOSTとはGenerative High-fidelity One Shot Transferの略で、2段階構成のモデルとなっています。1段目はTargetから目の向きや鼻の形や照明具合などの属性情報を抽出するAttribute Encoderモジュールです。2段目は、1段目のAttribute Encoderから出力される属性特徴と、Sourceから抽出される個人を識別できるようなアイデンティティ情報を入力に取り、顔が置き換えられたFake画像を出力します。
このモデルは敵対的生成ネットワーク(GAN)と呼ばれるアルゴリズムで学習されます。GANとは、Fake画像を生成することがんばるEncoderと、Fakeか否かを識別するDiscriminatorからなっています。EncoderはDiscriminatorを騙せられることを目指して、Discriminatorはより正確にFakeを識別できることを目指して、それぞれのパラメータを学習します。このような敵対的構造を持たせることで、より自然な画像が生成されるわけです。
詳細は以下をご覧ください。

(画像引用:Groshev, Alexander, et al. "GHOST—a new face swap approach for image and video domains." IEEE Access 10 (2022): 83452-83462.)
図の説明:
$${X_s}$$はソース画像、$${X_t}$$ はターゲット画像である。 青いAtrribute Encoderは、$${X_t}$$ から目や耳や鼻などの属性特徴を抽出する。緑のAAD Generatorは$${X_s}$$からの個人を識別するアイデンティティ特徴と、Atrribute Encoderの出力を入力に取り、Fake画像$${\hat{Y}_{s,t}}$$を出力される。Discriminatorは$${\hat{Y}_{s,t}}$$と$${X_s}$$を受け取って、Fakeか否かを識別する。これらはGANで学習されるとともに、より自然なFake画像を生成するための工夫が加えられている。
このモデルの2段階構造のベースはFaceShifterという先行研究です。(Li, Lingzhi, et al. "FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping." In CVPR (2020).)その一方でGHOSTの新規性となっているのは、目の向きも考慮して画像を生成するためのAIの学習指標(損失関数)の導入や、より自然な合成顔画像を実現するためにブレンド(Target顔にSource顔を重ねること)するときにSource顔の輪郭にガウスぼかしを加えること、などがあります。

(画像引用:Groshev, Alexander, et al. "GHOST—a new face swap approach for image and video domains." IEEE Access 10 (2022): 83452-83462.)

(画像引用:Groshev, Alexander, et al. "GHOST—a new face swap approach for image and video domains." IEEE Access 10 (2022): 83452-83462.)
Face swappingによる知覚情報維持の限界
今回の目標である、顔の匿名化と知覚情報の維持にとても密接な関連を持つ手法が、Facebook(現meta)によるLive Face De-Identification in Videoです(Gafni, Oran, Lior Wolf, and Yaniv Taigman. "Live face de-identification in video." Proceedings of the IEEE/CVF ICCV. 2019.)。
著者のGafniらは先述のFace swappingによる動画での顔の匿名化には、そもそもFace swappingが失敗することが多く、完全な顔の匿名化が難しいという課題があると指摘しています。そのような失敗を避けるためには、SourceとTargetが似た顔構造を持っている必要があるとも主張しており、たとえば日本人と欧米人間のSwappingが難しいと言うことです。
このような課題に対処しつつ、ポーズや照明、表情などの知覚情報を固定したまま、アイデンティティを最大限に非相関化するEncoder・Decoderモデルが提案されています。
またこの手法では匿名化時に、動画中の任意の人物の顔をTargetとします。その時のSourceは、検出された顔と特徴が離れた顔を算出して扱います。具体的には、まず平均的な顔画像があり、それに対してTargetがどの程度違うのか(例えば平均より程度$${x}$$くらい目が細い)を計算し、Sourceにはその真逆の画像(例えば平均より程度$${x}$$くらい目が大きい)を使う、ようなことをしています。ざっくりといえばですが。
(以下は、次のセクションまで読み飛ばしていただいて大丈夫です)
モデル構造は以下の図の通りです。特徴的なのことは、顔の違いを符号化できる学習済み顔画像分類器からの特徴量が、Fake画像生成のための特徴表現として加えられていることです。これにより、モデルが学習時に見たことのない顔画像がテスト時に入力された場合、例えば学習データに含まれていなかった日本人の顔がきても、自然なFake画像を生成できるようになりました。
モデルはGHOSTと同様敵対的ネットワークにより学習されますが、さらにEncodeには、知覚情報はより残しつつもアイデンティティをより分離できるように学習指標(損失関数)が追加されています。
詳細は以下をご覧ください。(正直この理解で合ってるか自信はありません……。正直いまいち腑に落ちてないです。)

(画像引用:Gafni, Oran, Lior Wolf, and Yaniv Taigman. "Live face de-identification in video." Proceedings of the IEEE/CVF ICCV. 2019.)
図の説明:
(a)学習時は、ランダムなスケーリングや回転などでaugmentされたSourceと、オリジナルのSourceと一致するTargetを用いる。Souce画像はEncoder(左側の右に狭くなっている台形部分)で特徴ベクトル$${Z}$$に、Target画像は顔分類器によりアイデンティティと対応するFace Discriptor特徴量に、それぞれ抽出される(中央灰色部分)。その二つの抽出された特徴量は一つのベクトルとして結合され、Decoder(右側の右に広がっている台形部分)の入力となる。DecoderはMask画像$${m}$$とUnmasked画像$${z^{raw}}$$を出力する。最後にSource画像とUnmasked画像をMask画像を使って合成し、Masked画像$${z^{masked}}$$を得る(右の×や+が書かれている部分)。
(b) Encoderが知覚情報を維持しつつアイデンティティを分離できるように、Encoderの各レイヤーについて損失が与えられる。具体的には、入力画像$${x}$$と出力画像$${z^{raw\_ \text{or}\_ masked}}$$の各活性化マップ間の表情、ポーズ、照明条件を維持するための最小化($${\mathcal{L}^{x,z}}$$)、ターゲット画像$${t}$$と出力画像$${z^{raw \_\text{or}\_masked}}$$の各活性化マップ間のアイデンティティ特徴を近づけるための最小化($${\mathcal{L}^{t,z}}$$)、そしてターゲット画像$${t}$$と出力画像$${z^{raw\_\text{or}\_masked}}$$間のアイデンティティ特徴を遠ざけるための最大化($${\mathcal{L}^{x,z}}$$)である。
本稿で取り組んだこと
さて、Face swapping手法のGHOST(IEEE Access 2022)は、顔匿名化と知覚情報維持に使えそうに思えた一方で、Gafniら(ICCV 2019)の研究ではFace swappingは顔匿名化に向いていないと主張されています。この主張は、Gafniら(ICCV 2019)より後に発表された最近の研究であるGHOST(IEEE Access 2022)でも言えることなのでしょうか?GHOSTはGafniら(ICCV 2019)の研究を論文中で引用していないので、この関係も気になるところです。
また、本稿で対象しているドメインは動画、とりわけ被写体が踊っている非フィクス映像を対象としています。多彩な表情、多彩な角度からなるコピユニの動画にも適応できるのでしょうか?
そこで本稿では、GHOSTの実装を実際に動かして、コピユニ動画に対してFace swappingによる顔の匿名化を試んだ結果を報告します。
(本当はGafniら(ICCV 2019)の手法も動かしたかったのですが、実装が公開されていなさそうだったので、時間の都合断念)
実験
実験設定
本実験ではSourceとターゲットの組み合わせについて、2通りの組み合わせを用います。
簡単な例として、Sourceにフリー素材の男性の画像、Targetにフリー素材の踊っている女性の動画を使用。踊っている女性の顔を男性の顔に置き換える。

実問題の例として、Sourceにフリー素材の女性の画像、TargetにLLコピユニダンサーの穂樽が踊っている動画を使用。踊っている穂樽の顔を別の女性の顔に置き換える。

実問題例の設定では、穂樽にご協力をお願いし、実験での利用許諾の許可をいただきました。穂樽は元ツクライブ!のキャストで、今はCOLORでも活動している、LLコピユニダンサーです。
穂樽ちゃん協力ありがとう!!!
モデルはVGGFace2(Cao, Qiong, et al. "Vggface2: A dataset for recognising faces across pose and age." 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). IEEE, 2018.)で学習済みのGHOSTを使った。GHOSTのAttribute Encoderのモデル構造はUNet(Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." MICCAI 2015: 18th International Conference, Proceedings, Part III 18. Springer International Publishing, 2015.)のものを利用した。こちらで公開されている。
簡単な設定例での結果
Sourceデータ(フリー素材の男性顔画像)とTargetデータ(フリー素材の踊っている女性顔画像)、およびオリジナルの動画を以下に示します。
そして男性の顔で置き換えた踊る女性のfake動画は以下のようになりました:
生成結果とオリジナルを表情の変化の観点で見比べると、ちゃんと表情の変化を残して顔を置き換えることに成功しています。プライバシーの観点でも、生成結果の全フレームでオリジナルの女性の顔は隠れているようなので、上手くいったと言えるでしょう。
実問題の設定例(穂樽の例)での結果
Sourceデータ(フリー素材の女性顔画像)とTargetデータ(穂樽の顔画像)は以下のペアです。本当は鈴木愛奈さんで置き換えた例も見せたいんですが、それこそプライバシーの関係があるので、小原鞠莉の文脈で欧米人の顔画像を使いました。
そして生成された結果が以下の通りです。左側がオリジナルの動画、右が顔が置き換わって生成された動画です。前半等倍速を2回、後半は0.5倍速が2回、ループします。
ちゃんと表情も伝達していますね。一見上手くいっていそうに見えます。
しかしよく見ると、いくつかのシーンでは顔の置き換えに失敗ているケースがあります。以下の図はその1シーンです。

この結果は、顔の置き換えが完全になっていないので匿名化に失敗したことを意味しており、許容できません。おそらくこの1動画の中で、顔に対する様々な照明パターンがあり、失敗した時の照明パターンは与えられたTarget画像の顔と同じ顔ではないと判定されてしまったからでしょう。
Target画像追加による、実問題の設定例(穂樽の例)での改良結果
GHOSTモデルが潜在的に、同じ人物でも照明条件が違うことで別人と判定しているのであれば、ユーザーサイドも別人として扱えば良いのではと考えられます。すなわち、顔の置き換えに失敗した時の顔画像をTargetとして追加することが有効かもしれません。
そこで、以下の図のように、SourceとTargetのペアを増やしました。

この時の生成された結果が以下の通りです。左側が改良前の生成動画、右がTarget追加による改良後の生成動画です。
Targetを増やしたことで、動画中の全フレームが、欧米人女性の顔に置き換わっていることがわかります。実際、先の改良前で失敗していたシーンも顔の置き換えに成功しています。

結論
顔を他の人に変えることで、匿名化をしつつ表情の変化を残せました。
Gafniら(ICCV 2019)が主張したように、Face swappingによる匿名化は一般的には完全ではないものの、対処療法的にTargetを追加することで、与えられた動画中の顔の匿名化には成功しました。一方で、そうであれば最初から動画中の全ての顔をTargetに指定する方が事は早いと思われます。しかし9人のキャストが踊っている動画中の全員が、匿名化を希望するとは限らないので、やはりTargetを指定できた方が、コピユニ匿名化の文脈では扱いやすいかもしれません。
また今回は被写体は1名の設定でしたが、被写体が増えた場合はどうなるかは非自明です。加えて、元動画が結構ちゃんとした設定でちゃんと高画質で撮れたものを扱っていたので、より激しい照明演出下での動画やスマホ撮影の動画で、どれくらい扱えるかもまだわかりません。
まとめと感想
いかがでしたか?
LLコピユニアドベントかレーダーのはずが、なんだかコンピュータビジョンのアドベントカレンダーみたいになってしまいました。むしろこれに肉付けすれば卒論くらいにはなるんじゃないかという気すらします。
実は私はDeepfake技術は教科書程度の知識しかなかったので、このアドベントカレンダーに合わせて、この記事の投稿の2日前の夜から最新研究のサーベイを始めて、勉強をし、実験し、本稿を書き上げました。先に申した通り今は旅行中で、移動中の列車内や飛行機やホテルでやっていました。特に昨日は夜日本酒飲んだ後にGafniら(ICCV 2019)の論文を読みすすめたので、全く意味が分からず半分諦めて、青森の夜の街を徘徊していました。。。(今は秋田のホテルです。)
でもおかげで、Deepfake、face swappingの良い勉強になりました。アドカレの機会を設けてくれて、直に「やれ(意訳)」と言い、実験の協力までしてくれた穂樽にはお礼を申し上げます。
今回紹介したような手法を使い、積極的にカメラワークの本家コピーや映像表現、それでいて匿名化しつつと表情管理の表現を欠損させない、ベターなコピユニ作品が生まれていくことを願っています。
大学のLLコピユニであれば、今回のDeepfakeくらい実装して動かせる人間の一人や二人いると思うし、むしろやりたいと思ってる潜在的エンジニアが多いと思います。LLコピユニはキャストのみならず技術員や事務もその活動の中で成長できる素晴らしい活動の一つです。ぜひ自分の団体で起きてる未解決課題、保留課題を、テクノロジーなどを使った解決にトライしてみてはいかがですか?