
geopandasとfoliumでインタラクティブなヒートマップを作ってみた!

こちらは株式会社PREVENTのアドベントカレンダーの記事です。
こんにちは!株式会社PREVENTのデータサイエンス部でデータアナリストとして在籍している、代島と申します!今回はPythonを使った「ヒートマップ」分析について、語っていきたいと思います!
インタラクティブなヒートマップを作るまで
そもそもヒートマップって何のために使うの?
ヒートマップの定義には色々とあるかと思います。例えばいくつもの変数の相関係数をクロスして可視化したヒートマップもあります。しかしこの記事で取り上げるのは「地図上にカラーマップを描画するもの」です。これは主に地域間における違いを可視化するのに使われるものです。
geopandasだけでは足りないもの
地図データをPythonで扱う代表的なライブラリといえば「geopandas」があります。
もちろんこのライブラリだけでも十分キレイなヒートマップを地図上に描くことが出来ます。では一体何が足りないというのか。それはインタラクティブな機能です。Googleマップに代表されるように、多くの地図アプリは拡大縮小、移動が可能です。しかしgeopandas単体で出力されるヒートマップは単一の画像データです。これでは細かい部分を拡大したり、マウスをホバーして詳細情報がポップアップさせたりすることはできません。全体の情報を俯瞰したいときは、geopandas単体の機能で十分かもしれません。しかしより深く情報をドリルダウンしていく場合、どうしても足りない部分が出てきてしまします。
Googleマップみたいにヒートマップを描く手がかり
私の中でこの問題を解決するきっかけを与えてくれたのが下記の記事です。
この記事では、foliumというライブラリが作り出す動的地図にヒートマップを描きこんでいく様子がまとめられています。geopandasの他にここで使用されているfoliumというライブラリは下記に紹介されています。
ダッシュボードのようなインタラクティブなヒートマップを作りたい
ここまで来ると、もっと機能を充実させたくなります。つまり、BIで作られるダッシュボードにあるヒートマップのように、マウスをホバーさせれば詳細情報が表示され、該当地域の色が変化する機能だったり、自由に拡大縮小できる機能です。そして最終的には、そんなインタラクティブなヒートマップを「単体の」ファイルとしてブラウザで閲覧できるようにしたいという思いが湧いてきました。
ここから具体的な作成手順の紹介に移りますが、以降のPythonスクリプトは生成AIを駆使しながら書いていったものです。
インタラクティブなヒートマップを作る手順
使用するデータ
今回はこちらで紹介されているように、政府統計の総合窓口e-Statからデータを探します。
今回は株式会社PREVENTの所在地である愛知県のデータを使用しました。ダウンロード元のページはこちらです。このページにおける「23000 愛知県全域」のShapefileをダウンロードしました。このファイルを解凍し、現れるファイル全てをPythonのアクセスできるディレクトリに格納します。ここで大切なのが「ファイル全て」です。実際にPythonスクリプトに記述するのは「shp」という拡張子のファイルだけなのですが、他のファイルもshpファイルと同じディレクトリに無いとうまく動作しません。例えば下記のように同じディレクトリに格納します。
/kaggle/input/aichi-prefecture-map-data/r2ka23.dbf
/kaggle/input/aichi-prefecture-map-data/r2ka23.shp
/kaggle/input/aichi-prefecture-map-data/r2ka23.shx
/kaggle/input/aichi-prefecture-map-data/r2ka23.prj今回のヒートマップ作成にはKaggleのジュピターノートブックを使用しています。そのため、「/kaggle/input/」の配下にデータを格納しています。
データの読み込みと加工
先ほど記載した4つのファイルのうち、shpファイルのみをスクリプトで読み込みます。
import geopandas as gpd
# Loading geographic data
gdf_aichi = gpd.read_file("/kaggle/input/aichi-prefecture-map-data/r2ka23.shp")このようにして読み込んだデータには「丁目単位」の住所データが格納されています。ただ、都道府県単位(今回は愛知県)の規模に「丁目単位」のエリアを描くとなると、かなり見づらいものになってしまいました。
住所の統合
そこで行ったのが「住所の統合」です。「AAAAXX丁目」となっている住所を「AAAA」と「XX丁目」に切り分け、「AAAA」でグループ化を行います。このようにエリアの最小単位を少し大きくすることで、全体的な見やすさとパフォーマンスの改善ができました。
import numpy as np
import re
from shapely.ops import unary_union
# Separate the address "AAAAXX丁目" from "AAAA" and "XX丁目".
def extract_address_prefix(address):
pattern = r"(.+)[一二三四五六七八九十]+丁目"
match = re.match(pattern, address)
if match:
return match.group(1)
else:
return address
# Newly defined area name
gdf_aichi['S_NAME_2']=gdf_aichi['CITY_NAME']+'_'+np.vectorize(extract_address_prefix)(gdf_aichi['S_NAME'].astype(str))
# Grouping process with newly defined area names.
# Group aggregation and, at the same time, integration of map data.
gdf_aichi_grouped=gpd.GeoDataFrame(gdf_aichi.groupby(['PREF_NAME','CITY_NAME','S_NAME_2']).agg({
'AREA':'sum',
'SETAI':'sum',
'JINKO':'sum',
'geometry':unary_union # Polygon merging
}).reset_index(),geometry='geometry', crs=gdf_aichi.crs)ここでは列PREF_NAMEに都道府県名、CITY_NAMEに市区町村名、S_NAMEに丁目単位の住所、AREAに面積(m2)、SETAIに世帯数、JINKOに人口が格納されています。ここで関数extract_address_prefixによる住所分離を行い、新たな列「S_NAME_2」にその結果を格納します。
この新しい列S_NAME_2を使い、今度は地図データを統合していきます。同時に他の列はグループ集計を行っています。どちらもpandasデータフレームのgroupbyで同時にグループ処理が可能です。pandasデータフレームには地図データを扱う関数はありませんが、ライブラリshapely.opsに含まれるunary_union関数により地図データを結合できました。
geopandasデータをgroupbyで処理するときには一つ注意点があります。それは返される値がpandasデータフレームということです。そのため、geopandas.GeoDataFrameでgeopandasデータフレームに戻してあげる必要があります。
ヒートマップにする変数の作成
今回はこちらで紹介されていた「人口密度」を可視化していきます。また「世帯数」のデータもあったので、「1世帯あたりの平均人数」も可視化していきます!果たして、どんなヒートマップが出来上がるのでしょうか?ワクワクしますね😆
# Calculate population density
gdf_aichi_grouped['POP_DENSITY_PER_1KM2_MAX40000']=(gdf_aichi_grouped['JINKO']/gdf_aichi_grouped['AREA']*1000000).apply(lambda x:min(int(x),40000))
gdf_aichi_grouped['CNT_PER_SETAI_MAX10']=(gdf_aichi_grouped['JINKO']/gdf_aichi_grouped['SETAI']).apply(lambda x:min(x,10))上記のように人口密度と1世帯あたりの平均人数を定義していますが、どちらも一部が突出して大きな値を取るため、このままではうまくヒートマップが描かれません。そこで両者に上限値を設け、全体のヒートマップがバランスよく描かれるようにしました。
さて、あと3ステップでインタラクティブなヒートマップが完成します。どうかお付き合いをお願いします🙏
関数1:中心座標と倍率の最適化
この2つの最適化は、folliumライブラリで地図上にヒートマップを描く際に重要になります。geopandas単体で作られたヒートマップでは、描かれたヒートマップのみが出力画像の中心に位置しています。これに対してfoliumライブラリでは中心座標と倍率を引数で指定する必要があります。毎回手動で調節するのもいいですが、今回は自動で調整されるようにしてみました。
import folium
def optimize_map_param(gdf):
# Create Folium maps.
# Determinate the map centre coordinates (e.g. near the centre of the data)
# Get bounding boxes for the entire map.
bounds = gdf.total_bounds
[[min_lon, min_lat], [max_lon, max_lat]] = [[bounds[0], bounds[1]], [bounds[2], bounds[3]]]
# Calculate centre coordinates
center_lon = (min_lon + max_lon) / 2
center_lat = (min_lat + max_lat) / 2
# Calculate the optimum zoom level.
m = folium.Map(location=[center_lat, center_lon], zoom_start=10, tiles="cartodbpositron")
m.fit_bounds([[min_lat, min_lon], [max_lat, max_lon]])
zoom_start = m.options['zoom']
# Create a new Folium map object.
m = folium.Map(location=[center_lat, center_lon], zoom_start=zoom_start-1)
return mこの関数では、中心座標と倍率が最適化されたfoliumマップオブジェクトが返されます。geopandasデータフレームの関数から地図データの四隅から最大と最小の緯度と経度を取得します。これらから中心座標を取得することが出来ます。この座標を使い、適当な倍率で一度foliumマップオブジェクトを取得したあと、このオブジェクトのoptions['zoom']から最適な倍率が得られます。そして改めてこれらの中心座標と倍率でfoliumマップオブジェクトを取得することで、最適化された中心座標と倍率のfoliumマップオブジェクトを取得できます。
ただしこのfoliumマップオブジェクトは中心座標と倍率が設定されたただの地図(何も情報を入力していないGoogleマップのようなもの)です。ここから先程のgeopandasデータフレームを反映させていきます。
関数2:foliumマップにgeopandasデータを反映させる
def total_colormap_func(gdf,data_column,m_):
# Creating a colormap (using matplotlib's cmap)
# Minimum and maximum data values.
vmin = gdf[data_column].min()
vmax = gdf[data_column].max()
cmap=plt.cm.rainbow
# Colour maps converted for use in Folium.
colormap = LinearColormap([matplotlib.colors.to_hex(cmap(i)) for i in range(cmap.N)], vmin=vmin, vmax=vmax, caption=f'Distribution of {data_column}')
# Define style functions
def style_function(feature):
value = feature['properties'][data_column]
if pd.isnull(value):
normalized_value=0
hex_color = '#000000'#.format(*rgb)
else:
normalized_value = (value - vmin) / (vmax - vmin) if (vmax - vmin) > 0 else 0
rgba = cmap(normalized_value)
rgb = tuple(int(x * 255) for x in rgba[:3])
hex_color = '#{:02x}{:02x}{:02x}'.format(*rgb)
return {
'fillColor': hex_color,
'color': 'black',
'weight': 0.1,
'fillOpacity': 0.5,
'transition': 'fill-color 2s linear',
'stroke': True,
}
def highlight_function(feature):
return {
'color': 'yellow', # 反転時の境界線の色
'weight': 3,
'fillOpacity': 0.9,
'transition': 'fill-color 2s linear',
'stroke': True,
}
# Adding a GeoJSON layer to Folium.
folium.GeoJson(
gdf.__geo_interface__,
name='行政区別データ',
style_function=style_function,
highlight_function=highlight_function,
tooltip=folium.GeoJsonTooltip(fields=['S_NAME_2', data_column], aliases=['place_name', data_column ])
).add_to(m_)
return colormapここで定義されている関数total_colormap_funcによって、次のことを行っています。
1)geopandasの可視化対象データの最大値と最小値を取得
2)matplotlib.pyplotからレインボーのcmapを取得
3)上記最大値と最小値からカラーマップを作成
この3つを行っているのが関数total_colormap_funcの下記の部分です。
# Creating a colormap (using matplotlib's cmap)
# Minimum and maximum data values.
vmin = gdf[data_column].min()
vmax = gdf[data_column].max()
cmap=plt.cm.rainbow
# Colour maps converted for use in Folium.
colormap = LinearColormap([matplotlib.colors.to_hex(cmap(i)) for i in range(cmap.N)], vmin=vmin, vmax=vmax, caption=f'Distribution of {data_column}')
ここで最後にcolormapという変数が出現していますが、これは最後にカラーバーのスケールを表示するのに使います。その他のvminとvmaxが可視化対象データの最大値と最小値ですが、これらを使って可視化対象データの標準化を行っていきます。
さて、今度はgeopandasデータの個々のデータに色を設定していくのがstyle_function関数です。
# Define style functions
def style_function(feature):
value = feature['properties'][data_column]
if pd.isnull(value):
normalized_value=0
hex_color = '#000000'#.format(*rgb)
else:
normalized_value = (value - vmin) / (vmax - vmin) if (vmax - vmin) > 0 else 0
rgba = cmap(normalized_value)
rgb = tuple(int(x * 255) for x in rgba[:3])
hex_color = '#{:02x}{:02x}{:02x}'.format(*rgb)
return {
'fillColor': hex_color,
'color': 'black',
'weight': 0.1,
'fillOpacity': 0.5,
'transition': 'fill-color 2s linear',
'stroke': True,
}この関数の中で先程の可視化対象データが標準化され、それらを16進数カラーコードに変換しています。このカラーコードをCSSスタイル形式の一部に組み込むことで、可視化対象データ一つに対するヒートマップの設定が完成します。
ただこのままだと、実際にヒートマップを閲覧するとき、自分はいまどのエリアを見ているのかがはっきりしないことがあります。そこでマウスの先端が対象エリアのヒートマップに触れると、その色が変わる仕掛けをしたいと思います。それが次に説明する関数highlight_functionです。
def highlight_function(feature):
return {
'color': 'yellow', # 反転時の境界線の色
'weight': 3,
'fillOpacity': 0.9,
'transition': 'fill-color 2s linear',
'stroke': True,
}この関数では、先程と同様にCSSスタイル形式の辞書変数が関数の戻り値として定義されています。しかし先ほどとは異なり、マウスが触れたときに変化させたい項目だけがCSSスタイル形式の辞書変数として格納されいます。この内容でマウスをホバーすると、境界線の色が黄、太さが3、透過度が0.9に変化します。
さて、これでヒートマップの色に関する定義は完了したので、いよいよfoliumマップオブジェクトに情報を追加していきます。
# Adding a GeoJSON layer to Folium.
folium.GeoJson(
gdf.__geo_interface__,
name='行政区別データ',
style_function=style_function,
highlight_function=highlight_function,
tooltip=folium.GeoJsonTooltip(fields=['S_NAME_2', data_column], aliases=['place_name', data_column ])
).add_to(m_)上記ではfoliumインスタンスのGeoJson関数に地図データとこれまでの2つの関数「style_function」と「highlight_function」を引数として設定します。GeoJson関数で処理した結果をfoliumマップオブジェクトの「m_」に渡すことで、foliumマップへヒートマップが反映されます。
関数3:foliumマップへのカラーバーの追加
先程の手順でヒートマップ自体は完成するのですが、
def color_bar_setting(colormap,ticks,m_):
# Add a color bar
colormap.tick_labels=ticks
colormap.add_to(m_)
f_size=15
style = """
<style>
.legend {
font-size: """+str(f_size)+"""px;
position: absolute;
top: 10px;
right: 10px;
z-index: 9999;
background: white;
padding: 2px;
margin-bottom: 10px;
border: 2px solid grey;
border-radius: 5px;
}
.legend .caption {
font-size: 14px;
}
</style>
"""
m_.get_root().html.add_child(folium.Element(style))ここでは前に出てきた「colormap」をfoliumマップオブジェクトに埋め込みます。変数colomapはそのメソッドadd_toで引数にfoliumマップオブジェクトを設定すればよいだけなのですが、それだと見た目がイマイチ(背景色が透明のため、後ろのマップに紛れ込んでしまう)でした。そこでスタイルシートの情報をfoliumマップオブジェクトに追加し、背景色と境界線の書式設定を行いました。これで背景に紛れることなく、はっきりとカラーバーを表示することが出来ました。
いよいよインタラクティブなヒートマップを表示!
さて、ここまで定義してきた3つの関数をまとめて実行することで、いよいよインタラクティブなヒートマップの表示です!「人口密度」と「1世帯あたりの平均人数」をそれぞれ表示していきます!
まずは「人口密度」から!
# Name of the column of data to be visualised
data_column_ = 'POP_DENSITY_PER_1KM2_MAX40000'
m_map=optimize_map_param(gdf_aichi_grouped)
colormap_=total_colormap_func(gdf_aichi_grouped,data_column_,m_map)
color_bar_setting(colormap_,[10000,20000,30000],m_map)
# Display the map in the output cell of Jupyter Notebook.
display(m_map)上記のスクリプトを実行して表示されるヒートマップがこちらです!(ここに貼り付けると、インタラクティブでなくなってしまうのがもどかしいです😂)
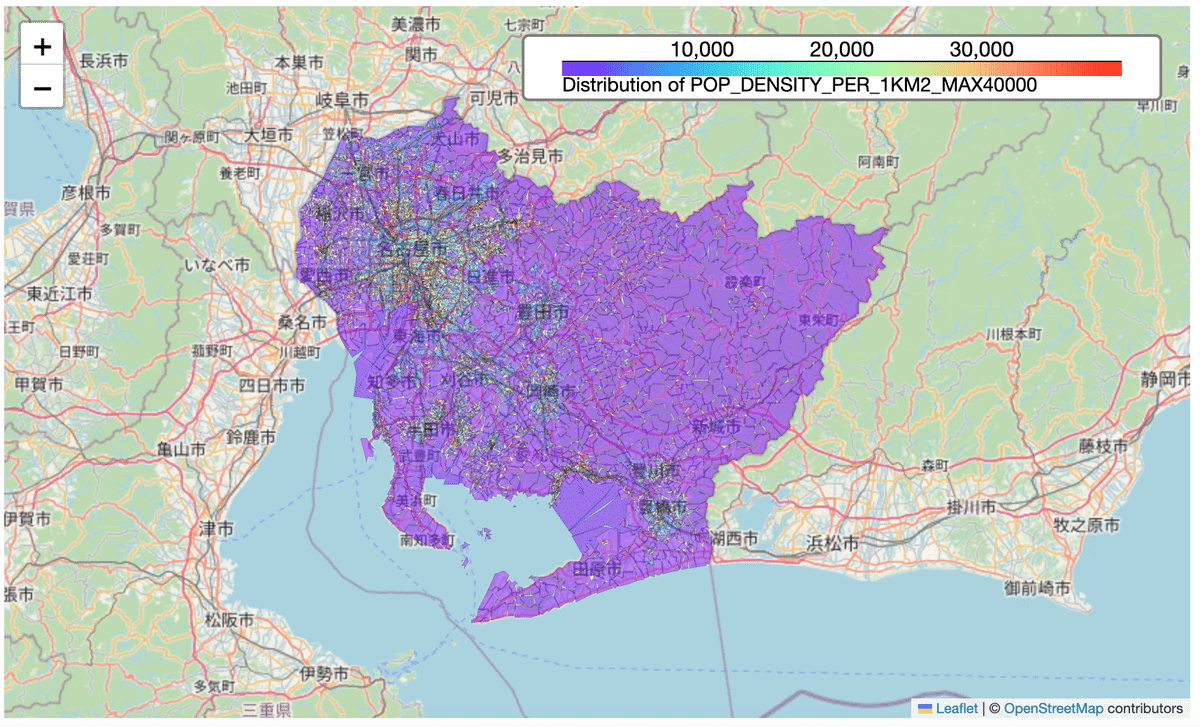
続いて「1世帯あたりの平均人数」を表示していきます!
# Name of the column of data to be visualised
data_column_ = 'CNT_PER_SETAI_MAX10'
m_map2=optimize_map_param(gdf_aichi_grouped)
colormap_=total_colormap_func(gdf_aichi_grouped,data_column_,m_map2)
color_bar_setting(colormap_,[2,4,6,8,10],m_map2)
# Display the map in the output cell of Jupyter Notebook.
display(m_map2)上記を実行するとこうなります!(同じく静止画になってしますが、、、😭)

やっぱり静止画になってしまうとなかなか伝えづらいものです😭実際に動かせるKaggleジュピターノートブックのリンクを貼り付けておきますので、ぜひ触ってみてください!またこのノートブックはブラウザ上で複製できるので、(地図データは各自ご用意頂く必要ありますが)実際にPythonを動かしてみることもできます!
シェアしよう!
最後にですが、ここで作ったインタラクティブなヒートマップをファイルに書き出すことが出来ます!しかもhtmlファイルなので、特別な環境は不要です!ぜひ皆さんも作ってシェアしてみてください!
# Save the map as an HTML file.
m_map.save("/kaggle/working/Population_density_heatmap_by_address.html")
m_map2.save("/kaggle/working/cnt_per_setai_max10_by_address.html")おわりに
ここまで読んで頂き、ありがとうございました🙇♂️
インタラクティブなヒートマップ、いかがでしたでしょうか?ぜひみなさんも実際に触って、その面白さを体感してみてください!