
[データ分析基盤構築記 ~ETL基盤編~] Embulk + Fargate + Step FunctionsでサーバーレスでスケーラブルなETL基盤を作ってみた

自己紹介
初めまして!株式会社PREVENTのデータサイエンス部でデータエンジニアとして活動している俵です。
データサイエンス部には3つの職種(データサイエンティスト、データエンジニア、データアナリスト)がありますが、主にデータ分析基盤の設計・構築・運用を担うのがデータエンジニアの役割です。
今回、私がPREVENTに入社して最初に取り組んだETL基盤の新規構築について紹介します。
データ分析基盤とは
そもそもデータ分析基盤とは何か。
その昔、データサイエンティストが社内のデータを分析する際は、本番環境のデータをそのままローカルPCに落としたり、或いは本番環境でクエリを実行して分析していました。
しかし、データ分析に対する需要やデータ量の増加、またセキュリティ要件の高まりなどからデータ分析に適した専用の環境が望まれるようになり、これをデータ分析基盤と呼ぶようになりました。

ETL基盤とは
データ分析基盤は、一般にETL(ELT), データレイク, データウェアハウス(DWH), データマート, BI・ダッシュボードなど、様々な要素から構成されます。
今回紹介するETLは、Extract(抽出)・Transform(変換)・Load(格納)の頭文字をとったものであり、データソースからデータを抽出し、場合によっては変換し、データ分析基盤内のDB(データレイクやDWH)に格納する処理を指します。
そしてETLを実行する環境(サーバー)をETL基盤と呼びます。
私がPREVENTに入社した当初は、データ分析基盤が存在しなかったため、まずDWHとETL基盤の構築に取り掛かりました。
弊社のDWH(よろずやと命名)の設計や構築、運用については、また後日別の記事で紹介しようと思います。
ETL基盤ですが、弊社が管理するデータ(データソース)は主に複数のAmazon RDSのPostgreSQLインスタンス内に存在します。
従って、データ分析基盤についてもデータソースとの連携のしやすさ等を考慮し、AWS上に構築することとなりました。
また、DWHはデータ量やコストパフォーマンスを考慮し、データソースと同じくRDSのPostgreSQLインスタンス(Amazon RDS for PostgreSQL)で構築しました。
以上を踏まえ、次の要件を満たすETLツール・サービスの選定を行いました。
RDS Postgres→RDS Postgres間のデータ収集を1日1回以上実行できること
将来のデータや収集頻度の増加に対してスケールできること
運用にかかる工数を最小限とすること
AWSのETLサービスとして真っ先に思いつくのはAWS Glueです。
Glueは大規模データに対応したサーバーレスなETLサービスで、特にAWSの各サービスとの連携に優れています。
Glueは採用候補の1つでしたが、複雑なETL処理が可能である分スクリプトの実装コストが高く、ややオーバースペックであると考え今回の採用は見送りました。
代わりにETLツールとして採用したのがOSSのEmbulkです。
Embulk

Embulkは、言わずと知れたOSSのETLツールです。
各種データソースに対応したプラグインが豊富であり、また設定ファイルは次のようなYAMLで記述するため、実装コストが低いことが特徴です。
ユーザーが多くドキュメントが豊富であり、かつ私自身の運用経験があったことも採用の決め手となりました。
in:
type: postgresql
driver_path: {{ env.JDBC_DRIVER }}
host: {{ env.SOURCE_DB_HOST }}
port: {{ env.SOURCE_DB_PORT }}
user: {{ env.SOURCE_DB_USER }}
password: {{ env.SOURCE_DB_PASS }}
database: {{ env.SOURCE_DB_NAME }}
schema: {{ env.SOURCE_DB_SCHEMA }}
table: lifelogs
default_timezone: Asia/Tokyo
incremental: true
incremental_columns:
- updated_at
out:
type: postgresql
driver_path: {{ env.JDBC_DRIVER }}
host: {{ env.TARGET_DB_HOST }}
port: {{ env.TARGET_DB_PORT }}
user: {{ env.TARGET_DB_USER }}
password: {{ env.TARGET_DB_PASS }}
database: {{ env.TARGET_DB_NAME }}
schema: {{ env.TARGET_DB_SCHEMA }}
table: lifelogs
default_timezone: Asia/Tokyo
mode: mergeAWS Fargate
ETLツールにEmbulkを採用した次は、その実行環境の選定です。
Embulkの実行環境として、AWSのサービスではEC2やLambda, Fargateが考えられます。
それぞれのメリット/デメリットを次の表に簡単にまとめました。

実装の容易さを考えるとEC2になりますが、サーバーの管理が必要であることから運用コストが高くつくと考え、サーバーレスなサービスの利用を検討しました。
AWSのサーバーレスなコンピューティングサービスとして非常に有名なのがAWS Lambdaですが、15分という実行時間の上限が非常にネックであるため、そういった制限のないAWS Fargateを採用しました。

ETL実行環境をサーバーレスなFargateとしたことによる一番の恩恵としては、ETLジョブの並列実行が自由自在である点です。
ETLジョブは往々にして、実行頻度を当初よりも上げることがあります。
例えば、前日以前のデータだけ見れれば良かったものが、当日のデータも見たいという要望があがった場合などです。
この場合は、ETLジョブの実行頻度を毎日から毎時間などに変更する必要がありますが、この際ネックになるのがジョブの実行時間です。
仮に実行したいジョブが計10個あったとして、ジョブ1つ当たりの実行に10分かかった場合、これらを直列に実行すると10*10=100分かかるため、実行頻度を毎時間にすることができません。
こういった問題を解消する方法として、各ジョブに依存関係がなければジョブを並列に実行することが挙げられますが、EC2等のサーバー環境では難しい場合が多いです。
しかし、Fargateでは1つのジョブに対し1つのコンテナを全く別の環境で起動するイメージなので、DBの負荷にさえ気をつければいくらでも並列実行数を上げることができます。
この例でいえば、10個のジョブを全て並列実行することで全ジョブの実行時間が10分となり、毎時間の実行が可能となります。
このような分析要件の高度化やデータ量・ジョブの増加に対して非常に簡単にスケールできるのがFargateないしサーバーレスサービスの大きな利点であると感じました。
AWS Step Functions

ETLツールにEmbulk、その実行環境としてAWS Fargateを採用したら、最後はETL処理をどのように実行させるか(ジョブスケジューリング)を決めます。
古くからLinux環境で使用されているジョブスケジューラとしてはcronが有名ですが、サーバーレス環境で使えないことやETLジョブの管理に必要なリトライ・例外処理等の機能を備えていないことから、現代では専用のジョブ(ワークフロー)管理ツールを使うことが一般的です。
ジョブ管理ツールとしては、Apache Airflowやdigdagなどが有名ですが、AWSの各サービスとの連携の容易性を重視し、AWS Step Functionsを採用しました。
Step Functionsはサーバーレスなサービスであるため、運用コストを低く保てることも大きな決め手となりました。
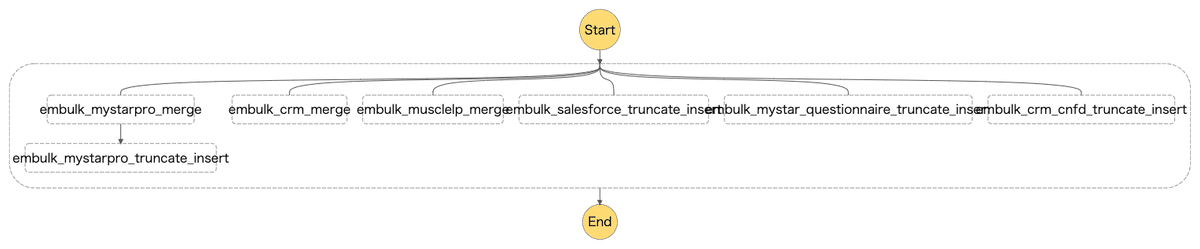
ステートマシンがネストしており、各ステートマシンに数十のETLジョブがぶら下がっている。
アーキテクチャ
こうして完成したETL基盤のアーキテクチャがこちらです。
細かい説明は省略しますが、Embulkの設定ファイル(YAML)のデプロイ自動化やEventBridgeとLambdaを介したSlackへの実行結果通知も行っており、また全てのサービスがサーバーレスな構成となっています。

これらは複数のサービスで構成されているため、一件複雑で難解なシステムに見えます。
しかし、1つのサービスが1つの機能を担うことによって、疎結合で変更に強く拡張性の高い柔軟なシステムであるといえます。
AWSは非常にサービス数が多く、こうしたサーバーレスで疎結合なシステムを構築し易いのも大きな強みであると実感しました。
まとめ
Embulk + Fargate + Step FunctionsでサーバーレスなETL基盤を構築しました。
ETL基盤は、データ分析基盤の中でもDWHやBI・ダッシュボード等と比べると地味ですが、実際は実装や運用にかかるコストの高い部分でもあります。
従って、運用コストを如何に節約するかが、特に弊社のような小規模のデータサイエンス組織にとっては重要になります。
そういった背景もあり、今回ETL基盤を新規構築するにあたってサーバーレスを念頭に置きました。
結果的にこれは大正解で、運用開始から半年以上経った現在でも特に問題はなく、最小限の工数での運用が継続できています。
私自身クラウド環境での開発が初めてということもあり、サーバーレスなアーキテクチャを選択したのは少々チャレンジングでした。
しかし、何も無い状態から新規にETL基盤の設計・構築・運用を経験できたのは非常に貴重ですし、私自身の大きな自信となりました。
今後弊社の規模拡大に伴い、データ量の増加や多様化、分析要件の複雑化などが予想されます。
そのような状況でもデータサイエンティストやアナリストが常に分析そのものに集中できるよう、ストレスの無いデータ分析基盤を堅実に、時にはチャレンジングに創り上げていきたいです!
おわりに
データエンジニアの仕事や役割について、ご理解頂けたでしょうか?
データエンジニアは非常に面白く、やりがいのある仕事です。
今後もヘルスケア企業のデータエンジニアとして発信を続けていきたいと思います!
[データ分析基盤構築記 ~DWH編~] に続く