
日本語データセットでBERTopicを使ってバーっとトピックモデリングやってみた!

PREVENTアドベントカレンダーの記事です。
PREVENT開発部がスタートさせたアドベントカレンダー。PREVENT開発チームが情報発信を盛り上げるために企画されました。この機会を見逃す手はない!ということで、データサイエンス部も参加することになりました。
いくつかの記事を執筆予定ですので、どうぞご期待ください!
おい、BERTopicってなんなんだ?
今回は、トピックモデリングライブラリ「BERTopic」を使って、日本語のデータセットを解析した体験をご紹介します。公式チュートリアルは英語のデータセットを対象としたものが多いですが、日本語データで利用する際にはいくつかの工夫が必要でした。まだ試行錯誤の段階ではありますが、初めて触れる方にとって少しでも参考になる内容になれば幸いです。
執筆担当はトッティこと戸田です。よろしくお願いします。
BERTopicとは?
BERTopicは、文章データからテーマ(トピック)を抽出するためのトピックモデリング手法です。Embeddings(埋め込み) -> Dimensionality Reduction(次元削減) -> Clustering(クラスタリング) -> Tokenizer(トークナイザー) -> Weighting Scheme(重みづけ) -> Representation Tuning(表現の調整)の6つのステップで構成されています。各ステップでライブラリをカスタムすることが可能です。
ステップの用語説明はGPT先生にお任せします。
1. Embeddings(埋め込み)
文章を数値に変換します。BERTやSentenceTransformersといったモデルを使って、文章の意味を数値ベクトルで表現します。これにより、似た意味の文章は近い位置に配置されます。
2. Dimensionality Reduction(次元削減)
埋め込みデータの次元を減らします。UMAPなどを使って、データをより扱いやすい低次元に変換し、関係性を保ちながら計算を効率化します。
3. Clustering(クラスタリング)
似た文章をグループに分けます。HDBSCANというアルゴリズムを使い、内容が似た文章を自動的に同じトピックとしてまとめます。
4. Tokenizer(トークナイザー)
グループごとに重要な単語を抽出します。日本語の場合はMeCabやfugashiなどのツールで文章を単語に分解し、各トピックを代表する単語を見つけます。
5. Weighting Scheme(重みづけ)
抽出した単語に重要度をつけます。TF-IDFという手法で、各トピックで特に目立つ単語を評価し、そのトピックを象徴する言葉を見つけます。
6. Representation Tuning(表現の調整)
トピック名やキーワードを調整します。抽出された結果を確認し、必要に応じてラベルを手動で修正することで、内容がより分かりやすくなります。
私が考えるBERTopicの特徴を整理します。
文章埋め込み技術を活用
BERTやSentenceTransformersなどの埋め込みモデルを利用し、高精度なトピック抽出を実現できる。可視化パターンが豊富
抽出されたトピック同士の関係性を視覚的に確認できるため、結果を直感的に理解できる。高いカスタマイズ性
埋め込みモデルやクラスタリングアルゴリズムを簡単に変更できるため、多様なデータセットや目的に対応できる。
日本語データで試してみる。
サクッと試したい方はぜひチュートリアルをやってみてください。CShorten/ML-ArXiv-Papersっていう英語のデータセットを使って概要を学ぶことができます。ただ、動かすだけであれば本当に簡単です。しかも、いろいろな可視化もできるので、面白いです。
そんな最高なBERTopicですが、日本語データセットで実施しようとなると少しだけ工夫が必要です。
今回は社内での匿名アンケートを使って実施していますので、出力内容についてはぼかしながらの説明となります。ご了承ください。
実行環境
環境:Python 3.10.9
データセット:社内匿名アンケートのテキスト列(短文)、4701件
必要なライブラリのインポート
from pyforest import *
import unicodedata
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
from umap import UMAP
from hdbscan import HDBSCAN
import requests
from fugashi import Tagger
from sklearn.feature_extraction.text import CountVectorizer
from bertopic.vectorizers import ClassTfidfTransformer
from bertopic.representation import KeyBERTInspired, MaximalMarginalRelevance, PartOfSpeechローカルの仮想環境(venv)内に必要なパッケージをインストールしています。
アンケートデータの読み込みと整形
questions_all = questions_path #アンケートデータのパス
def preprocess_text(text):
text = re.sub(r'\n+', ' ', text) # 改行をスペースに置換
text = ' '.join(text.split()) # 余分な空白を削除
text = re.sub(r'[^\w\s]', '', text) # 記号を削除
text = unicodedata.normalize('NFKC', text) # 全角・半角の統一
return text
# 「テスト」や「test」を含む行を除外
filtered_responses = questions_all[~questions_all[text_col].str.contains('テスト|test', case=False, na=False)]
# 欠損値処理
filtered_responses[text_col] = (
filtered_responses[text_col]
.astype(str) # 型を文字列に変換
.fillna('') # 欠損値を空文字で埋める
)
# 前処理
filtered_responses[text_col] = filtered_responses[text_col].apply(preprocess_text)
filtered_responses = filtered_responses[
(filtered_responses[text_col] != 'nan') &
(filtered_responses[text_col] != '')
]
cleaned_sentences = filtered_responses[text_col].reset_index(drop=True)
print(cleaned_sentences.head(10))前処理の参考になれば幸いです。基本的にはノイズとなりそうなものを除去していきます。不要な文字や記号の削除、空白や改行の統一、テキストの正規化あたりです。今回はお試しなので少しサボっています。
文章埋め込みの生成
embedding_model = SentenceTransformer("intfloat/multilingual-e5-base")
embeddings = embedding_model.encode(cleaned_sentences, show_progress_bar=True)
embeddings.shapeHugging Faceの埋め込みモデルを利用して、テキストをベクトルに変換しました。日本語モデルについての参考資料です。素晴らしい記事ですのでご参照ください。
マルチ言語のモデルも優秀とのことなので、Multilingual-E5がテーブルデータの分類モデルの初手LightGBM的なポジションになりつつあるらしいです。all-MiniLM-L6-v2を推奨していますが、日本語対応していないので、intfloat/multilingual-e5-baseっていうので試しています。
次元圧縮
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.5, metric='cosine', random_state=42)ここも色々と選ぶことができます。今回はお気に入りのUMAP(Uniform Manifold Approximation and Projection)を使用します。次元削減のアルゴリズムの多くは確率的挙動が含まれるので、再現性を担保するためにrandom_stateは固定しておきます。引数については少しでも見栄えがするようにカスタムしています。
n_neighbors(デフォルト: 15)、n_components(デフォルト: 2)、metric(デフォルト: 'euclidean')、min_dist(デフォルト: 0.1)、spread(デフォルト: 1.0)
ちょっとどんな感じか見てみました。

この時点でダメな感じしかありません。
トピック数の制御
hdbscan_model = HDBSCAN(min_cluster_size=20, metric='euclidean', cluster_selection_method='eom', prediction_data=True)HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise):データポイント間の密度の違いに基づいて、クラスターの形や密度が異なるデータセットに対して効果的にクラスタリングを行います。密度の高いクラスターのみを採用し、マイクロクラスターを制限しました。
トークナイザー
# stop_wordsはhttps://github.com/stopwords-iso/stopwords-isoから取得。
url = "https://raw.githubusercontent.com/stopwords-iso/stopwords-ja/master/stopwords-ja.json"
response = requests.get(url)
japanese_stop_words = response.json()
add_stop_words = [
'ただ', 'なので', 'まし', 'ござい', 'ござい まし',
]
japanese_stop_words = japanese_stop_words + add_stop_words
# Fugashiのトークナイザー関数
def fugashi_tokenizer(text):
tagger = Tagger()
return [word.surface for word in tagger(text)]
# CountVectorizerの初期化
vectorizer_model = CountVectorizer(tokenizer=fugashi_tokenizer, stop_words=japanese_stop_words, ngram_range=(1,1))ここも少し工夫しました。ストップワードも出力をみて足しています。ngram_rangenについても(1,1)でやっています。が・・・あまりうまくいきませんでした。改善の余地ありです。
トピック表現の作成
ctfidf_model = ClassTfidfTransformer()
# KeyBERT
keybert_model = KeyBERTInspired()
# Part-of-Speech
nlp = spacy.load("ja_core_news_trf")
pos_model = PartOfSpeech("ja_core_news_trf")
# MMR
mmr_model = MaximalMarginalRelevance(diversity=0.3)
# All representation models
representation_model = {
"KeyBERT": keybert_model,
"MMR": mmr_model,
"POS": pos_model
}あんまりわかっていないです。
Part-of-Speechのモデルは色々ありましたが、ja_core_news_trfで実施しました。こちらの素晴らしいブログでは、ja_ginza_electraが良いとのことでしたが、numpyの依存関係が解消されず今回の解析では使用を断念しました。
BERTopicモデルでのトピック抽出
topic_model = BERTopic(
language="japanese",
# Pipeline models
embedding_model=embedding_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
vectorizer_model=vectorizer_model,
representation_model=representation_model,
ctfidf_model=ctfidf_model,
# Hyperparameters
top_n_words=5,
verbose=True
)
# Train model
topics, probs = topic_model.fit_transform(cleaned_sentences, embeddings)結果の可視化
BERTopicでは色々な可視化方法が提供されています。
いくつか出力しましたので共有します。
# テーブル出力
display(topic_model.get_topic_info().style.set_properties(**{'text-align': 'left'}))
ちょっと意味ある感じでは分類できていませんが、このようにトピック内の単語を繋げてNameを出してくれます。今回はないですが、”-1”というTopicが出ます。これは"その他"って感じで未分類のものになります。これが多いことが問題になっていたりします。
また、チュートリアルではrepresentation_modelにGPT先生のAPIを使ったものが紹介されていましたが、うまくいかなかったので除外しています。
# 少し整形したデータフレームの出力
number_of_shown = 10
result_df = pd.DataFrame(
{
"text": cleaned_sentences,
"topic_no": topics,
"proba": probs,
}
)
result_df.head(number_of_shown)
このような出力も可能です。素晴らしいコメントが並んでいますが、BERTopicの結果はイマイチです。
# トピックバーグラフの出力
topic_model.visualize_barchart()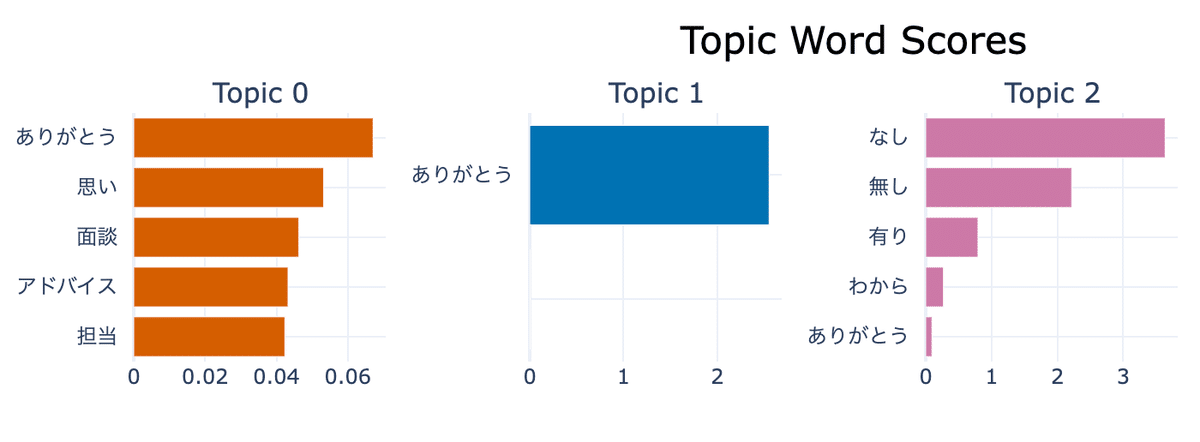
"ありがとう"で溢れかえってますね。
長文かつデータ量を増やすともう少しいい感じの出力になるのだと思います。チュートリアルの英語データセットのものも載せておきます。

# c-TF-IDFスコアのエルボープロットの出力
topic_model.visualize_term_rank()
あんまりわかっていないので、GPT先生にお願いします。
トピックは、代表的な単語の集まりで表現されます。
各単語にはc-TF-IDFスコアが付与されており、スコアが高いほどトピックを象徴する単語となります。単語はスコア順に並んでおり、順位が下がるほどスコアは低下します。
この関係を視覚化するには、x軸に単語の順位、y軸にc-TF-IDFスコアをプロットします。すると、スコアの低下が視覚的に確認でき、エルボー法を用いてトピックに含めるべき最適な単語数を決定できます。
# デンドログラムの出力
topic_model.visualize_hierarchy(custom_labels=True)
なんじゃこれ。
とにかく、本当に色々な形での出力が簡単にできます。
感想
日本語って大変です。短文で使用したのが間違いなのですが、結果はパッとしたものではありませんでした。データセットを変えて再度チャレンジします。
もう少しBERTopicについて理解を深めてからにはなりますが・・・。録音データを文字起こししてトピック解析を行い、解析結果を構造化データとして保存することで、録音データを整理・保管できないか試してみたいと考えています。これまで、使いづらかった長文テキストデータもどんどん活用していきたいです。
ベストプラクティスも参考になります。
興味があれば、ぜひBERTopicを試してみてください!
また、実際の使用事例なんかも共有いただけると参考になりますので、コメントください。