
[データ分析基盤構築記 ~DWH編~] 『よろずや』を作ってみた

はじめに
株式会社PREVENT、データエンジニアの俵です!
前回はETL基盤の構築についてご紹介しました。
今回は弊社DWH『よろずや』編です。
『よろずや』とは

『よろずや』は弊社における、一般的にはDWH(データウェアハウス)と呼ばれるデータベースを指します。
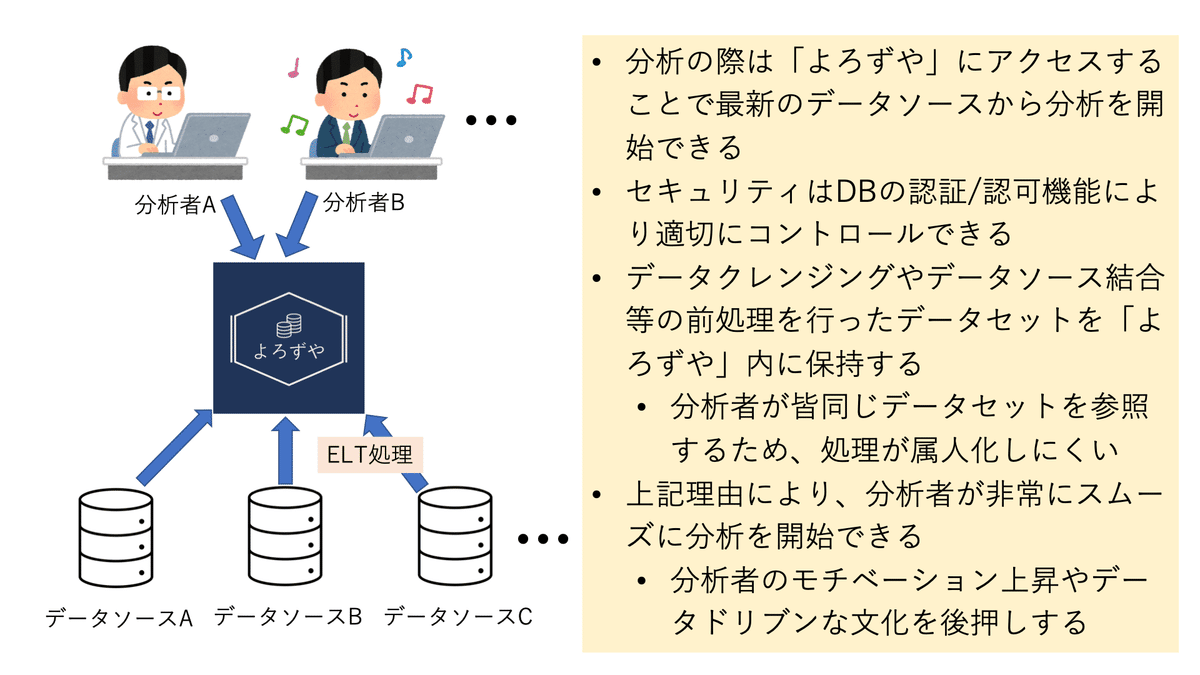
よろずやの目的は、社内の各所に散らばる全てのデータを一箇所に集約し、それらを分析に適した形に変換した上で分析者や可視化ツールなどに提供することです。
まさに万(よろず)のデータを扱い、万人に価値を提供することを期待して命名しました。
弊社では複数のCRMシステムを運用していますが、よろずや構築前はそれらのデータを分析者が横断的に分析する場合に多大な労力を消費していました(下図上段)。しかし、よろずや構築後は非常にスムーズで効率的な分析が可能になりました(下図下段)。

よろずやの実装
ここからはよろずやの実装についてご紹介します。
よろずやを構成するキーワードとして重要なものが、DWH, DM(データマート), そしてdbtです。
DWH, DM
よろずやはDWHであると冒頭で紹介しましたが、厳密にはDWH + DM、更にはDL(データレイク)的な要素も兼ね備えています。
DWHとDMは似て非なるものですが、その違いを簡単に下図に示しました。

これらの言葉の定義や解釈は人によって微妙に異なりますが、詳しく知りたい方は『実践的データ基盤への処方箋』や『AWSではじめるデータレイク: クラウドによる統合型データリポジトリ構築入門』といった書籍を読むことをお薦めします。

よろずやはこのDWH + DMの機能をAmazon RDS for PostgreSQL(以降Postgres)として実装しました。
Postgresを採用した背景としては、次のようなものがありました。
データソースにAWSのRDS PostgresやAurora Postgresが多いこと
CRM系のデータはデータサイズが小〜中規模程度であること
弊社分析者がRDBに慣れ親しんでおり、全員がSQLを習得していること
世界的にユーザーが多く信頼性の高いDBであること
ウィンドウ関数など分析用のクエリが充実していること
後述するdbtが公式にアダプタをサポートしていること
これらの背景をもとに実装にかかる工数やコストパフォーマンス、使いやすさ、拡張性等を考慮し、Postgresを採用しました。
ここでよろずやの概要を整理すると下図のようになります。
そしてDWHからDMを作成する際にデータ変換(データモデリング)を行うのがdbtです。

dbtとSQL
dbt (data build tool)はSQLを用いたデータモデリングツールです。
よろずやの各テーブルまたはビューをSQLでモデリングし、それらを組み合わせることで下図の様なDAGを作っていきます。

よろずやは非常に多くのデータソース(テーブル)から成るため、これらのモデルを無秩序に設計するとすぐに氾濫し、データの重複処理やそれに伴う
分析結果の不整合などに繋がります。
そこでよろずやでは、下図のように各モデルを3つの層に分類することでモデルの統制を図っています。

アドホック分析では主に1, 2層のモデルにアクセスし、ルーチン分析やダッシュボードツール、研究用データセット抽出については3層のモデルにアクセスすることで効率的なデータ分析を可能にしています。
モデリングについては現在も試行錯誤を重ねており、dbtvaultといった最新のモデリング手法にも注目しています。
dbtはリリースされて間もないサービスですが、SQLを用いることでモデルのGit管理を容易にし、またCTE(共通テーブル式)とJinja(テンプレートエンジン)を組み合わせることでモデルのコンポーネント化(DRYな記述)を可能にしました。
更にモデルのテストやDAGの可視化、シード、スナップショット機能等も相まってよろずやにとってなくてはならない一部となりました。

ここで余談にはなりますが、SQLはデータベース操作言語として1970年台に登場して以来非常に長い歴史を持ちます。
その集合論に根ざした設計思想は現代でも十分に通用することは言うまでもなく、データモデリング用途での利用も広がり、ますます魅力を増していると感じます。
流行り廃りのサイクルが非常に速いIT分野で50年近くも使われ、かつ最新の技術と組み合わさって現代でもなお存在感を増すSQLには、その設計思想の偉大さと温故知新を感じずにはいられません。
私自身もSQLやdbtの熱烈なファンであり、今後の発展や活用から目が離せません。
まとめ
Amazon RDS for PostgreSQL + dbtで弊社DWH『よろずや』を構築しました。
よろずやは日々拡大を続けており、データソースの数やユーザー、用途を増やしています。
今後更なる拡大や分析要件の高度化に伴い、既存の基盤では対応できなくなる日もいつかやってくると思われます。
そのような時にも決して現状に固執せず、ユーザーファーストな基盤を提供できるようデータエンジニアとして努めていきたいです。
特に現在はモダンデータスタック(主にクラウドサービスで構成されるデータ分析基盤)の戦国時代と呼ぶに相応しい状況であり、日夜新しいサービスが登場しています。
数多のサービスの本質を理解し、自社の状況に応じて最適なものを選定する目利きもデータエンジニアの素養として今後ますます重要になってくると思うので、最新技術のキャッチアップは欠かさずに続けていこうと思います。
生き残る種とは、最も強いものではない。
最も知的なものでもない。
それは、変化に最もよく適応したものである。
おわりに
今回は弊社DWH『よろずや』の目的や実装についてご紹介しました!
よろずやの役割や目指す姿についてご理解頂けたでしょうか?
次回はいよいよよろずやを元にして探索的データ分析やデータ可視化を行うための要であるBI・ダッシュボード構築についてご紹介したいと思います!
[データ分析基盤構築記 ~BI・ダッシュボード編~] に続く